Input Multi-Canale
Sia l’input al layer convoluzionale:
- : numero di canali di input (e.g. 3 per immagini RGB)
- : dimensioni spaziali
Per ogni canale di uscita , la rete apprende un filtro convoluzionale:
dove ogni è un kernel 2D dedicato al canale di input .
Questi kernel vengono impilati per formare un blocco 3D di pesi.
L’attivazione del canale di uscita è calcolata come:
dove:
- : kernel 2D associato alla coppia formata dal canale di output -esimo e dal canale di input -esimo
- : k-esimo canale dell’input
- : operazione di convoluzione 2D
- : bias associato al canale di uscita
- : funzione di attivazione (es. ReLU)
Important
Per ogni :
- il prodotto restituisce una matrice 2D (una feature map parziale);
- variando , si ottengono matrici 2D;
- queste matrici vengono sommate tra loro elemento per elemento;
- infine si aggiunge il bias (broadcasted su tutta la matrice) e si applica la funzione di attivazione .
📌 Il risultato finale è quindi una matrice 2D: la feature map completa corrispondente al canale di uscita .
Ripetendo il processo per tutti i si ottiene:
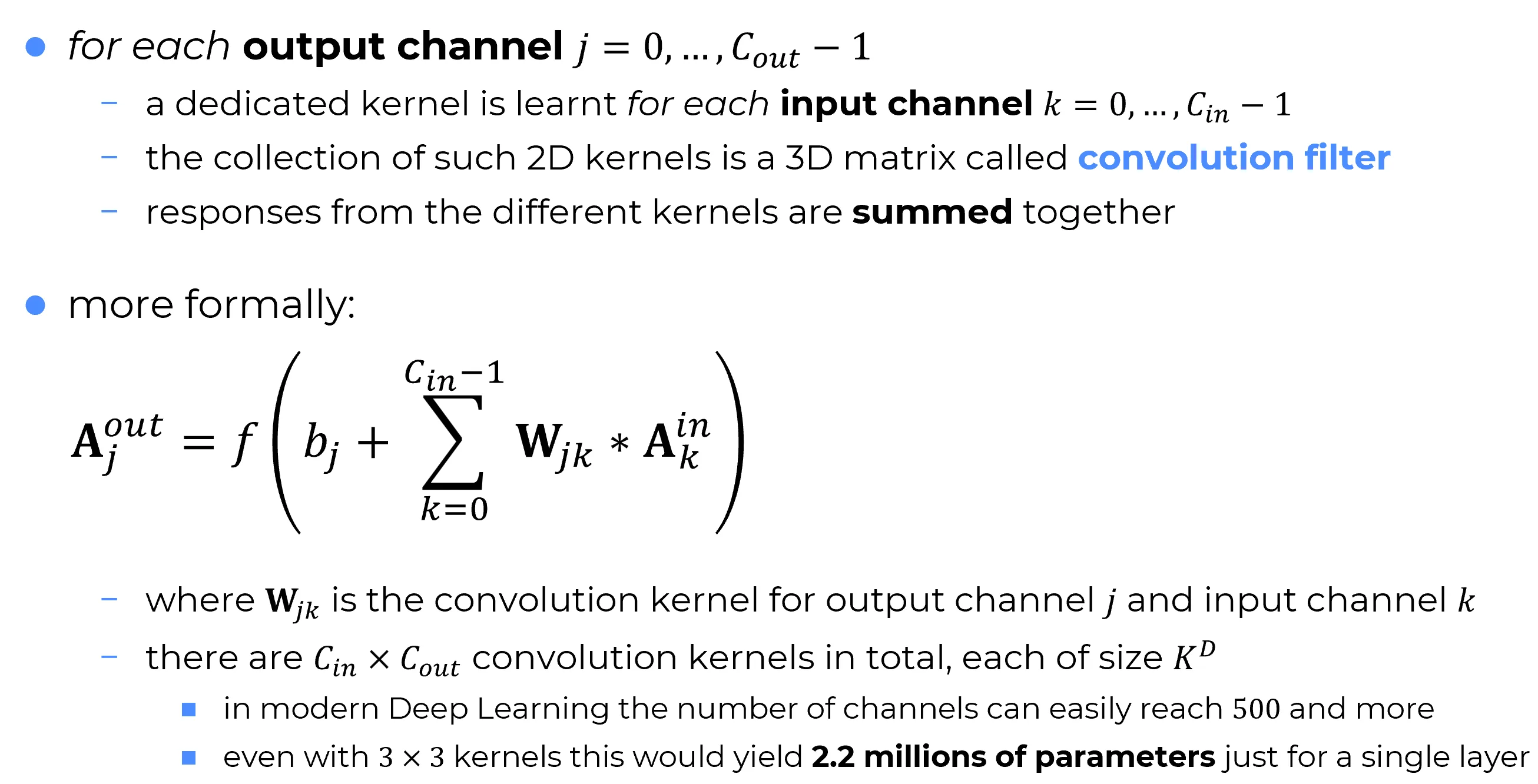
📌 Nota
Ogni filtro convoluzionale è una matrice tridimensionale di pesi,
composta da kernel 2D impilati, e produce una sola feature map di uscita.In totale, un layer convoluzionale apprende filtri indipendenti,
ciascuno responsabile di una mappa distinta nell’output.
Important
Le CNN possono essere riguardate come estrattori generali di features da immagini/segnali: esse apprendono milioni di features extractors per ogni layer, ciascuno responsabile della rilevazione di specifici pattern nei dati.
Nella figura riportata, si osserva che le CNN esibiscono milioni di parametri anche in un singolo layer convoluzionale. Analogamente, anche gli MLP possono contenere un numero molto elevato di parametri, nell’ordine di , o persino . Sebbene anche nelle CNN si raggiungano valori simili, i loro parametri sono impiegati per apprendere features differenti.
In questo senso, le CNN sono vere e proprie feature representation learners, il che le distingue profondamente dagli MLP, i quali non possiedono un meccanismo esplicito per l’estrazione gerarchica delle caratteristiche.