Computing Receptive Fields of CNNs
Attribution
This note is adapted from:
André Araujo, Wade Norris, Jack Sim, “Computing Receptive Fields of Convolutional Neural Networks”, Distill (2019).
DOI: 10.23915/distill.00021 — https://distill.pub/2019/computing-receptive-fields
Licensed under CC-BY 4.0.
Changes: restructuring into Markdown format, addition of custom explanations/examples.
Overview
The following discussion focuses on fully-convolutional neural networks (CNNs), deriving both the size of the receptive field and the position of output feature receptive fields relative to the input signal.
Note
The derivations are broad enough to apply to any type of input signal to convolutional neural networks, though images are used as the recurring example, with references to modern computer vision architectures where appropriate.
Road Map
First:
- Closed-form expressions are derived for the case where the network has a single path from input to output (as in AlexNet or VGG).
Next:
- The more general case of arbitrary computation graphs with multiple paths from input to output (as in ResNet or Inception) is discussed.
Last
- Potential alignment issues that may arise in this setting are then considered, and an algorithm is presented to compute the receptive field size and locations.
Problem setup
Let’s consider a fully-convolutional neural network (CNN) with layers, .
In addition:
- The feature map is defined as the output of the -th layer, with height , width , and depth .
- The input image is denoted by .
- The final output feature map corresponds to .
Focus on case
For simplicity, the following analysis focuses on the dimensions along a single axis (e.g., height or width) by considering -dimensional input signals and feature maps. For higher-dimensional signals (e.g., images), the derivations can be applied to each dimension independently. Similarly, the figures depict -dimensional depth, since this does not affect the receptive field computation.
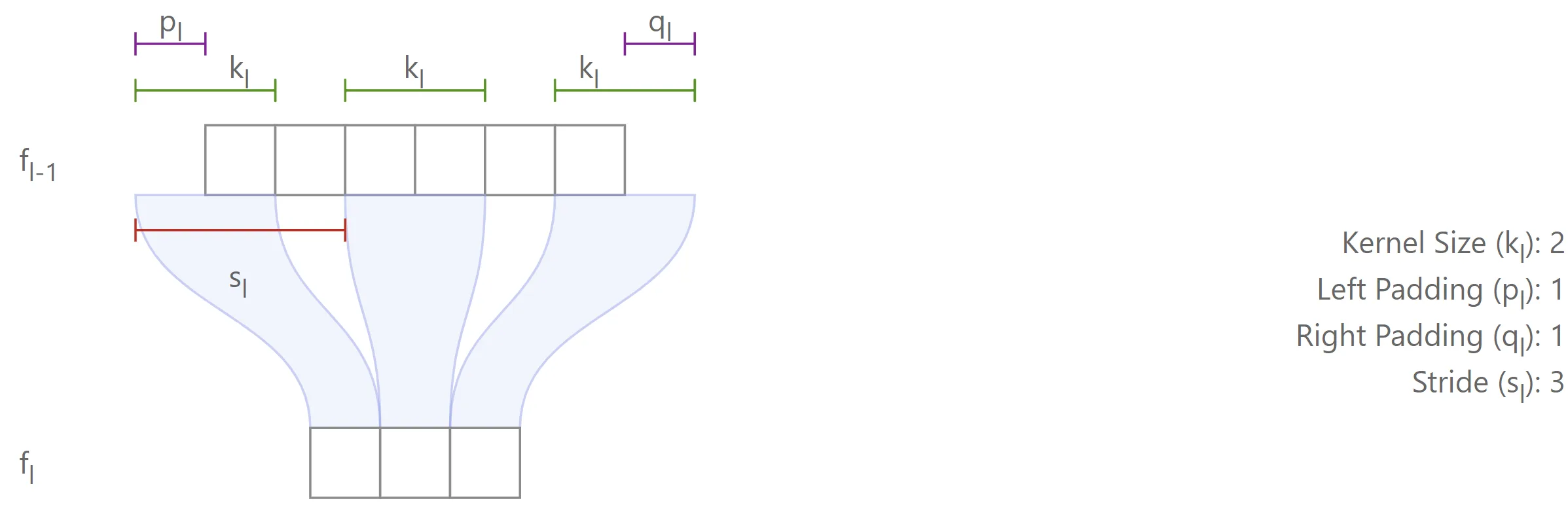
The spatial configuration of each layer is parameterized by four variables, as illustrated in the figure below:
- : kernel size (positive integer)
- : stride (positive integer)
- : padding applied to the left side of the input feature map (non-negative integer).1
- : padding applied to the right side of the input feature map (non-negative integer)
Note
Only layers whose output features depend locally on input features are considered: e.g., convolution, pooling, or elementwise operations such as non-linearities, addition and filter concatenation. These are commonly used in state-of-the-art networks. Elementwise operations are defined to have a “kernel size” of , since each output feature depends on a single location of the input feature maps.
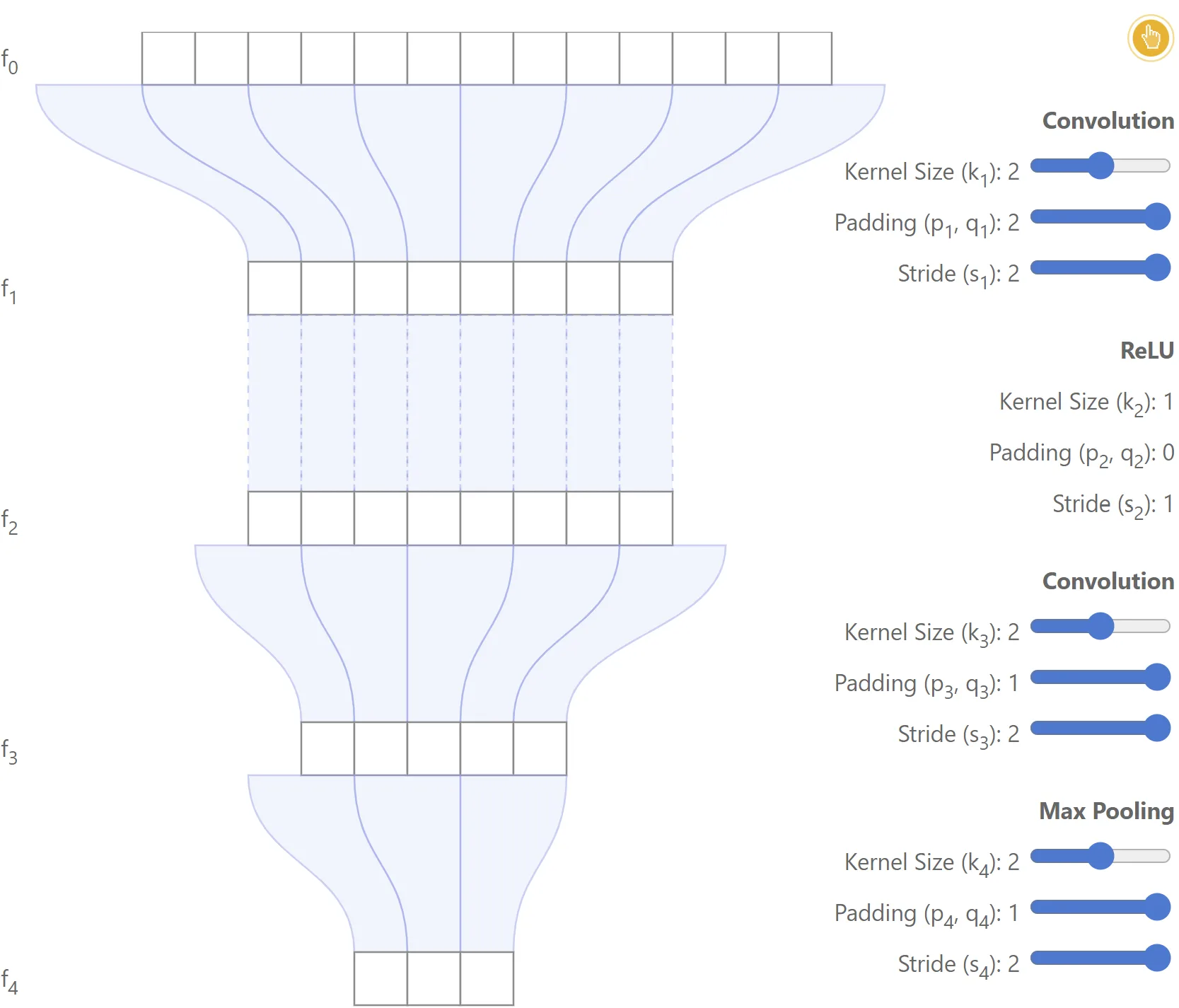
The notation is further illustrated with the simple network shown below.
Example
In this case, , and the model consists of a convolutional layer, followed by a ReLU, a second convolutional layer, and a max-pooling operation.2
 |  |
|---|---|
 | 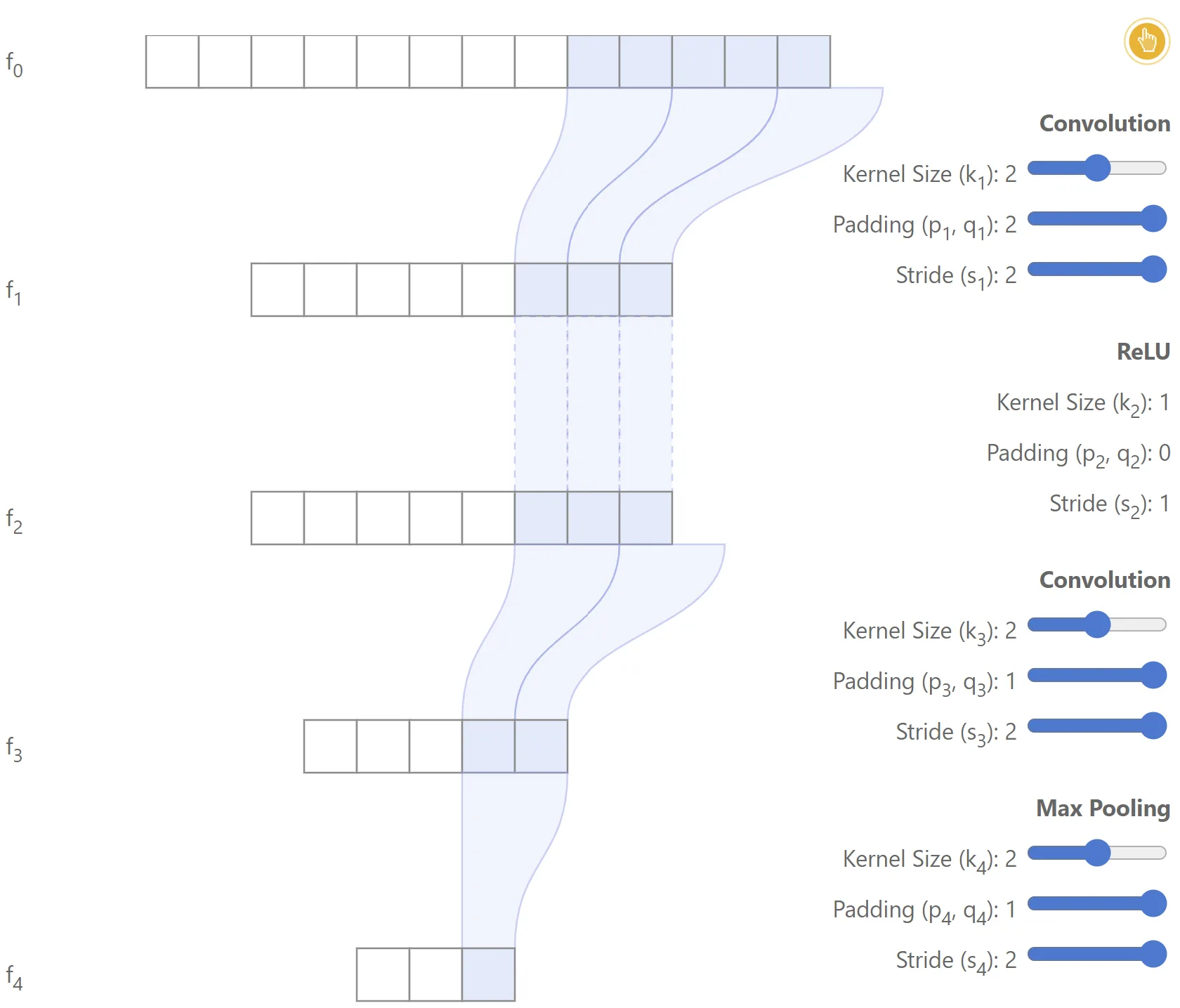 |
Single-path networks
In this section, recurrence and closed-form expressions are computed for fully convolutional networks with a single path from input to output (e.g., AlexNet or VGG).
Computing receptive field size
Definition of
is defined as the size of the receptive field of the final output feature map with respect to the feature map .
In other words, corresponds to the number of features in the feature map which contribute to generate a single feature in . Note that .
Example
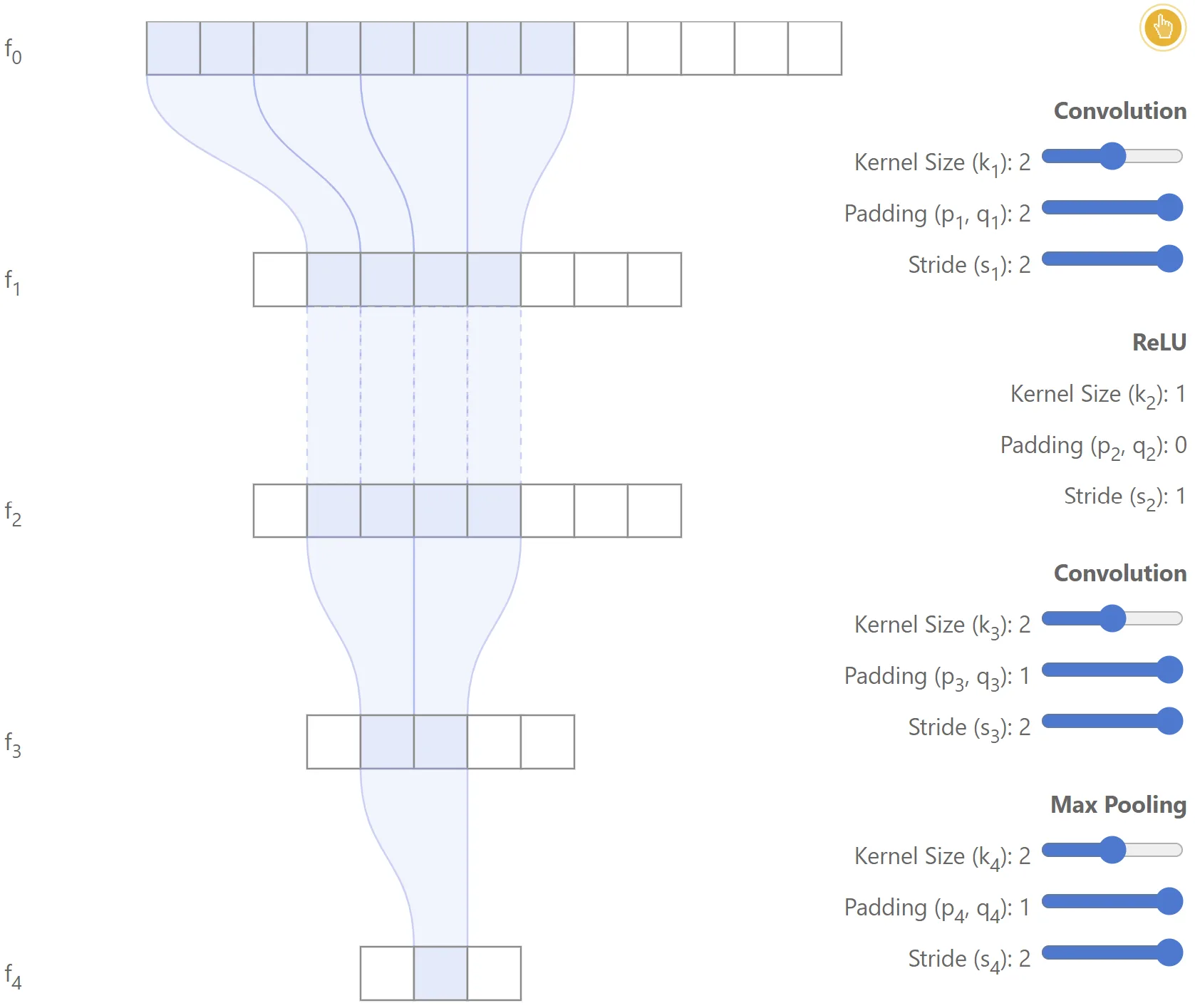
As a simple example, let’s consider layer , which takes the features as input and produces as output. An illustration is shown below:
It is easy to see that features of can influence a single feature of , since each feature of is directly connected to features of . Consequently, .

Computing given
Let’s consider now the more general case where is known and is to be computed. Each feature of is connected to features of
Case
First, consider the situation where : in this case, the features in will cover
features in .
This is illustrated in the figure below, where (highlighted in red).
The first term (in green) covers the entire region from which the features originate, but it also covers excess features (in purple), which must therefore be subtracted.3
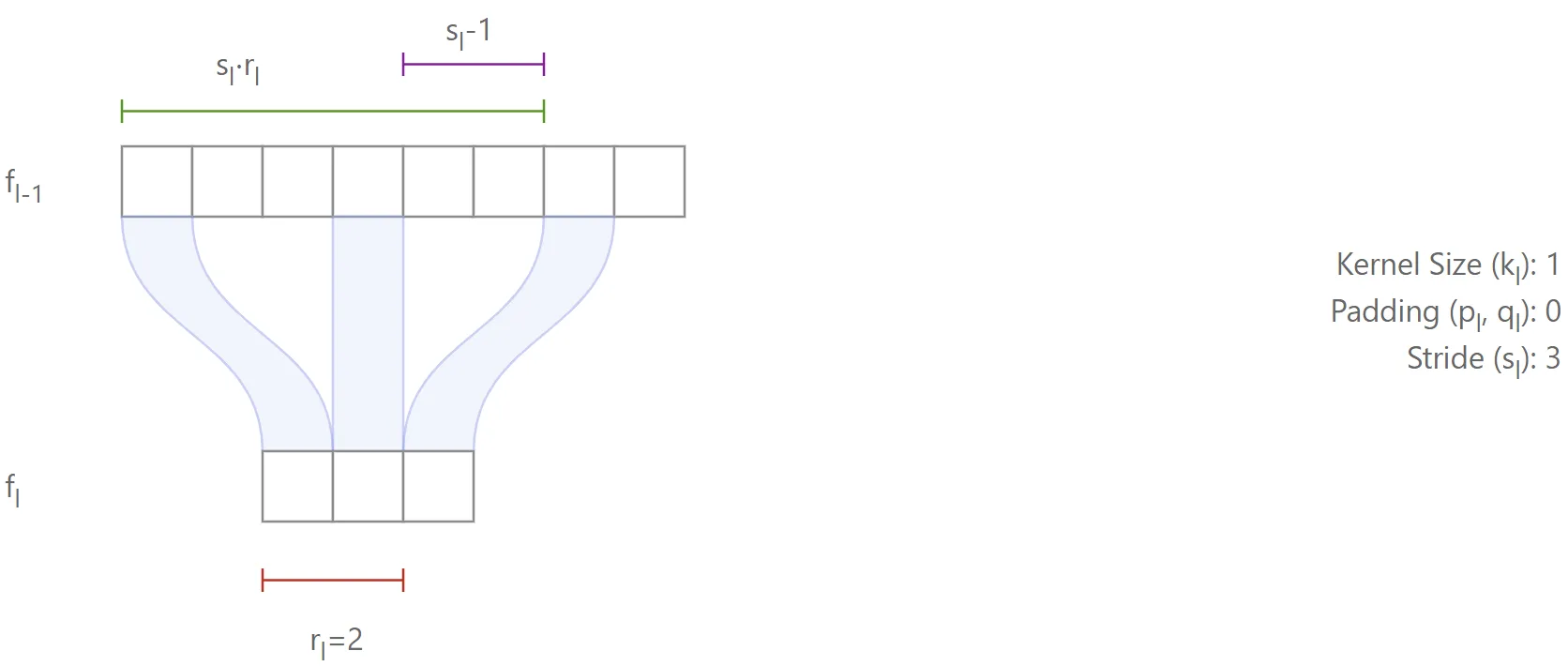
Case
When , the receptive field expands by additional features, which will cover those from the left and the right of the region. For example:
- With a kernel size of 5 (), there are 2 extra features on each side, for a total of 4.
- With a kernel size of 4 (), the distribution is not symmetric (e.g., 1 feature on the left and 2 on the right), but the total number of additional features is still .
Thus, whether is odd or even, the left and right extensions always add up to in total.4
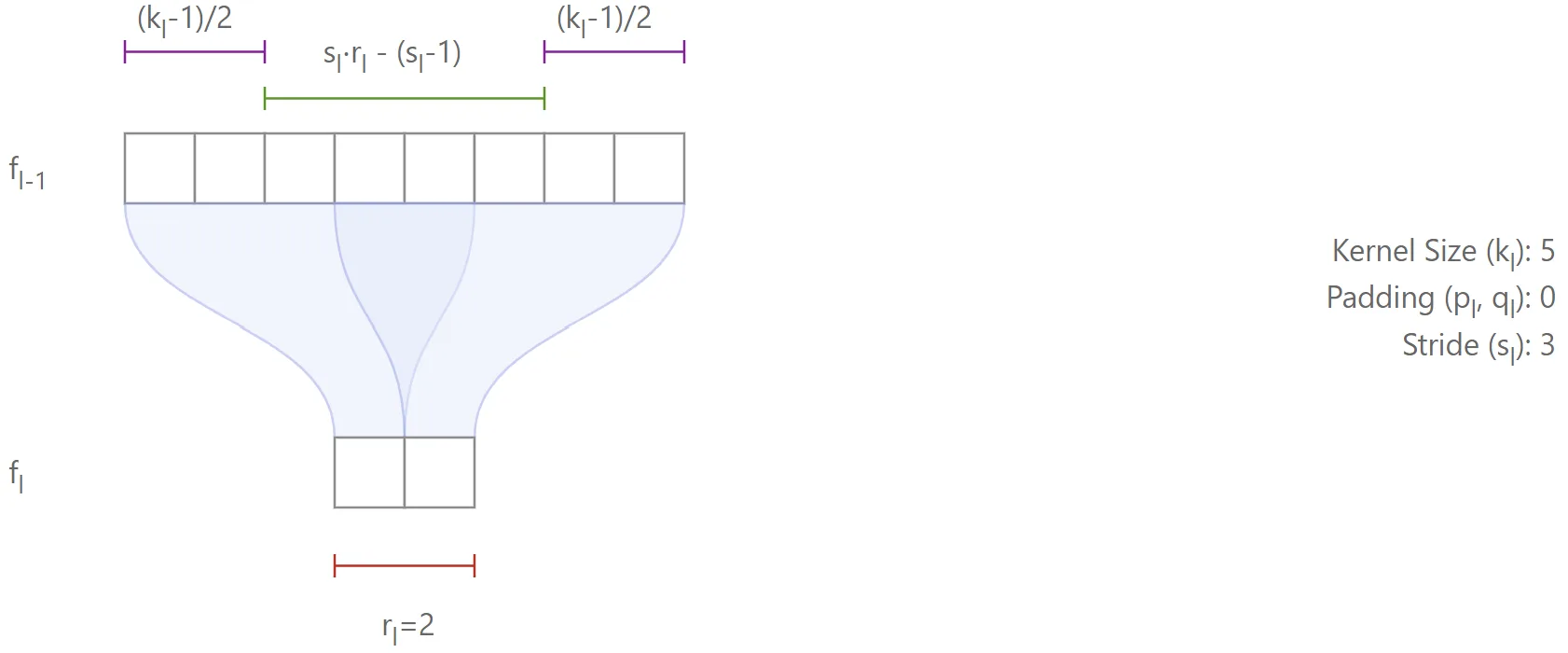
This yields the general recursive equation (first-order, non-homogeneous, with variable coefficients):
This equation can be used in a recursive algorithm to compute the receptive field size of the network, . However, more can be done: the recursive equation can in fact be solved to obtain an explicit solution as a function of the values of and :
This expression has an intuitive meaning, as can be seen by considering a few special cases. For example:
- if all kernels have size , the receptive field will naturally also have size 1.
- if all strides are equal to , then the receptive field is simply the sum of across all layers, plus , which is easy to verify.
- if instead the stride is greater than for a particular layer, the receptive field increases proportionally for all lower layers.
Proof of the formula for the receptive field size
The first trick to solve (1) is to multiply it by :
Define , and note that (since is the neutral element for multiplication), so . Using this definition, (14) can be rewritten as:
Now, summing from to :
Note that and . Therefore, it’s possible to compute:
where the last step is done by a change of variables for the right term.
Finally, rewriting (17), we obtain the expression for the receptive field size of a CNN on the input image, given the parameters of each layer:
Note
Finally, note that padding does not need to be taken into account in this derivation.
Padding only introduces artificial cells (e.g., zeros) at the borders of the input, which may be included in the receptive field of boundary features.
However, it does not change the receptive field size, since this is determined exclusively by kernel sizes and strides.
In other words, padding affects which pixels are used at the borders, but not how many input positions are covered in total.
 |
|---|
Computing receptive field region in input image
While it is important to know the size of the region that generates one feature in the output feature map, in many cases it is also critical to precisely localize the region that generated a feature.
Question
For example, given feature , what is the region in the input image that generated it?
This is addressed in this section.
Let’s denote and the left-most and right-most coordinates (in ) of the region used to compute the desired feature in .
Note
In these derivations, the coordinates are zero-indexed (i.e., the first feature in each map is at coordinate ).
Note that corresponds to the location of the desired feature in .
Example
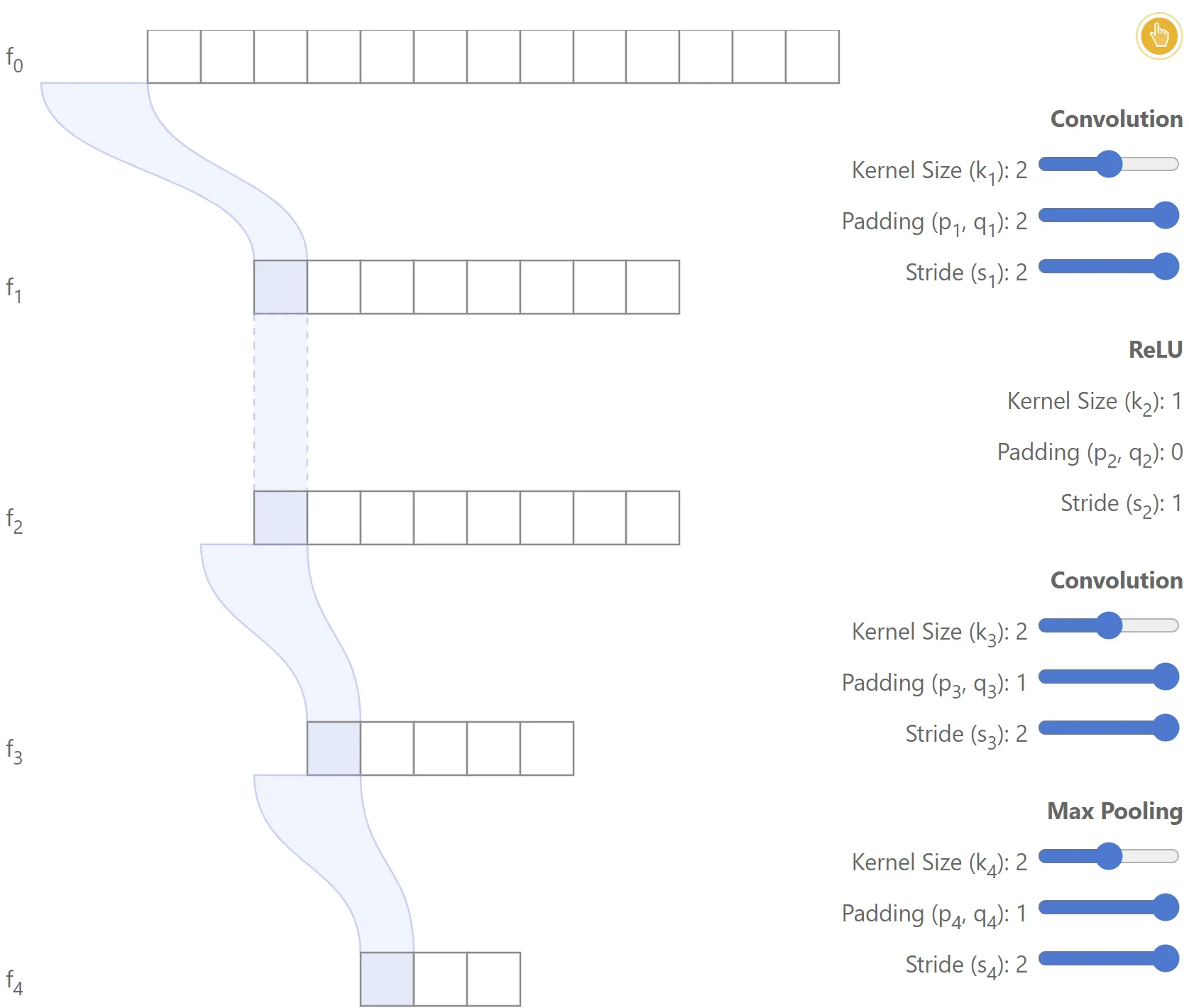
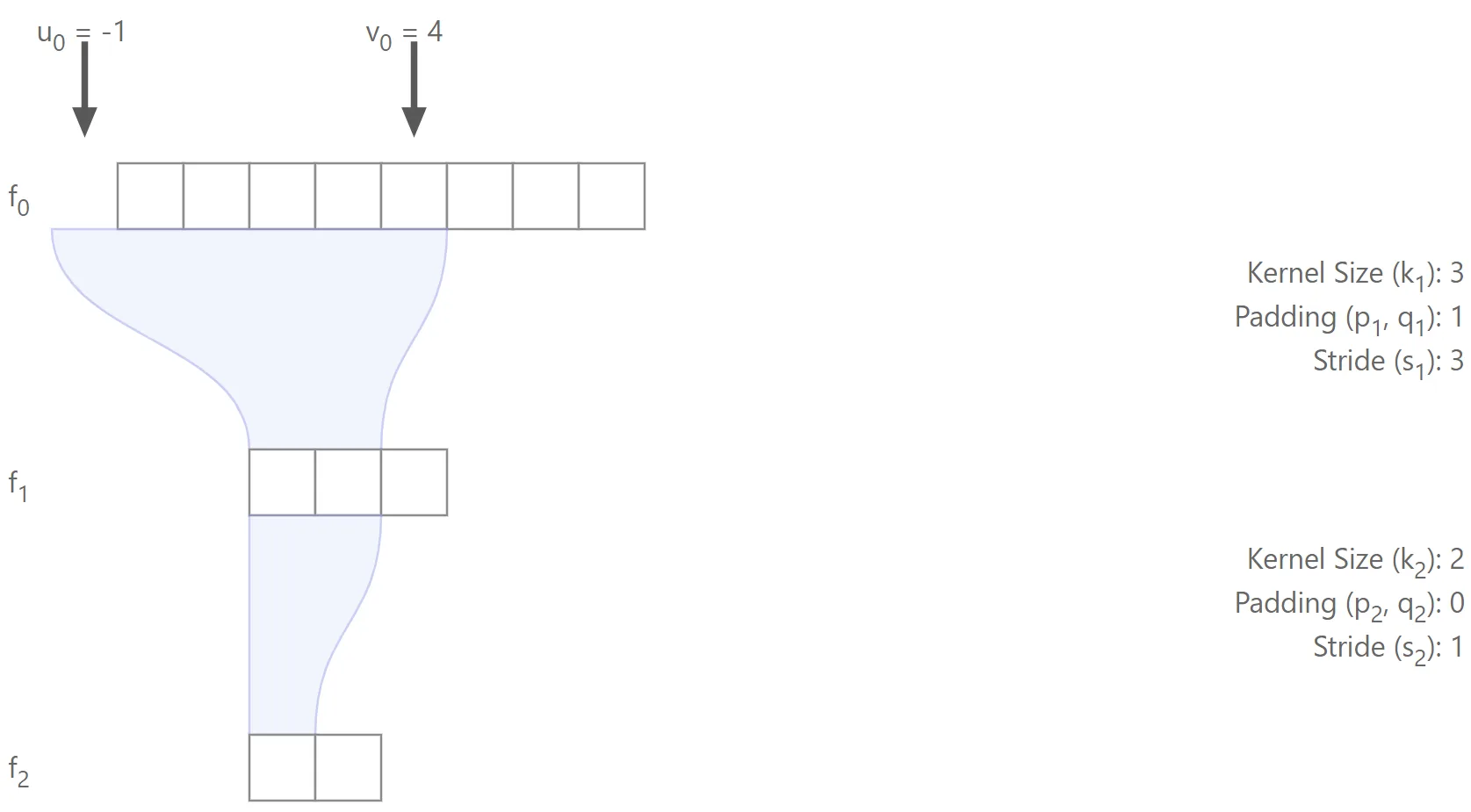
The figure below illustrates a simple 2-layer network, where it’s highlighted the region in used to compute the first feature from .
Note that in this case the region includes some padding.In this example:
- ,
- ,
Question
Let’s begin by asking: given , is it possible to compute ?
Consider the simple case where (this corresponds to the first position in ). In this case, the left-most feature will clearly be located at , since the first feature will be generated by placing the left end of the kernel over that position.
If (the second feature), the left-most position is ; for , one obtains , and so on. In general:
where the computation of differs only by the addition of , which is needed since in this case we want to find the right-most position.
Note that these expressions are very similar to the recursion derived for the receptive field size . As before, one could implement a recursion over the network to obtain for each layer; however, one can also solve directly for and obtain closed-form expressions in terms of the network parameters:
Solving the recursive equations: receptive field region
The derivations are analogous to those used to solve (1).
Let’s consider the computation of . First, multiply (3) by :Define , and rewrite (19) as:
Summing from to :
Note that and . Therefore:
This yields the left-most feature position in the input image as a function of the padding and stride applied in each layer of the network, and of the feature location in the output feature map .
And for the right-most feature location :
Note
Note that, unlike (5), this expression also depends on the kernel sizes of each layer.
Relation between receptive field size and region
It may be observed that the receptive field size should be directly related to and . Indeed, it is straightforward to show that . In particular, this implies that can be rewritten as:
Effective stride and padding
To compute and in practice, it is convenient to define two variables that depend only on the paddings and strides of the different layers:
- Effective stride:
represents the stride between a given feature map and the output feature map .
- Effective padding:
represents the padding between a given feature map and the output feature map .
With these definitions, equation can be rewritten as:
Note the resemblance between and . By using and , one can compute the locations for the feature map given the location at the output feature map .
When computing feature locations for a given network, it is useful to precompute three variables: . Using these three, is obtained from and from . This yields the mapping from any output feature location to the input region which influences it.
It is also possible to derive recurrence equations for the effective stride and effective padding. It is straightforward to show that:
These expressions will be handy when deriving an algorithm to solve the case for arbitrary computation graphs, presented in the next section.
Center of receptive field region
Important
It is also interesting to derive an expression for the center of the receptive field region which influences a particular output feature.
This can be used as the location of the feature in the input image
Let’s define the center of the receptive field region for each layer as:
Given the above expressions for , , and , follows immediately (recalling that ):
This expression can be compared to to observe that the center is shifted from the left-most pixel by , which makes sense. Note that the centers of the receptive fields for different output features are spaced by the effective stride , as expected.
It is also worth noting that if for all layers , the centers of the receptive field regions for the output features will be aligned to the first pixel of the image and located at:
(in this case all must be odd).
Other network operations
Dilated (atrous) convolution
Dilations introduce “holes” in a convolutional kernel. While the number of weights is unchanged, they are no longer applied to spatially adjacent samples. Dilating a kernel by a factor introduces a stride of between the sampled positions. Thus, the spatial span of a kernel of size becomes . The derivations above can be reused by replacing with for any layer that uses dilation.
Upsampling
Often implemented via interpolation (e.g., bilinear, bicubic, nearest neighbor), which yields an equal or larger receptive field since each output depends on one or more input features. For receptive-field computations, treat an upsampling layer as having an effective kernel size equal to the number of input features used to produce one output feature.
Separable convolutions
Convolutions separable in spatial or channel dimensions have the same receptive-field properties as their equivalent non-separable convolutions. For example, a depth-wise separable convolution has an effective kernel size of for receptive-field computation.
Batch normalization
At inference time, batch normalization is a feature-wise operation and does not alter the network’s receptive field. During training, however, its parameters are computed from all activations of a layer, so its receptive field is the entire input image.
Arbitrary computation graphs
Most state-of-the-art convolutional neural networks (e.g., ResNet and Inception) rely on models where each layer may have more than one input, which means that there might be several different paths from the input image to the final output feature map. These architectures are usually represented using directed acyclic computation graphs, where the set of nodes represents the layers and the set of edges encodes the connections between them (feature maps flow through the edges).
The computation presented in the previous section can be used for each of the possible paths from input to output independently. The situation becomes trickier when one wants to take into account all different paths to find the receptive field size of the network and the receptive field regions which correspond to each of the output features.
Alignment issues
Danger
The first potential issue is that one output feature may be computed using misaligned regions of the input image, depending on the path from input to output. Also, the relative position between the image regions used for the computation of each output feature may vary.
As a consequence, the receptive field size may not be shift-invariant.
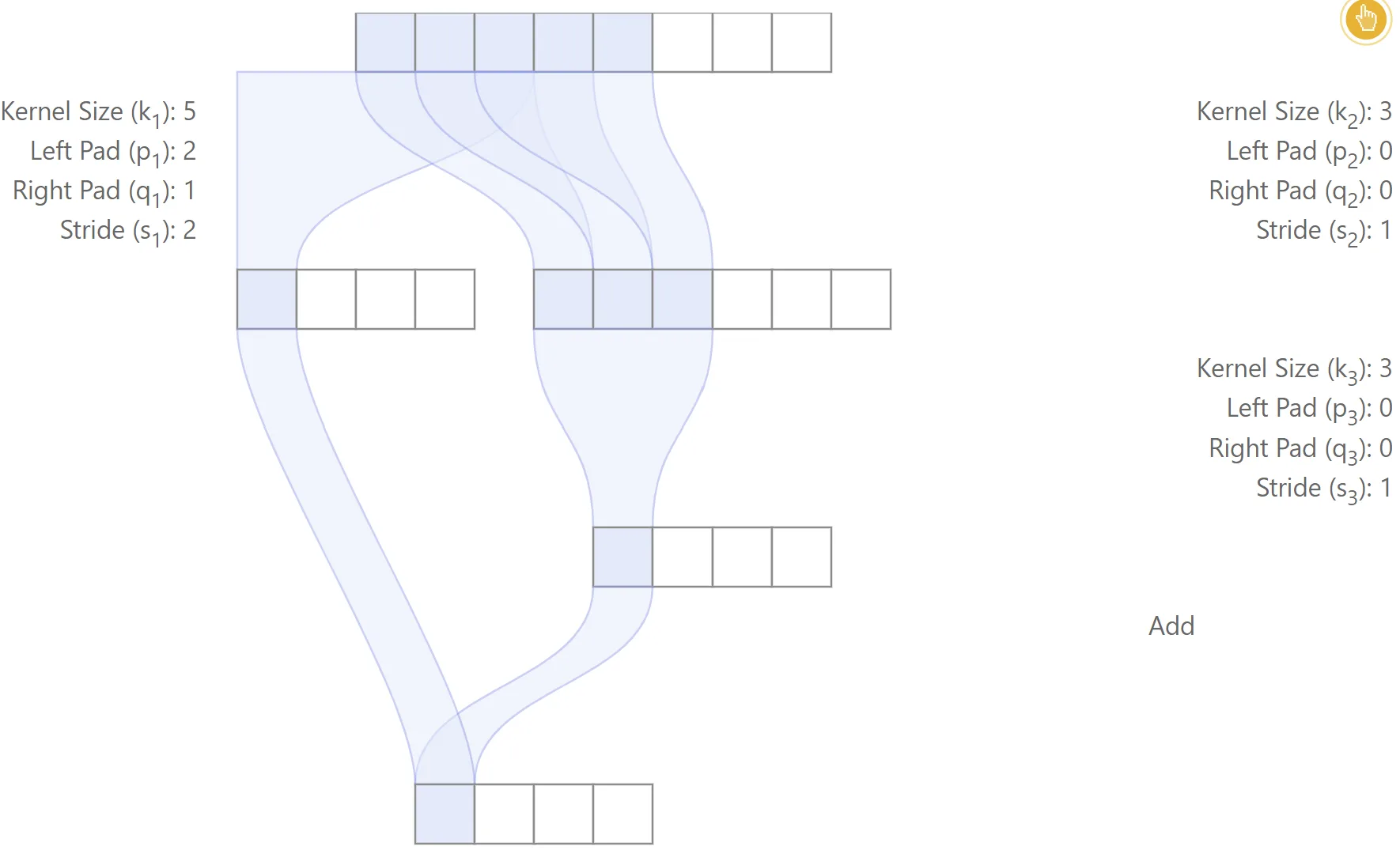
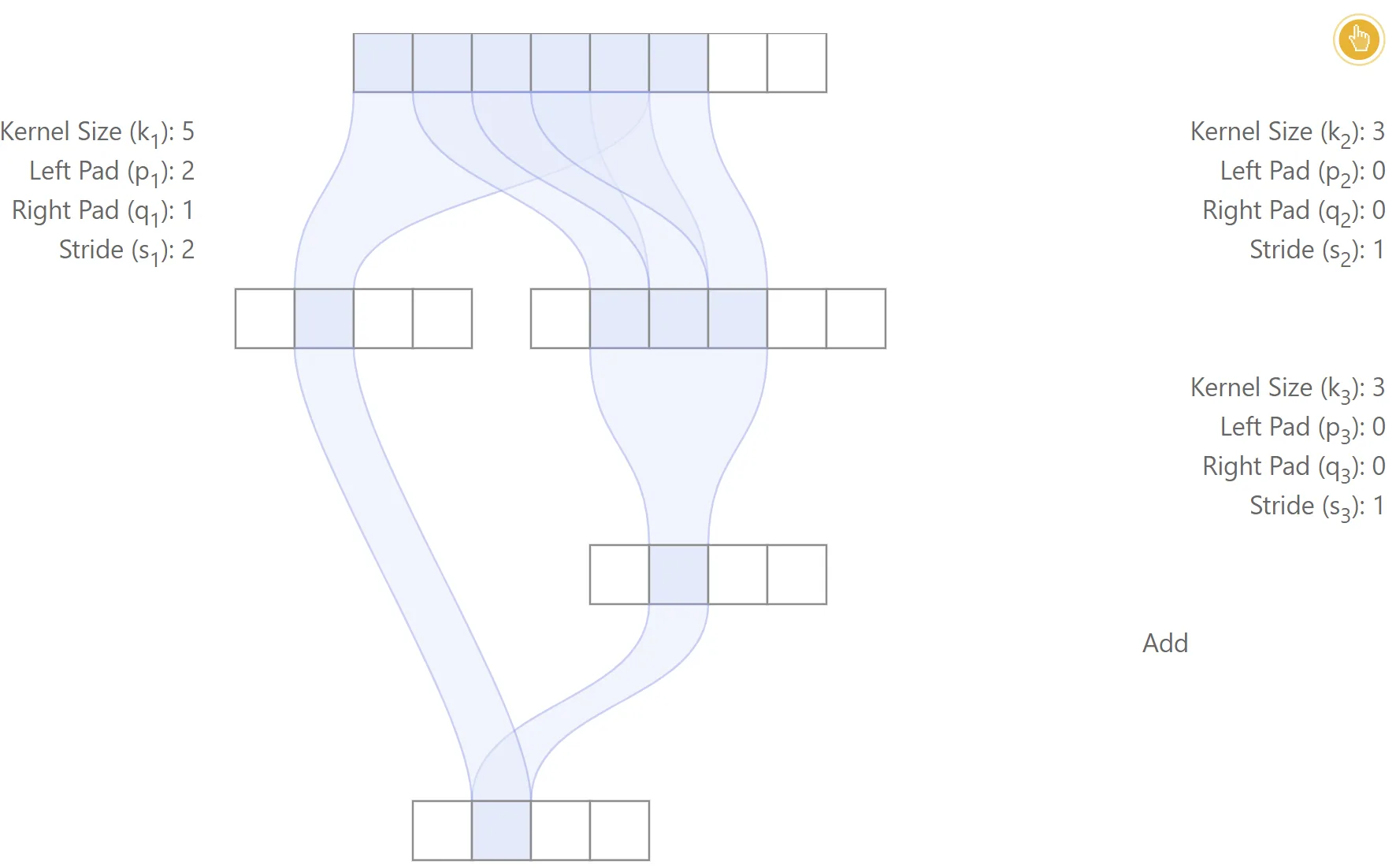
This is illustrated in the figure below with a toy example, in which case the centers of the regions used in the input image are different for the two paths from input to output.
Misaligned network
In this example, padding is used only for the left branch. The first three layers are convolutional, while the last layer performs a simple addition. The relative position between the receptive field regions of the left and right paths is inconsistent for different output features, which leads to a lack of alignment
Also, note that the receptive field size for each output feature may be different. For the second output feature from the left, input samples are used, while only are used for the third output feature. This means that the receptive field size may not be shift-invariant when the network is not aligned.
 |  |
|---|---|
 | 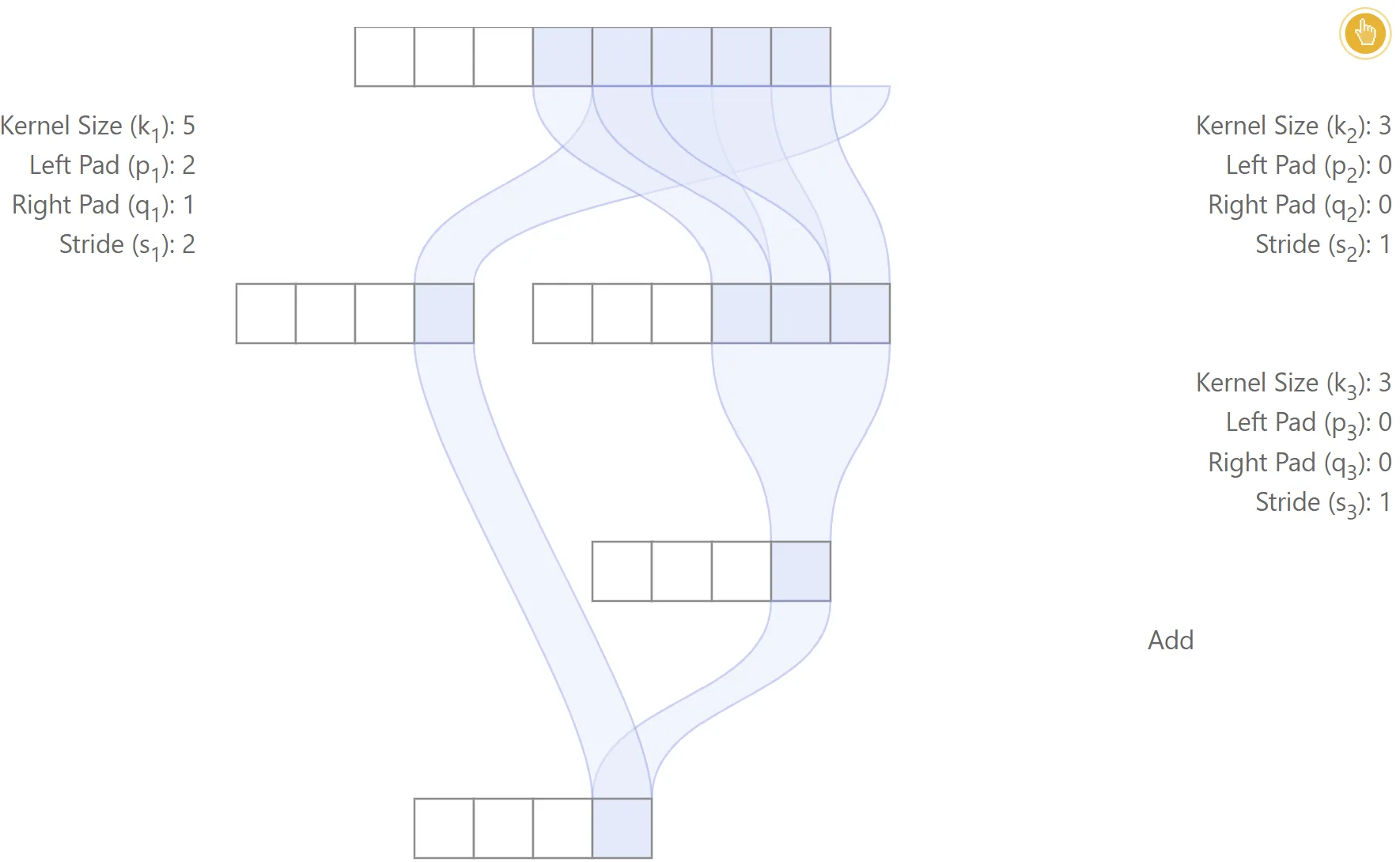 |
Note
For many computer vision tasks, it is highly desirable that output features be aligned: “image-to-image translation” tasks (e.g., semantic segmentation, edge detection, surface normal estimation, colorization, etc), local feature matching and retrieval, among others.
Important
When the network is aligned, all different paths lead to output features being centered consistently in the same locations. All different paths must have the same effective stride. It is easy to see that the receptive field size will be the largest receptive field among all possible paths. Also, the effective padding of the network corresponds to the effective padding for the path with largest receptive field size, such that one can apply , to localize the region which generated an output feature.
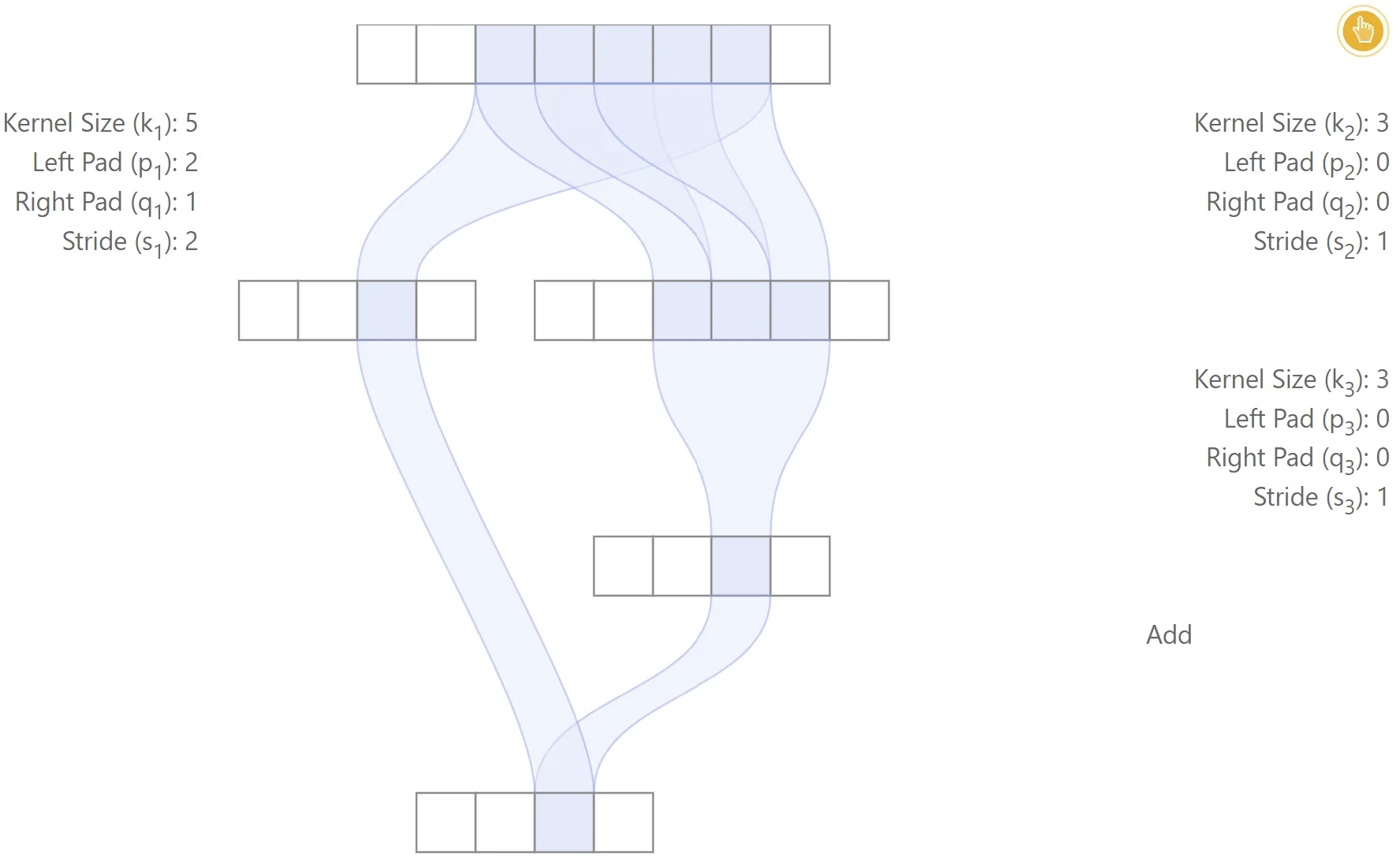
Aligned network
The figure below gives one simple example of an aligned network. In this case, the two different paths lead to each output feature being centered at the same locations. The receptive field size is , the effective stride is and the effective padding is .
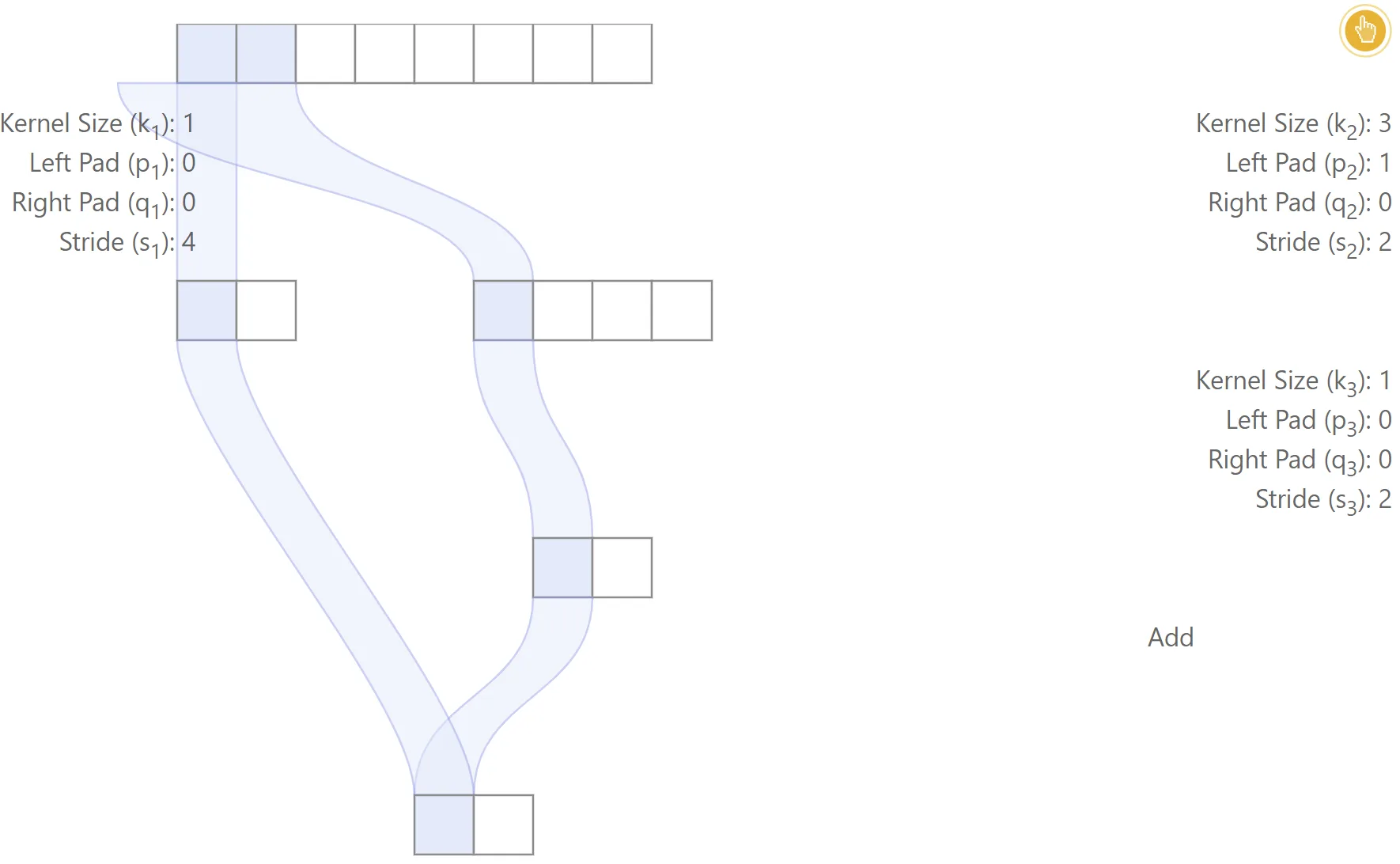 | 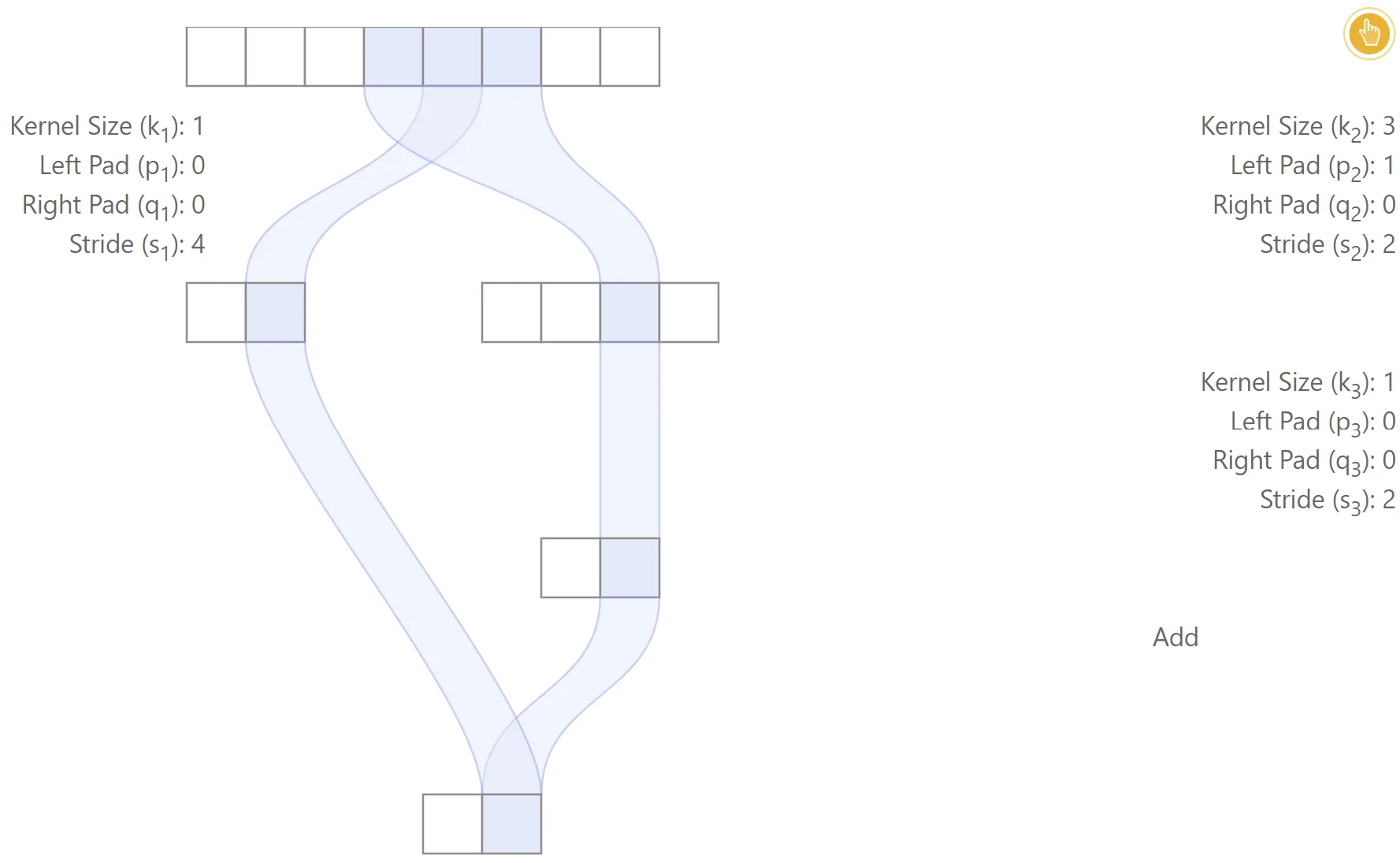 |
|---|
Alignment criteria
More precisely, for a network to be aligned at every layer, we need every possible pair of paths and to have for any layer and output feature . For this to happen, we can see from that two conditions must be satisfied:
for all , , .
Footnotes
-
A more general definition of padding can also be considered: negative padding, interpreted as cropping, can be used in the following derivations without any modification. To keep the presentation concise, the discussion focuses exclusively on non-negative padding. ↩
-
The first output feature of each layer is computed by placing the kernel at the left-most position of the input, including padding, This convention is used by all major Deep Learning libraries. ↩
-
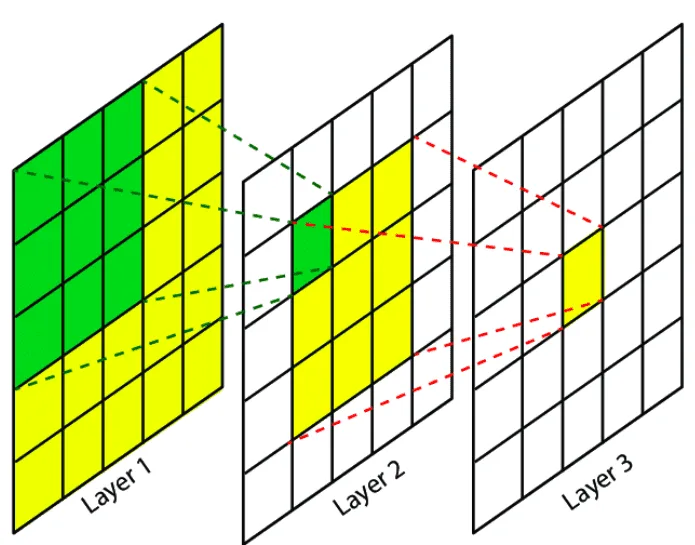
As shown in the illustration below, in some cases the receptive field region may contain “holes”, meaning that some of the input features may be unused for a given layer. ↩
-
Due to border effects, note that the size of the region in the original image which is used to compute each output feature may be different. This happens if padding is used, in which case the receptive field for border features includes the padded region. Later in the article, we discuss how to compute the receptive field region for each feature, which can be used to determine exactly which image pixels are used for each output feature. ↩