Nel contesto delle reti neurali profonde, il covariate shift si riferisce al fatto che la distribuzione delle attivazioni cambia da un layer all’altro durante l’addestramento.
Anche se si parte da input normalizzati, ogni layer applica trasformazioni (lineari + non lineari) che modificano la distribuzione dei dati in uscita, rendendola potenzialmente molto diversa da quella ricevuta in ingresso.
Questo fenomeno, detto anche covariate shift interno, può rallentare la convergenza e rendere instabile la discesa del gradiente, perché ogni layer successivo deve continuamente riadattarsi a una nuova distribuzione.
Problema
Anche se si normalizzano i dati iniziali, a valle di ogni layer la distribuzione delle attivazioni cambia.
Questo accade perché:
Ogni layer applica una trasformazione affine:
Anche se ha media e varianza , la moltiplicazione per e la somma con ne alterano media e varianza.
La funzione di attivazione non lineare (es. ReLU, tanh):
- ReLU tronca i valori negativi → sposta la media verso destra.
- tanh e sigmoid comprimono i valori in un intervallo finito → riduzione della varianza.
Il risultato è che ogni layer introduce un cambiamento di distribuzione nei dati che produce.
Questo fenomeno rallenta l’addestramento e rende la discesa del gradiente instabile, poiché i layer successivi devono continuamente riadattarsi a input con distribuzioni diverse.
Solution: Normalizzazione inter-layer
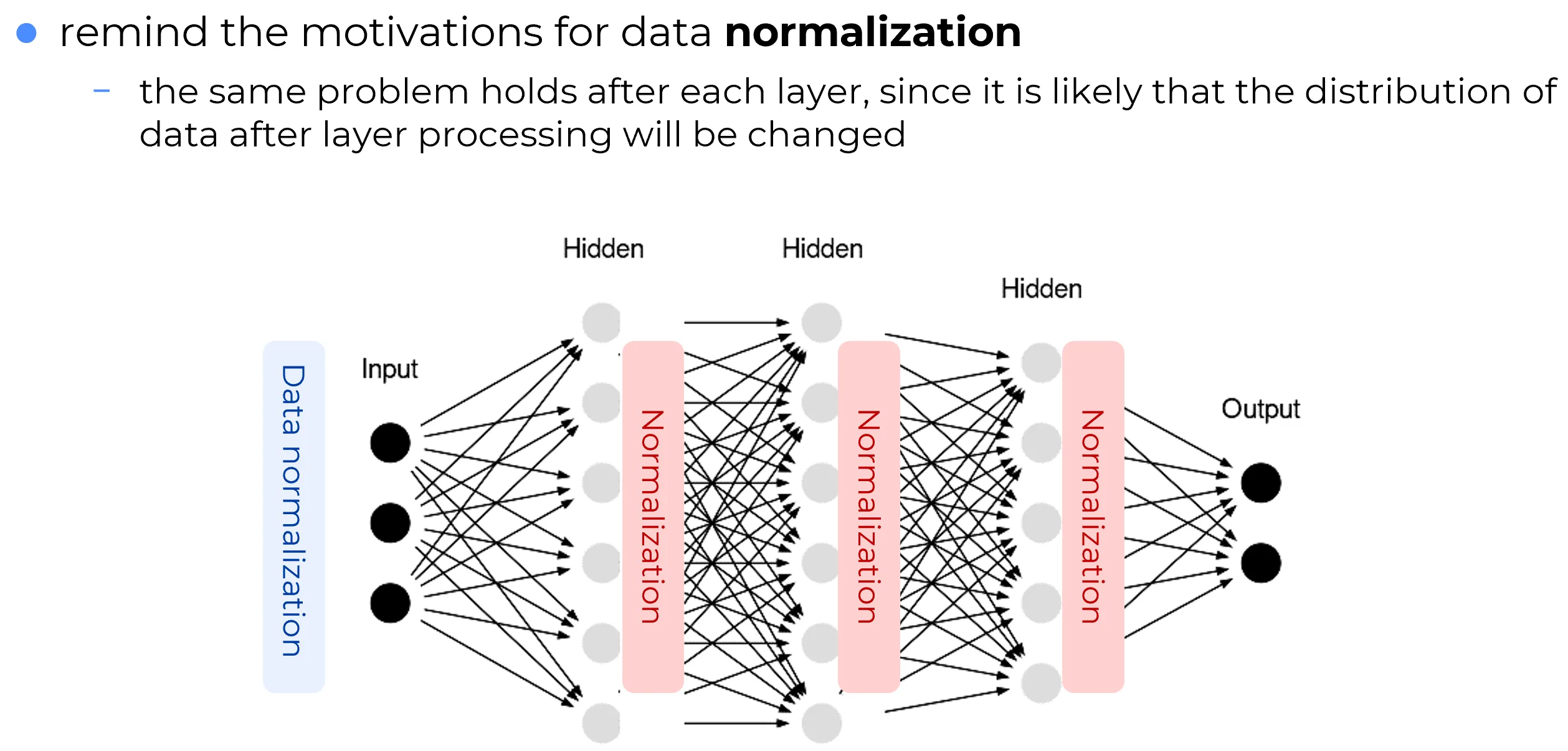
Nella figura seguente:
- A sinistra: si effettua una data normalization iniziale sui dati grezzi in input (e.g. standardizzazione con media , varianza ).
- In ogni blocco Hidden, dopo il passaggio lineare e l’attivazione, viene applicato un blocco di Normalization (e.g. BatchNorm, LayerNorm).
Questo aiuta a:
- Stabilizzare le distribuzioni intermedie.
- Ridurre l’effetto del covariate shift.
- Accelerare la convergenza del training.
Messaggio chiave
La normalizzazione non è utile solo sui dati in input, ma è fondamentale anche all’interno della rete per mantenere le distribuzioni “stabili” tra i layer.
Tecniche comuni di normalizzazione nei layer
Per mitigare questo problema si usano tecniche di normalizzazione tra i layer che mantengono le attivazioni in un range controllato e stabile.