Input Multi-Canale
Sia l’input al layer convoluzionale:
- : numero di canali di input (e.g. 3 per immagini RGB)
- : dimensioni spaziali
Per ogni canale di uscita , la rete apprende un filtro convoluzionale:
dove ogni è un kernel 2D dedicato al canale di input .
Questi kernel vengono impilati per formare un blocco 3D di pesi.
L’attivazione del canale di uscita è calcolata come:
dove:
- : kernel 2D associato alla coppia formata dal canale di output -esimo e dal canale di input -esimo
- : k-esimo canale dell’input
- : operazione di convoluzione 2D
- : bias associato al canale di uscita
- : funzione di attivazione (es. ReLU)
Important
Per ogni :
- il prodotto restituisce una matrice 2D (una feature map parziale);
- variando , si ottengono matrici 2D;
- queste matrici vengono sommate tra loro elemento per elemento;
- infine si aggiunge il bias (broadcasted su tutta la matrice) e si applica la funzione di attivazione .
📌 Il risultato finale è quindi una matrice 2D: la feature map completa corrispondente al canale di uscita .
Ripetendo il processo per tutti i si ottiene:
📌 Nota
Ogni filtro convoluzionale è una matrice tridimensionale di pesi,
composta da kernel 2D impilati, e produce una sola feature map di uscita.In totale, un layer convoluzionale apprende filtri indipendenti,
ciascuno responsabile di una mappa distinta nell’output.
Important
Le CNN possono essere riguardate come estrattori generali di features da immagini/segnali: esse apprendono milioni di features extractors per ogni layer, ciascuno responsabile della rilevazione di specifici pattern nei dati.
Nella figura riportata, si osserva che le CNN esibiscono milioni di parametri anche in un singolo layer convoluzionale. Analogamente, anche gli MLP possono contenere un numero molto elevato di parametri, nell’ordine di , o persino . Sebbene anche nelle CNN si raggiungano valori simili, i loro parametri sono impiegati per apprendere features differenti.
In questo senso, le CNN sono vere e proprie feature representation learners, il che le distingue profondamente dagli MLP, i quali non possiedono un meccanismo esplicito per l’estrazione gerarchica delle caratteristiche.
Avendo espresso la convoluzione in forma compatta:
tale formula si può declinare elemento per elemento, tenendo conto che:
- l’asse cresce verso destra,
- l’asse cresce verso il basso,
- l’indice corrisponde allo spostamento orizzontale (),
- l’indice corrisponde allo spostamento verticale ().
Dunque, fissata la posizione , si ottiene la forma locale:
Dettaglio: risultato delle convoluzioni 2D per canale
Per ciascun canale di input , l’operazione
restituisce uno scalare: il valore in ottenuto dalla convoluzione 2D del kernel sul canale .
- è lo spostamento orizzontale (asse ), è lo spostamento verticale (asse ).
- Il padding garantisce che anche ai bordi siano disponibili tutte le posizioni del kernel.
Ripetendo questo calcolo per tutti i , si ottengono scalari.
Tali scalari vengono poi sommati elemento per elemento:
e infine si applica bias e attivazione:
📊 Riepilogo passo‑passo per posizione
Passo Descrizione 1 Per ogni : calcola sommando i prodotti su tutti gli offset . 2 Somma i risultati: . 3 Aggiungi il bias: . 4 Applica la funzione di attivazione: .
Esempio
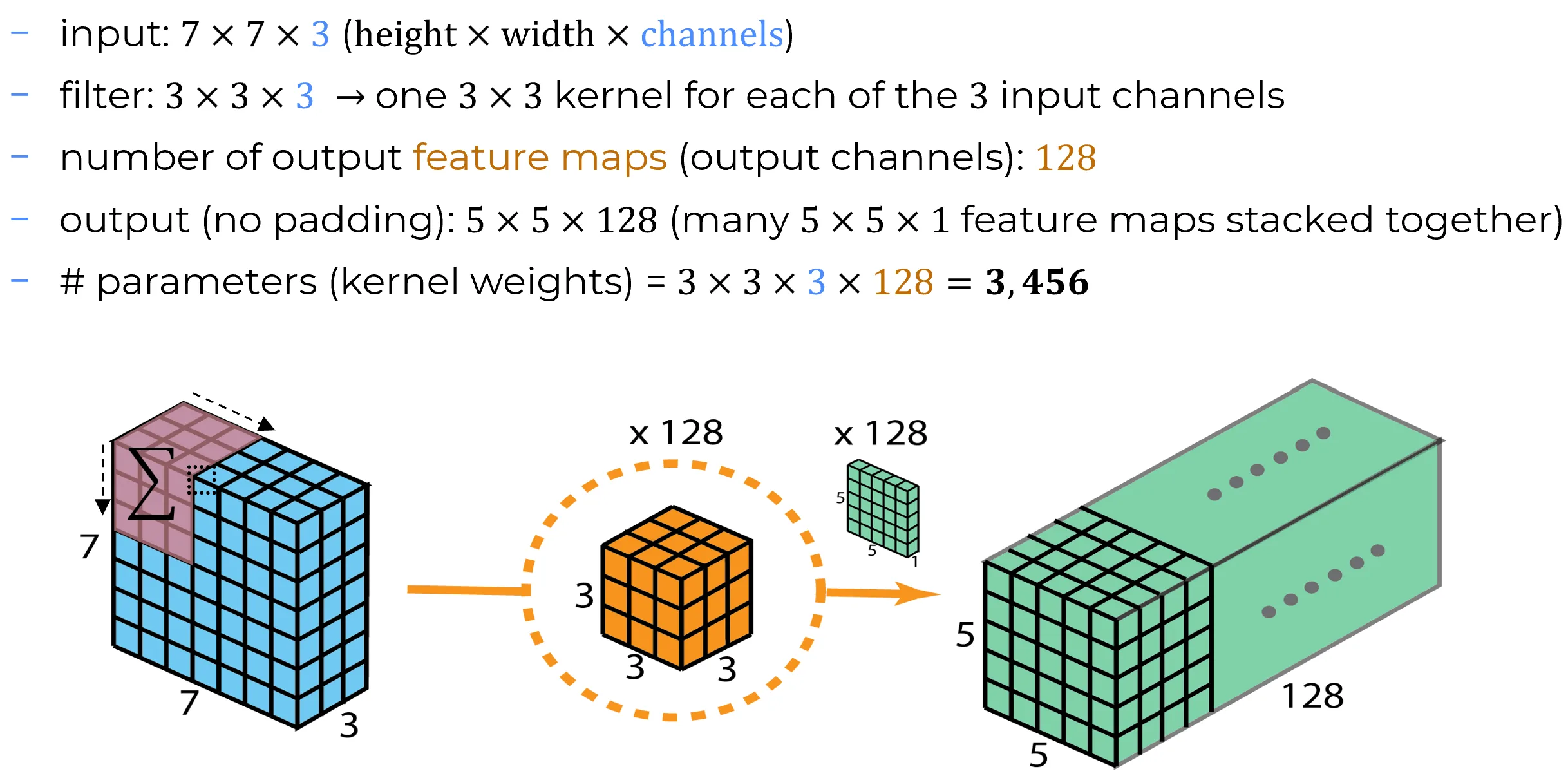
Per ogni canale di uscita e per ogni posizione , si calcola:
- la sommatoria su itera su ciascun canale di input
- la tripla sommatoria accumula i contributi dei kernel
- il risultato in è un singolo valore che, a valle dell’applicazione di , diventa l’entry della feature map
| Dimensioni | ||
|---|---|---|
| Input dims | immagine RGB | |
| Filtro per canale out | kernel da | |
| Patch spaziale valida | ||
| # output channels | quante feature map vogliamo | |
| Output dims | patch impilate | |
| Parametri per filtro | pesi di un singolo filtro | |
| Parametri totali layer | pesi del layer |
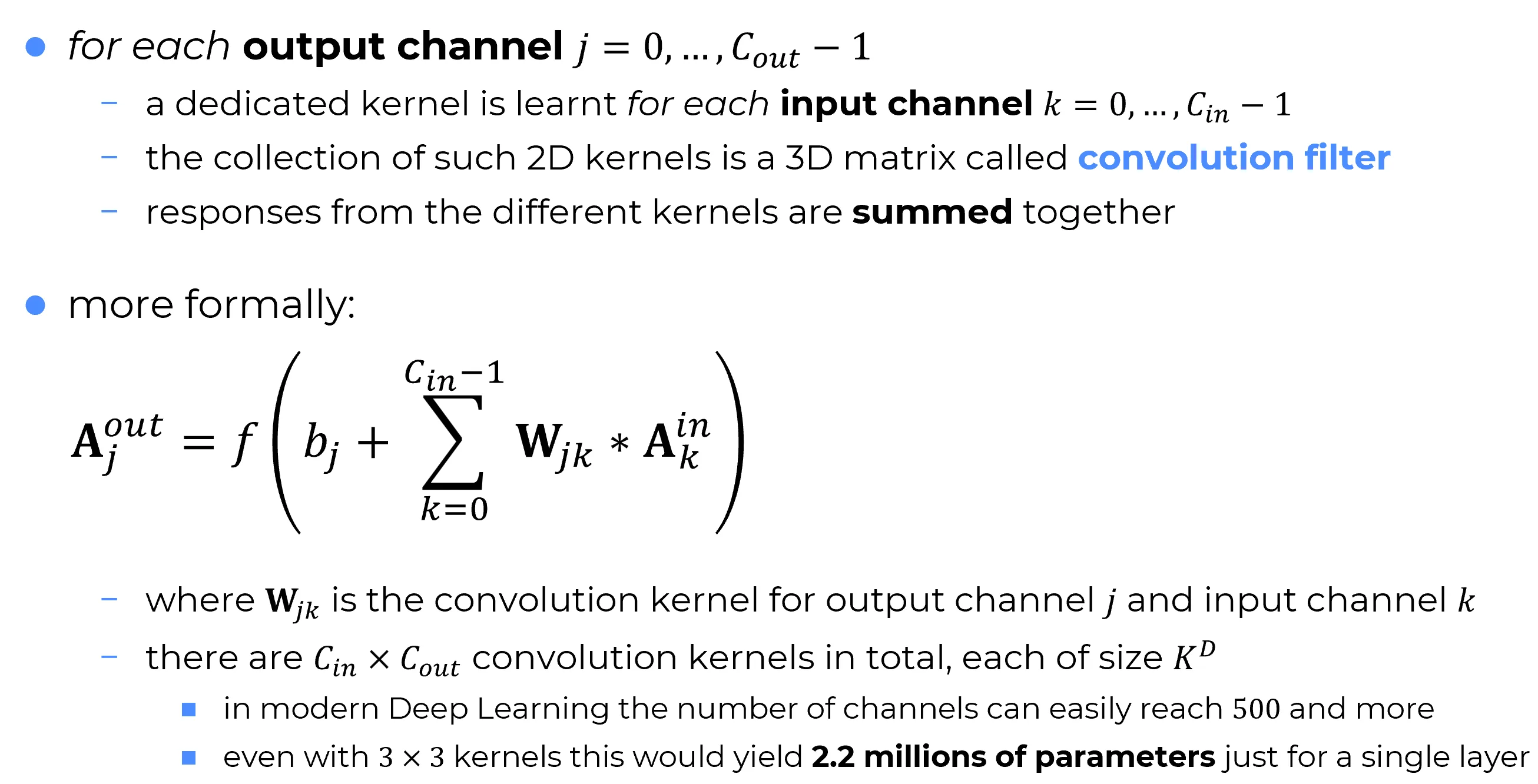
Quando si applica una convoluzione 2D a un input multicanale (e.g. un’immagine RGB), il processo può essere visualizzato in termini di blocchi 2D impilati per ciascun canale di input.
- Fissando un canale di output , la rete utilizza un filtro convoluzionale dedicato per generare la feature map corrispondente.
- Tale filtro è composto da uno stack di kernel 2D, uno per ogni canale dell’input.
- Per ogni posizione spaziale , il filtro viene centrato su quella posizione:
- si calcola la convoluzione 2D tra ciascun kernel e il rispettivo canale di input
- si ottengono mappe parziali (scalari)
- questi scalari vengono sommati, poi si aggiunge un bias e si applica una funzione di attivazione
Formula:
dove ogni è un’immagine 2D, ogni è un kernel 2D.
Visualization
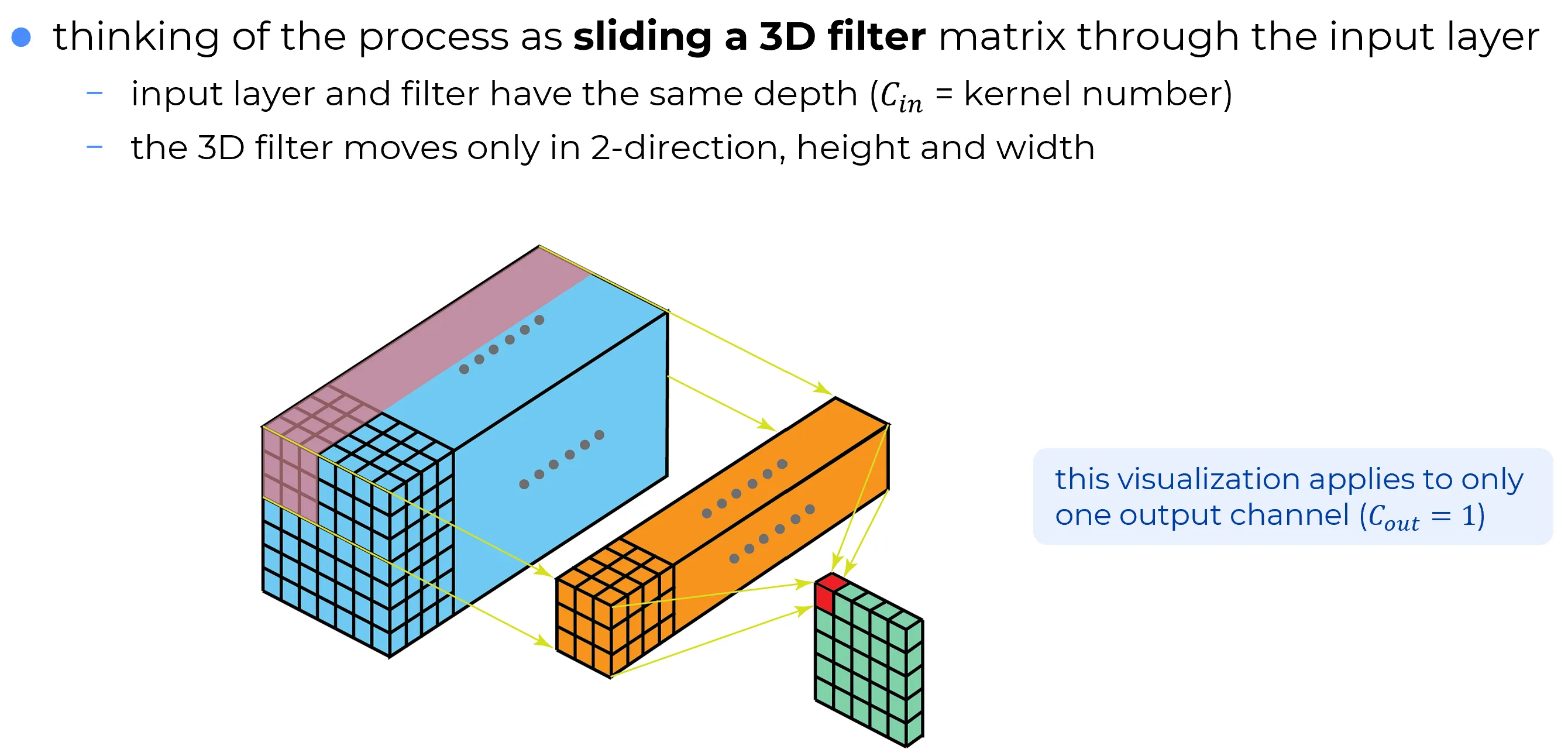
| No Padding |
|---|
| Padding |
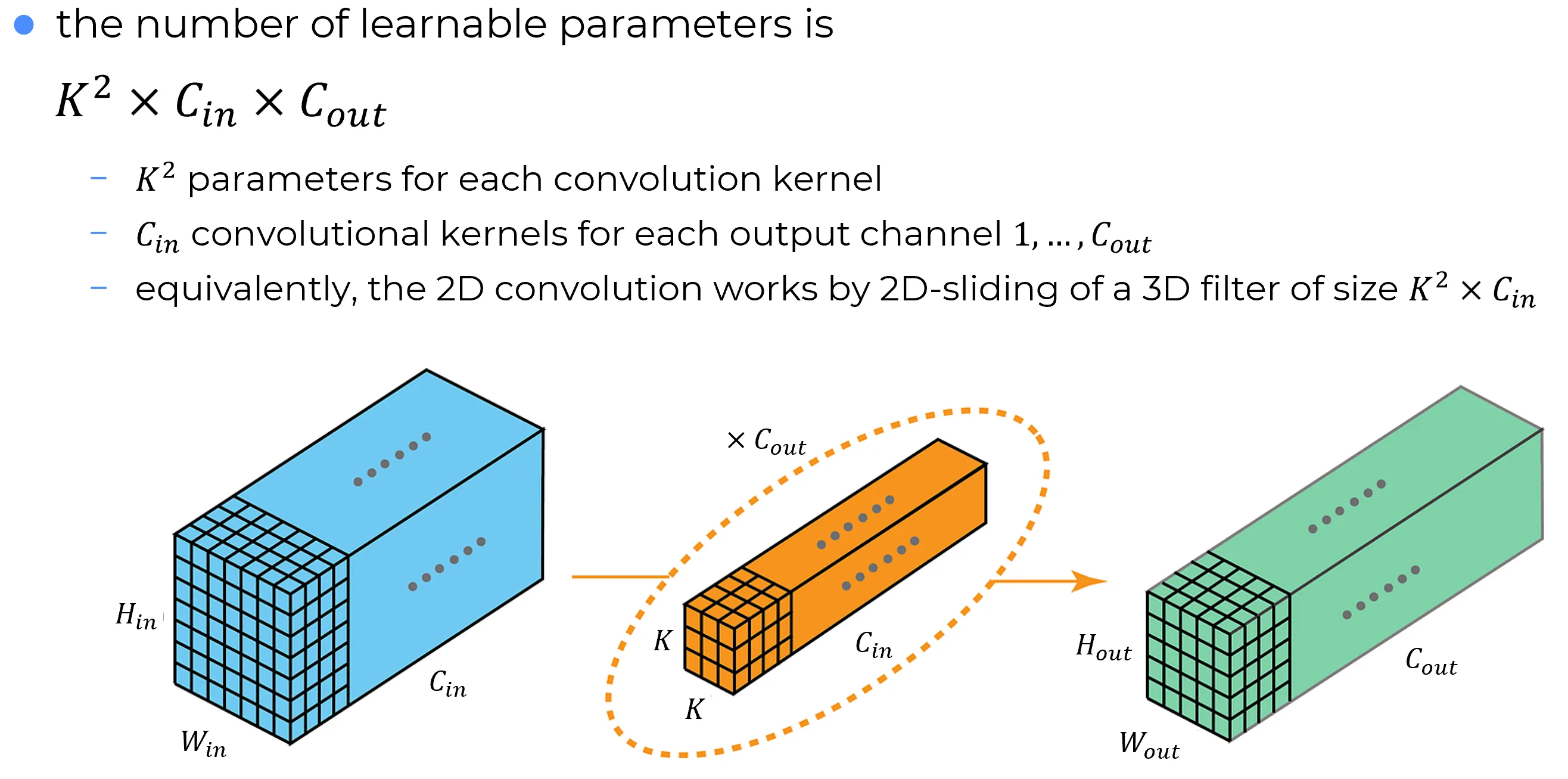
Numbers of parameters involved
AlexNet and Gabor Filters
Nel il gruppo di Hinton, che vinse la ImageNet Challenge con la rete AlexNet, si avvalse di filtri convoluzionali di dimensioni : tali filtri, associati al primo layer (deputato a processare i dati di input ossia le immagini raw), erano e ciascuno è composto da kernel .
Info
Laddove i kernel non possono essere visualizzati, sono solo un insieme di numeri, i kernel possono essere ispezionati visivamente.
Note
AlexNet è stata la prima istanza di successo di una rete CNN (a rigore anche la prima CNN proposta da Lecun fu un successo ma su scala piu piccola: il riconoscimento di caratteri manoscritti) su larga scala (ImageNet-scale: milioni di immagini e migliaia di categorie).
Nella seguente figura, a sinistra sono riportati i primi su filtri appresi automaticamente dal primo layer convoluzionale di AlexNet. A destra sono riportati i kernel convoluzionali di Gabor usati nell’Image Analysis per estrarre features.
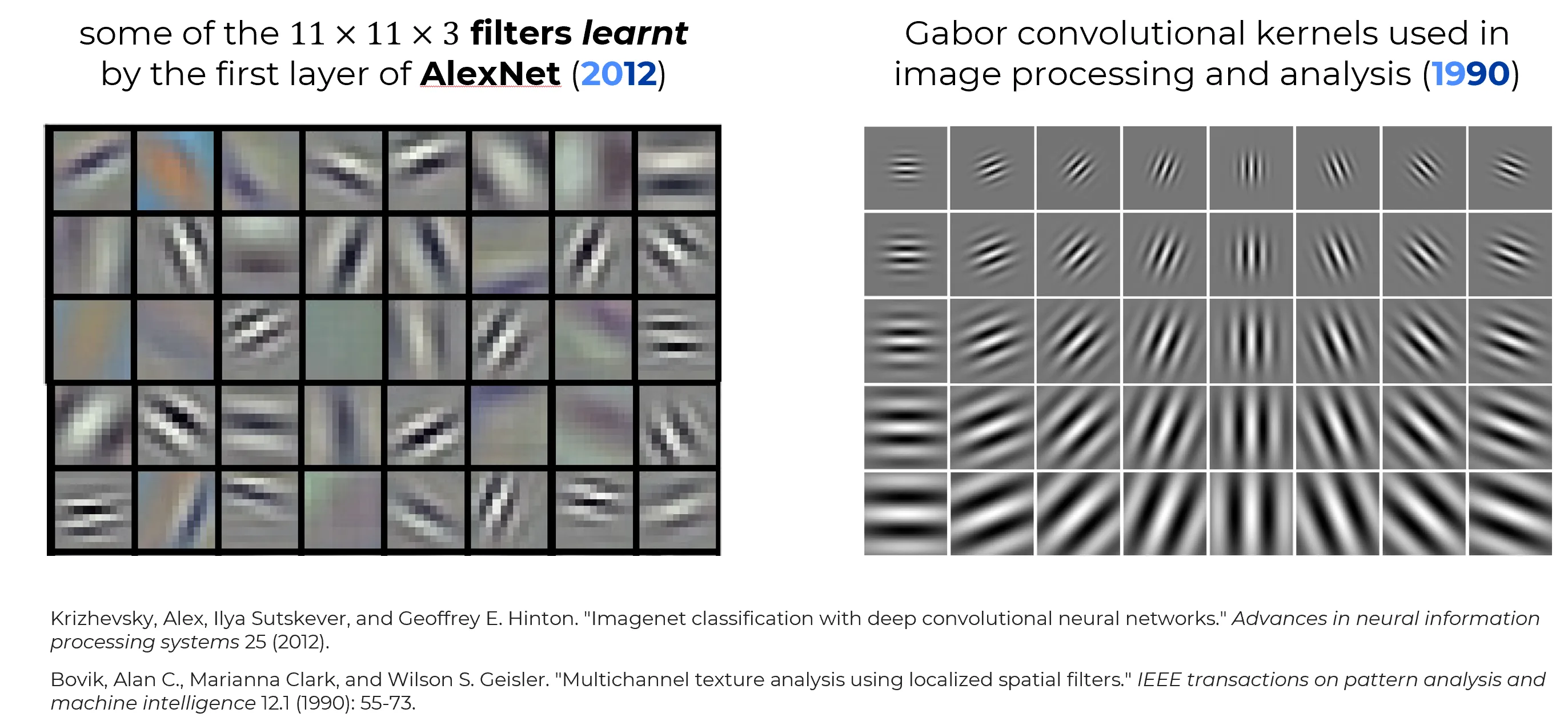
Gabor filters vs AlexNet
È strabiliante notare come i filtri appresi automaticamente dal primo layer convoluzionale di AlexNet risultino sorprendentemente simili ai kernel convoluzionali di Gabor. La somiglianza tra gli estrattori di features appresi automaticamente e quelli progettati manualmente dall’uomo, come i filtri di Gabor, è sorprendente.
Motivazione intuitiva I filtri di Gabor sono estrattori di bordi di basso livello. Il primo layer di AlexNet è essenzialmente è un estrattore di features di bordi
Ciò accade nella retina umana: la prima cosa che avviene nella nostra retina è la sensibilità ai bordi.
CNN and Visual Cortex
Sussiste un chiaro parallelismo: la percezione visiva umana, l’estrazione matematica delle caratteristiche (come i filtri di Gabor) e l’estrazione automatica tramite CNN convergono tutte verso lo stesso principio fondamentale: il primo passo consiste nell’estrarre i bordi dall’immagine. Da questi bordi si costruiscono livelli superiori di astrazione.
Si parla, infatti, di una catena di livelli di astrazione.
Important
Le CNN sono un tool di apprendimento di rappresentazioni gerarchiche per le immagini.