Esempio di BN
BNell’esempio seguente la BN è applicata a monte della funzione di attivazione sigmoidale
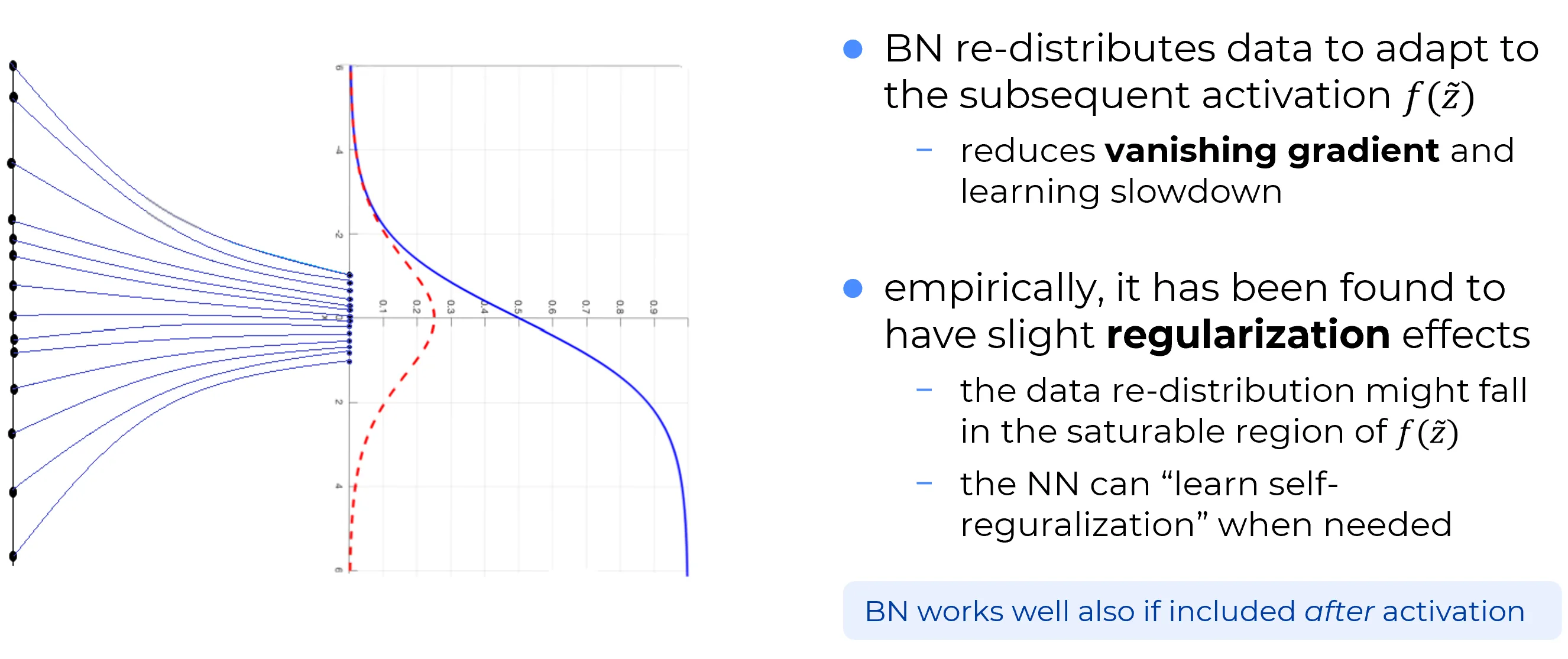
I punti neri all’estrema sinistra rappresentano le variabili a valle, ad esempio, del primo layer.
Tali , inizialmente normalizzati all’interno del layer di input (dove i neuroni sono puramente fittizi), risultano de-normalizzati dopo il primo layer effettivo.
Grazie all’intervento del layer di Batch Normalization, questi campioni de-normalizzati vengono nuovamente ricondotti a una distribuzione centrata attorno allo zero, secondo la regola empirica del 99% (cioè con ), garantendo che la quasi totalità degli input cada in questo intervallo.
Questo processo ha un effetto estremamente vantaggioso: fa sì che la maggior parte dei valori in ingresso cada in una zona “utile” della funzione di attivazione, ovvero in quell’intervallo in cui la funzione risulta sufficientemente ripida (steep).
Note
È però importante sottolineare che, con l’introduzione del Batch Normalization, non ci si limita a standardizzare i valori a media nulla e varianza unitaria: questi costituiscono solo uno degli step previsti dal paradigma del BN, come illustrato in precedenza.
I parametri apprendibili e conferiscono infatti alla rete, per ciascun neurone (nel caso, ad esempio, di un MLP), due gradi di libertà aggiuntivi, permettendole di trasformare i dati in maniera coerente con ciò che essa “ritiene” più opportuno durante l’addestramento.
✅ 1st: Redistribuzione dei dati per adattarsi all’attivazione
La Batch Normalization (BN) modifica la distribuzione dei dati in uscita da un layer rendendola più compatibile con la funzione di attivazione successiva .
Ogni funzione di attivazione ha i propri pregi e difetti. Tuttavia, stante i maggiori gradi di liberta (i parametri l’integrazione di un layer di Batch Normalization conferisce alla rete nuovi gradi di libertà, . e apprendibili, per neurone) di cui la rete beneficia mediante l’integrazione di un layer di Batch Normalization, è possibile che la rete possa apprendere una trasformazione dei dati tale da neutralizzare o attenuare i punti deboli intrinseci della funzione di attivazione impiegata.
Emblematico a tale proposito è il suddetto esempio con la funzione sigmoide. Nonostante sia spesso considerata una scelta sub-ottima a causa dei suoi noti svantaggi, il combinato disposto di un layer di Batch Normalization e di tale funzione di attivazione mitiga efficacemente le criticità di quest’ultima. L’effetto netto di un layer BN, infatti, è di mantenere l’input della sigmoide in una regione non-saturata, dove il gradiente è significativo.
Naturalmente ciò riduce il rischio di “vanishing gradient”, il fenomeno per cui i gradienti diventano di entità trascurabile durante la backpropagation, rallentando o bloccando l’apprendimento.
✅ 2nd Leggero effetto di regolarizzazione
Empiricamente, è stato osservato che BN introduce anche leggeri effetti di regolarizzazione, simili a quelli ottenuti con tecniche come dropout o weight decay.
Si supponga, nell’esempio della figura precedente, di considerare come funzione di attivazione la ReLU, al fine di enfatizzare il concetto. In tal caso, la rete potrebbe apprendere dei termini di bias tali per cui i campioni cadono nella regione sinistra del dominio della ReLU, dove essa è identicamente nulla. Di conseguenza, i neuroni associati a tali termini di bias risultano spenti, e ciò favorisce un comportamento di regolarizzazione simile a quello ottenuto con il dropout.
Important
Esiste una regola empirica secondo cui, quando si impiegano sia la Batch Normalization (BN) sia il Dropout, dato che svolgono funzioni simili, è preferibile non scegliere un dropout troppo aggressivo, poiché una forma di dropout è già implicita nella BN stessa. Pertanto, quando BN e Dropout vengono usati congiuntamente, è opportuno ridurre la probabilità di dropout, altrimenti si rischia un’eccessiva regolarizzazione che potrebbe comportare problemi di underfitting.
💬 Nota pratica
BN funziona bene anche se applicata dopo l’attivazione, anche se comunemente si mette prima. Ciò significa che, a seconda del framework o dell’implementazione, si può trovare:
Input netto al Network Layer → BatchNorm Layer→ Activation Function: questo è il caso dell’esempio riportato nella figura precedente dove il BN Layer modifica la distribuzione degli input netti al layer della rete rendendola più compatibile con la funzione di attivazione immediatamente successiva
Input netto al Network Layer → Activation Function → BatchNorm Layerin tal caso è il layer BN precedente (“associato” al layer precedente della rete) che modifica la distribuzione degli input netti in ingresso al layer in esame, rendendola più compatibile con la funzione di attivazione associata al layer della rete che si sta considerandoA prescindere dalla posizione in cui viene inserita — prima o dopo l’attivazione — è comunque fondamentale includere un layer di Batch Normalization per ciascun layer della rete.