Nel caso di convoluzione 3D, l’intuizione si estende a blocchi 3D:
- Per ogni canale l’input è un blocco tridimensionale: profondità , altezza , larghezza
- Se ci sono canali, si hanno blocchi 3D, uno per ciascun canale
- Ogni rappresenta il -esimo canale di input come un volume 3D
Fissando un canale di output :
- Il filtro convoluzionale usato dalla rete è uno stack di kernel 3D, ognuno di dimensione
- Questi kernel scorrono nei rispettivi blocchi di input
Calcolo del valore in uscita
Per ogni posizione spaziale nella mappa di output del canale , il valore viene calcolato nel seguente modo:
- Per ogni canale dell’input:
-
Si applica il kernel 3D sovrapponendolo al volume tridimensionale in modo che il centro del kernel cada sulla posizione
-
Si estrae quindi una regione cubica di dimensione dal -esimo canale dell’input
-
Questo significa che la finestra del kernel scorre lungo le tre dimensioni , e a ogni passo raccoglie un blocco locale dell’input allineato con i pesi del kernel
-
Si calcola infine il prodotto scalare elemento per elemento tra questa regione e il kernel :
-
- Si sommano i contributi di tutti i canali :
- Si aggiunge il bias e si applica la funzione di attivazione :
Note
Ogni valore rappresenta uno scalare all’interno della mappa tridimensionale del canale di uscita .
Formula esplicita: versione element-wise
Esplicitando completamente la convoluzione 3D rispetto agli indici:
- : scorre la profondità
- : scorre le righe (altezza)
- : scorre le colonne (larghezza)
- , , : padding lungo ciascun asse
Il kernel convoluzionale viene sovrapposto a un blocco tridimensionale per ogni canale, ed esegue un prodotto scalare canale per canale.
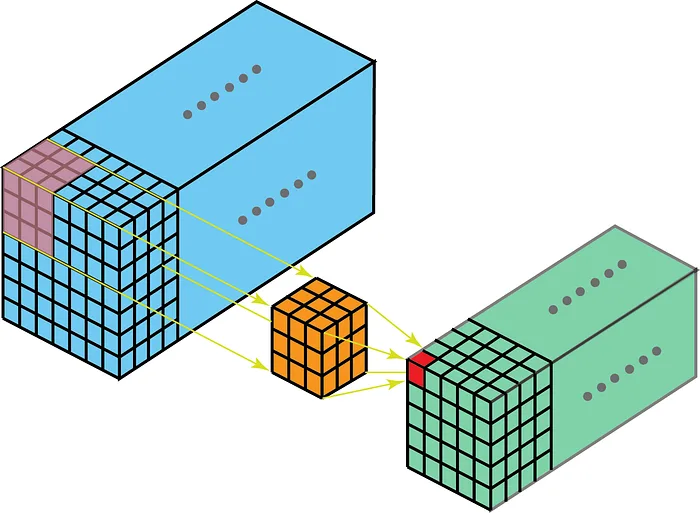
🔢 Esempio concreto: convoluzione 3D con più canali
Si supponga di avere:
- Un input tridimensionale con canali
- Ogni canale è un volume , con assi:
- : profondità (fronte ↔ retro)
- : larghezza (sinistra → destra)
- : altezza (alto → basso)
- Un filtro convoluzionale per il canale di output , composto da:
- Uno stack di kernel 3D, ciascuno di dimensione :
- SI usi padding 1 lungo tutte le dimensioni, così l’output avrà ancora dimensione
Si consideri la posizione nell’output.
A questa posizione:
- Si posiziona ogni kernel (uno per ciascun canale ) con il suo centro su
- Da ogni volume di input si estrae un blocco cubico di dimensione :
- Profondità: da a →
- Larghezza (): da a →
- Altezza (): da a →
In notazione Python-like:
✴️ Questo processo viene fatto per ogni canale .
🧮 Per ciascun canale di input :
- Si calcola il prodotto scalare tra il blocco estratto da e il corrispondente kernel
📌 Alla fine:
- Si sommano i contributi da tutti i canali
- Si aggiunge il bias
- Si applica la funzione di attivazione
Risultato:
Conv 2D vs 3D
| Convoluzione 2D | Convoluzione 3D | |
|---|---|---|
| Input | immagini 2D | blocchi 3D |
| Filtro convoluzionale | Stack di kernel 2D | Stack di kernel 3D |
| Per ogni posizione | Prodotto scalare 2D × 2D | Prodotto scalare 3D × 3D |
| Uscita (canale ) |
🔎 Geometria vs Notazione tensoriale
- La descrizione geometrica riguarda le dimensioni spaziali effettive di un oggetto (e.g. larghezza, altezza, profondità).
- La descrizione in termini di tensore aggiunge dimensioni “astratte” usate per rappresentare aspetti logico-strutturali come canali, batch o filtri.
- Di conseguenza, un oggetto che geometricamente è -dimensionale può corrispondere a un tensore di ordine superiore.
Esempio:
Un kernel cubico che agisce nello spazio è geometricamente 3D (profondità, altezza, larghezza).
Se però lo si considera in un modello neurale con più canali di input, la sua rappresentazione diventa un tensore 4D (canali × profondità × altezza × larghezza).
Le ulteriori dimensioni non sono spaziali, ma descrivono la struttura dei dati.
Note
📎 Ogni filtro convoluzionale 3D è un blocco 4D di pesi con forma
📎 La profondità del kernel non deve coincidere con la profondità dell’input :
il kernel viene spostato lungo esattamente come lungo e
🚫 Limitazioni delle convoluzioni 3D
Le CNN con convoluzioni 3D non sono molto diffuse perché:
- Il numero di parametri cresce rapidamente con le dimensioni del volume (profondità, altezza, larghezza)
- Richiedono più memoria e potenza computazionale rispetto alle CNN 2D
Le CNN funzionano molto bene su segnali 1D e immagini 2D, ma per dati 3D non rappresentano lo stato dell’arte.
➤ I Transformer, al contrario, sono dimension-agnostic e stanno emergendo come alternativa più efficace per strutture dati complesse e ad alta dimensionalità.
🧱 Nota Bene — Padding nella profondità (dimensione )
Nella convoluzione 3D, il kernel ha dimensione e viene fatto scorrere lungo tutte e tre le dimensioni: profondità (), altezza (), larghezza ().
Se la profondità del kernel è tale da “sforare” i bordi del volume di input,
allora si applica un padding anche lungo la profondità, analogamente a quanto avviene per e .
✅ Senza padding:
- Il kernel può essere centrato solo dove entra completamente.
- L’output ha profondità ridotta:
(con stride = 1)✅ Con padding:
- Si aggiunge padding sopra e sotto lungo (profondità).
- Questo consente al kernel di scorrere anche ai bordi del volume.
- L’output può mantenere la stessa profondità dell’input.
📌 Esempio:
- Input:
- Kernel:
- Padding:
→ Il kernel può scorrere da a
→ Output:
🛠️ Conclusione:
Il padding in profondità è opzionale, ma fondamentale per mantenere l’allineamento tra input e output o per controllare la dimensione dell’output desiderato.
🎯 Nota Bene — Numero di Canali di Uscita ()
Sia nella convoluzione 2D che in quella 3D, il numero di canali di uscita è una scelta indipendente dalle dimensioni spaziali del filtro convoluzionale.
- Per ottenere feature map in uscita, la rete apprende filtri distinti.
- Ogni filtro convoluzionale ha dimensione:
- In 2D:
- In 3D:
🧠 Il numero di filtri (cioè ) determina la profondità dell’output,
ma non dipende dalle dimensioni spaziali del filtro, che controllano invece l’estensione locale dell’analisi sull’input.
🧭 Nota Bene — Differenza tra dati e
Quando si lavora con reti convoluzionali, è fondamentale distinguere correttamente la struttura dell’input, soprattutto nel caso tridimensionale.
Caso 1 — Dati 2D multicanale → Forma:
- Ogni punto contiene un vettore di valori (es. RGB).
- Può essere visto come immagini 2D, una per ciascun canale.
✅ Convoluzione 2D → Filtro:
Caso 2 — Dati 3D multicanale → Forma:
Quando si lavora con un input 3D multicanale di forma ,
ci sono due modi naturali di raggruppare i dati:
Raggruppamento per canale (scelto dalle CNN 3D):
- Si fissa un canale .
- L’intero volume tridimensionale relativo a quel canale è trattato come un blocco 3D.
- In totale: blocchi 3D separati.
Questo è il punto di vista usato nei layer convoluzionali 3D:
l’input è rappresentato come un tensore 4D
(canali profondità altezza larghezza).
Raggruppamento per profondità:
- Si fissa un indice di profondità .
- Ogni slice corrisponde a un frame 2D di dimensione con canali.
- In totale: frame 2D multicanale, come nei video.
Questo punto di vista è utile quando rappresenta il tempo,
o una sequenza ordinata di dati (frame, istanti, scansioni).
📌 Quando usare ciascuna rappresentazione?
Se rappresenta una dimensione spaziale o temporale reale
(es. profondità, tempo nei video, asse nelle TAC),
si usa il raggruppamento per canale → convoluzione 3D standard.Se invece è una proprietà interna al canale (es. spettro, feature astratte),
può essere trattato come parte dei canali:
si ridefinisce e si può usare convoluzione 2D.
ℹ️ Profondità dell’output nella convoluzione 3D
In una convoluzione 3D, ogni canale di output genera una feature map tridimensionale,
di forma: .La profondità dell’output dipende da:
- profondità dell’input:
- dimensione del kernel lungo la profondità:
- padding lungo la profondità:
- stride lungo la profondità:
🧮 Formula generale per la profondità dell’output:
📌 Quindi:
Se non si usa padding ():
👉 L’output avrà profondità ridotta rispetto all’input.
Se si desidera che l’output abbia la stessa profondità dell’input (),
allora bisogna usare il **padding :
✅ Il numero di canali di output è indipendente dalla profondità:
può essere scelto liberamente, come avviene nella convoluzione 2D.
Differenza tra e
❗ È importante ricordare che nella convoluzione 3D:
- è la profondità dell’input (cioè quante “slice” ha ogni blocco 3D)
- è la profondità del kernel, ovvero quanto “spesso” è ciascun kernel 3D
✅ Non è necessario che .
Al contrario:
- Spesso , così il kernel può scorrere lungo la profondità
- Questo consente di catturare pattern locali nel tempo (es. video o segnali volumetrici)
📌 Analogamente a quanto avviene per altezza e larghezza (, ), anche agisce come una finestra mobile che si sposta lungo l’asse della profondità.
Questo approccio permette di generare un output tridimensionale con profondità (a meno che non si usi padding “same” per mantenere ).