Nel caso di convoluzione 3D, l’intuizione si estende a blocchi 3D:
- Per ogni canale l’input è un blocco tridimensionale: profondità , altezza , larghezza
- Se ci sono canali, si hanno blocchi 3D, uno per ciascun canale
- Ogni rappresenta il -esimo canale di input come un volume 3D
Fissando un canale di output :
- Il filtro convoluzionale usato dalla rete è uno stack di kernel 3D, ognuno di dimensione
- Questi kernel scorrono nei rispettivi blocchi di input
Calcolo del valore in uscita
Per ogni posizione spaziale nella mappa di output del canale , il valore viene calcolato nel seguente modo:
- Per ogni canale dell’input:
-
Si applica il kernel 3D sovrapponendolo al volume tridimensionale in modo che il centro del kernel cada sulla posizione
-
Si estrae quindi una regione cubica di dimensione dal -esimo canale dell’input
-
Questo significa che la finestra del kernel scorre lungo le tre dimensioni , e a ogni passo raccoglie un blocco locale dell’input allineato con i pesi del kernel
-
Si calcola infine il prodotto scalare elemento per elemento tra questa regione e il kernel :
-
- Si sommano i contributi di tutti i canali :
- Si aggiunge il bias e si applica la funzione di attivazione :
Note
Ogni valore rappresenta uno scalare all’interno della mappa tridimensionale del canale di uscita .
Formula esplicita: versione element-wise
Esplicitando completamente la convoluzione 3D rispetto agli indici:
- : scorre la profondità
- : scorre le righe (altezza)
- : scorre le colonne (larghezza)
- , , : padding lungo ciascun asse
Il kernel convoluzionale viene sovrapposto a un blocco tridimensionale per ogni canale, ed esegue un prodotto scalare canale per canale.
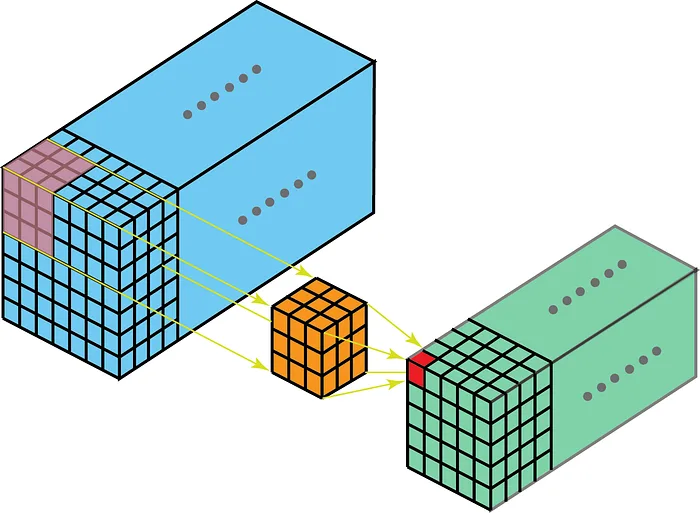
🔢 Esempio concreto: convoluzione 3D con più canali
Si supponga di avere:
- Un input tridimensionale con canali
- Ogni canale è un volume , con assi:
- : profondità (fronte ↔ retro)
- : larghezza (sinistra → destra)
- : altezza (alto → basso)
- Un filtro convoluzionale per il canale di output , composto da:
- Uno stack di kernel 3D, ciascuno di dimensione :
- SI usi padding 1 lungo tutte le dimensioni, così l’output avrà ancora dimensione
Si consideri la posizione nell’output.
A questa posizione:
- Si posiziona ogni kernel (uno per ciascun canale ) con il suo centro su
- Da ogni volume di input si estrae un blocco cubico di dimensione :
- Profondità: da a →
- Larghezza (): da a →
- Altezza (): da a →
In notazione Python-like:
✴️ Questo processo viene fatto per ogni canale .
🧮 Per ciascun canale di input :
- Si calcola il prodotto scalare tra il blocco estratto da e il corrispondente kernel
📌 Alla fine:
- Si sommano i contributi da tutti i canali
- Si aggiunge il bias
- Si applica la funzione di attivazione
Risultato:
Conv 2D vs 3D
| Convoluzione 2D | Convoluzione 3D | |
|---|---|---|
| Input | immagini 2D | blocchi 3D |
| Filtro convoluzionale | Stack di kernel 2D | Stack di kernel 3D |
| Per ogni posizione | Prodotto scalare 2D × 2D | Prodotto scalare 3D × 3D |
| Uscita (canale ) |
🔎 Geometria vs Notazione tensoriale
- La descrizione geometrica riguarda le dimensioni spaziali effettive di un oggetto (e.g. larghezza, altezza, profondità).
- La descrizione in termini di tensore aggiunge dimensioni “astratte” usate per rappresentare aspetti logico-strutturali come canali, batch o filtri.
- Di conseguenza, un oggetto che geometricamente è -dimensionale può corrispondere a un tensore di ordine superiore.
Esempio:
Un kernel cubico che agisce nello spazio è geometricamente 3D (profondità, altezza, larghezza).
Se però lo si considera in un modello neurale con più canali di input, la sua rappresentazione diventa un tensore 4D (canali × profondità × altezza × larghezza).
Le ulteriori dimensioni non sono spaziali, ma descrivono la struttura dei dati.
Note
📎 Ogni filtro convoluzionale 3D è un blocco 4D di pesi con forma
📎 La profondità del kernel non deve coincidere con la profondità dell’input :
il kernel viene spostato lungo esattamente come lungo e
🚫 Limitazioni delle convoluzioni 3D
Le CNN con convoluzioni 3D non sono molto diffuse perché:
- Il numero di parametri cresce rapidamente con le dimensioni del volume (profondità, altezza, larghezza)
- Richiedono più memoria e potenza computazionale rispetto alle CNN 2D
Le CNN funzionano molto bene su segnali 1D e immagini 2D, ma per dati 3D non rappresentano lo stato dell’arte.
➤ I Transformer, al contrario, sono dimension-agnostic e stanno emergendo come alternativa più efficace per strutture dati complesse e ad alta dimensionalità.