The missing piece
The notes so far have shown how a network learns its weights and biases by gradient descent: each step nudges the parameters a little way down the gradient of the loss, . One ingredient was taken for granted, the gradient itself. Backpropagation is the algorithm that computes it, quickly and exactly, for a network of essentially any size. This section is about how it works and why it is the right tool.
What backpropagation is, and what it is not
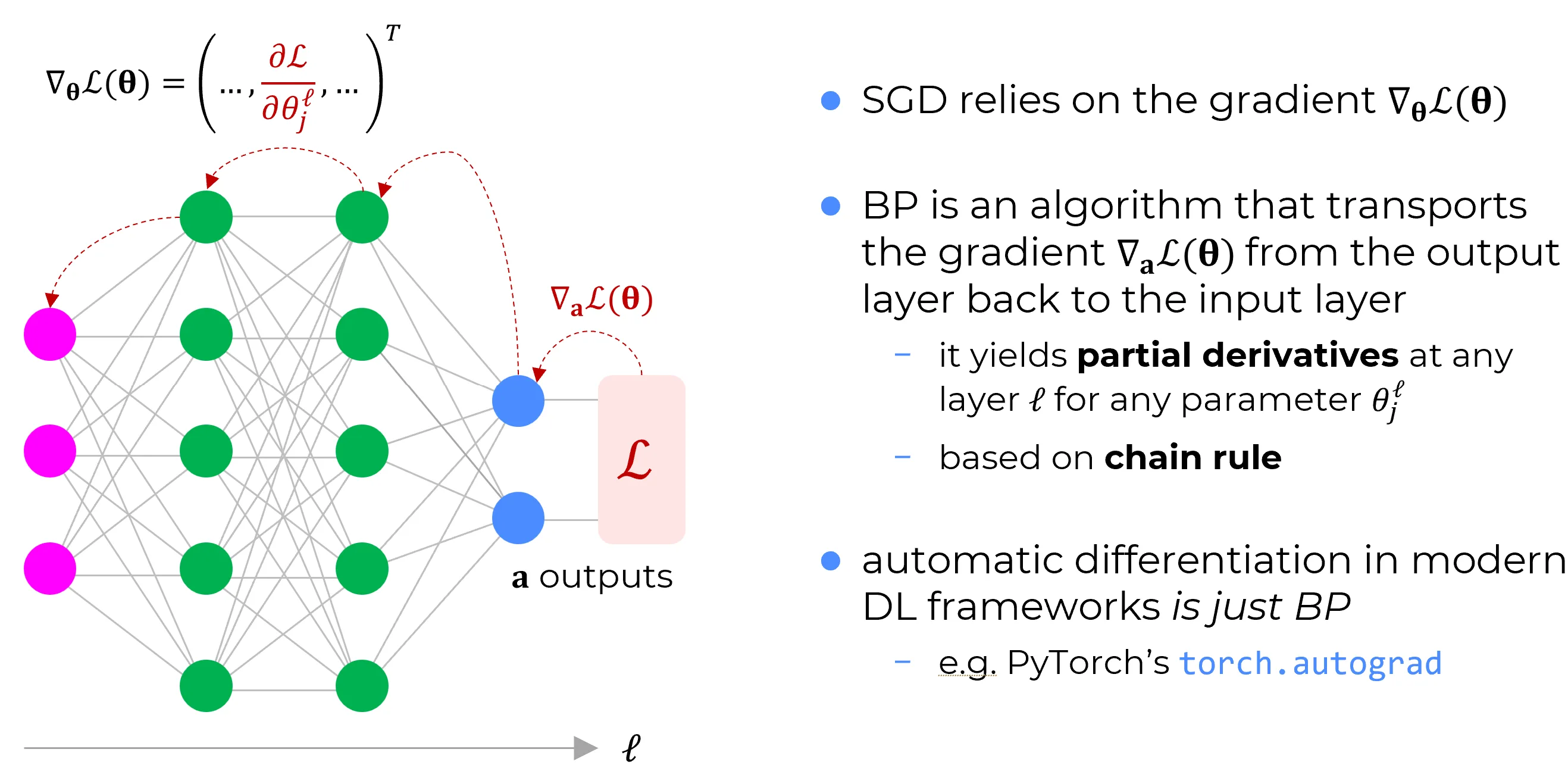
Backpropagation has a single job: given the current parameters, return the partial derivative of the loss with respect to each of them,
for every weight and bias in the network. Each such number answers a concrete question: at what rate does the loss change if this one parameter is nudged, with the rest held fixed? Collected together, they form the gradient that the optimizer then consumes.
Two clarifications matter from the outset, because the word is routinely overloaded.
Backpropagation computes the gradient; it does not do the learning
The parameter update, the learning itself, is carried out by a separate algorithm, such as stochastic gradient descent or Adam. Backpropagation only supplies the gradient those methods act on. Keeping the two apart is what keeps the theory clean: one part is a gradient oracle, the other decides what to do with the gradient.
Backpropagation is not a neural-network technique
Nothing in the method assumes a network. It applies to any differentiable function assembled from elementary operations, which is why its proper name is reverse-mode automatic differentiation. A neural network is one common and important instance. This is the viewpoint taken up in Computational graphs, where the network dissolves into a graph of simple operations and the gradient follows from the chain rule applied to that graph.
Why it deserves a whole section
Two properties raise backpropagation above a mere computational convenience.
- Speed. It returns the gradient with respect to all parameters at a cost comparable to a single evaluation of the network, rather than one evaluation per parameter. Without that guarantee, training a model with millions or billions of weights would be out of reach; with it, one backward pass costs about as much as one forward pass. The precise comparison against naive numerical differentiation is the subject of On the efficiency of BP.
- Interpretability. The gradient is more than fuel for an update. Each states how one specific connection influences the network’s error, so the same computation that drives learning also yields a precise account of how the model’s parts contribute to its mistakes.
The shape of the result
The central object of this section is the expression for and . The formula is layered, but every factor in it has a clear meaning, and the derivation is what makes each factor interpretable rather than incidental. Constructing that expression, and learning to read it, is the work of the notes that follow.
A note on history
Backpropagation reached the field along an indirect path.
| Year | Contribution |
|---|---|
| 1970 | Linnainmaa describes the reverse mode of automatic differentiation, the general algorithm behind backpropagation. |
| 1974 | Werbos applies the same idea to training neural networks, in his doctoral thesis. |
| 1986 | Rumelhart, Hinton, and Williams demonstrate its effectiveness and bring it to wide attention. |
On who invented it
As Jürgen Schmidhuber has often pointed out, the algorithm was in place well before the 1986 paper that popularized it. That paper is best credited with showing convincingly that backpropagation made previously intractable problems learnable, rather than with the invention itself. The primary papers are collected in Learning and Backpropagation.
How this section is organized
The section approaches backpropagation from a few complementary angles.
| Note | Angle |
|---|---|
| Computational graphs | The general view: backpropagation as reverse-mode differentiation on a graph of local operations. |
| BP for MLPs | The explicit view: the backpropagation equations derived for a concrete multilayer network. |
| The big picture | The intuitive view: what backpropagation is really doing, recovered from first principles by tracking a small perturbation of one weight. |
| On the efficiency of BP | The quantitative view: why the algorithm is fast, measured against the naive alternative. |
Theory and code together
The micrograd series can be read in parallel with this section: it builds a miniature automatic-differentiation engine in a few dozen lines of Python, where every idea developed here appears as a concrete line of code.