Several challenges arise in the practical application of the gradient descent rule, many of which will be examined in detail later. At this stage, however, it is useful to highlight one key difficulty.
Consider the quadratic loss introduced earlier. This loss has the form
where the individual contribution for a training example is defined as if is the MSE
In practice, computing the full gradient requires first evaluating the gradients for each individual training input , and then averaging them:
When the training set is very large, this computation becomes prohibitively time-consuming, and as a result the learning process proceeds very slowly.
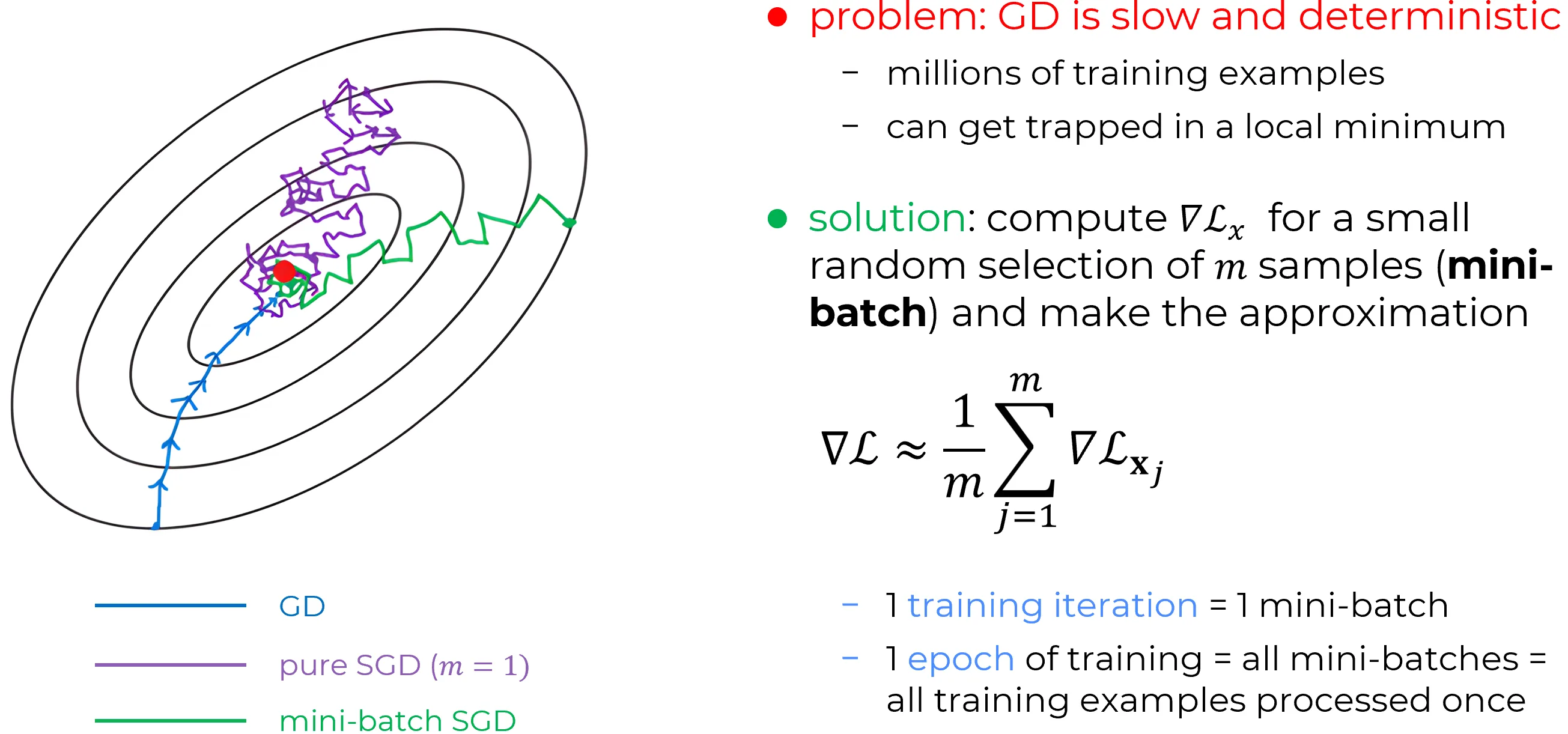
A widely used strategy for addressing this computational bottleneck is stochastic gradient descent (SGD).
The central idea is to approximate the full gradient by computing it on a small, randomly selected subset of the training data, rather than over the entire dataset.
Concretely, suppose a subset of training examples is sampled at random, denoted . This subset is referred to as a mini-batch.
For each example , the corresponding gradient is computed.
If is sufficiently large, the average of these gradients provides a good approximation to the true gradient:
Equivalently,
Thus, by averaging over a randomly chosen mini-batch, an efficient and reasonably accurate estimate of the full gradient can be obtained, significantly accelerating the learning process.
To make the connection with neural networks explicit, let and denote the weights and biases, respectively.
Under stochastic gradient descent, training proceeds by selecting a randomly chosen mini-batch of inputs and updating the parameters according to
where the sums extend over all training examples in the current mini-batch.
Once this mini-batch has been processed, a new mini-batch is drawn at random, and the process is repeated.
After all training examples have been used once, an epoch of training is said to be complete, after which the cycle begins again.
Convention on Scaling
Conventions vary regarding the scaling of the loss function and the mini-batch updates.
- In the earlier quadratic loss definition, the cost function was scaled by a factor of . In other contexts, the cost is written as a direct sum over training examples, omitting this factor. This convention is particularly useful when the total number of training examples is not fixed in advance—for instance, when new data is generated in real time.
- Similarly, the update rules above include the factor to average over the mini-batch. Some formulations omit this term, which is conceptually equivalent to rescaling the learning rate .
While these differences are not mathematically fundamental, they must be carefully noted when comparing results across different works or implementations.