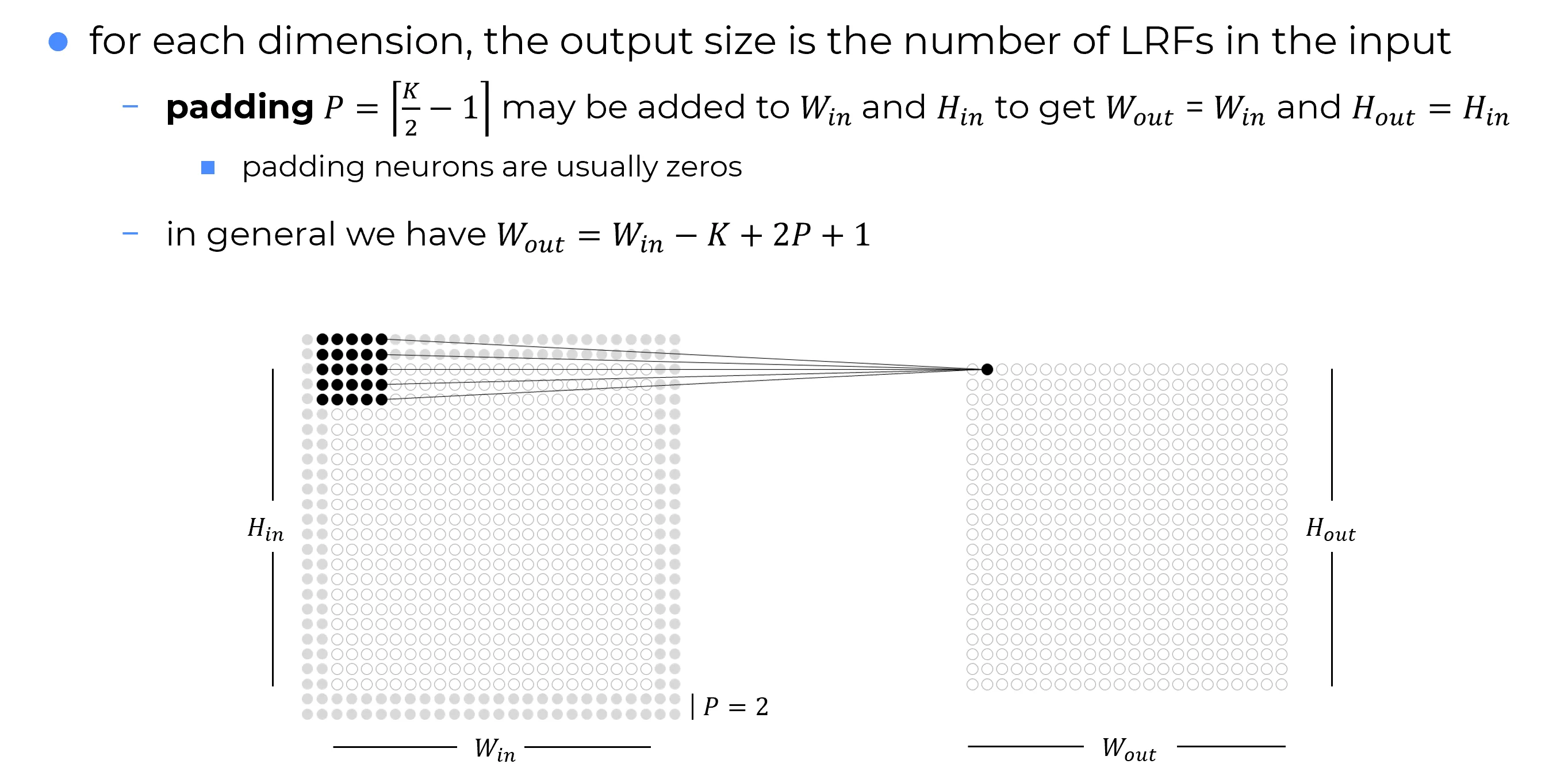
Convolutional layer parameters operate independently along each axis.
Formally, the choice of kernel size, stride, or padding along axis j affects only the output size of axis j, and does not interact with axis i=j.
For example, in a 2D image: modifying the stride or padding along the horizontal axis changes the width of the output, but leaves the height unchanged.
Here, the term axis follows the same convention as in NumPy (and most deep learning libraries): axis 0 corresponds to rows (height), axis 1 to columns (width), and so on.
Dimostrazione Wout=Win−K+2P+1
Note
Nel prosieguo, a meno di riferimenti espliciti, si assume che lo stride sia unitario: Stride =1
1. Quantità in gioco
Simbolo
Significato
Nota
K
dimensione del local receptive field (finestra K×K nel caso 2D)
iper‑parametro
P
numero di valori nulli (zero padding) aggiunti per lato
iper‑parametro
Win
estensione dell’input lungo una qualunque dimensione (qui si sceglie la larghezza)
dato del layer precedente
Wout
estensione dell’output lungo la stessa dimensione
incognita da calcolare
Il ragionamento per W si replica mutatis mutandis per l’altezza H e per qualsiasi altra dimensione spaziale (e.g. profondità nei dati 3‑D).
2. Estensione dovuta allo zero padding
Il padding inserisce P valori nulli su ciascun lato della dimensione considerata. Se si considera la larghezza (width), ad esempio, questi vengono aggiunti ai bordi sinistro e destro dell’input.
La dimensione totale su cui il local receptive field potrà scorrere, ossia la dimensione effettiva (Weff), è data dalla dimensione originale più i valori aggiunti su entrambi i lati.
Weff=Win+2P
In pratica, l’input viene “incorniciato” da zeri, passando da una struttura [dati] a una [zeri, dati, zeri] lungo quella dimensione.
3. Calcolo delle Posizioni del LRF (Stride = 1)
Per determinare la dimensione dell’output (Wout), bisogna contare in quante posizioni distinte il local receptive field (LRF), di dimensione K, può scorrere lungo la dimensione effettivaWeff.
Il primo LRF si allinea con l’inizio della dimensione effettiva. Il suo indice di partenza è quindi 0.
L’ultimo LRF deve essere contenuto interamente nella dimensione effettiva.
Un LRF di ampiezza K che parte dall’indice x occupa il range di indici [x,x+K−1].
Per garantire che l’LRF non “sfori” i limiti, il suo ultimo elemento (x+K−1) non può superare l’ultimo indice della dimensione effettiva (Weff−1):
x+K−1≤Weff−1⟹x≤Weff−K.
dove x è la massima posizione di partenza del LRF consentita.
Important
La posizione finale valida per l’inizio del LRF è quindi xmax=Weff−K.
Conteggio Totale
L’estensione dell’output lungo la dimensione in esame (Wout) è uguale al numero totale di posizioni che l’LRF può assumere. Poiché gli indici di partenza vanno da 0 a Weff−K, il conteggio è:
Wout=(Indice Finale−Indice Iniziale)+1Sostituendo i valori trovati, si ottiene:Wout=(Weff−K)−0+1=Weff−K+1
4. Formula finale
Stante la formula ricavata al passo precedente:
Wout=Weff−K+1
poiché :
Weff=Win+2P.
allora:
Wout=Win−K+2P+1
Applicando lo stesso ragionamento alla dimensione verticale:
Hout=Hin−K+2P+1
e, in un dominio 3‑D, analogamente per la profondità.
Caso generale
La relazione
\text{dimensione_out} = \text{dimensione_in} - K + 2P + 1
Formula generale per la dimensione dell’output (Stride =1)
Quando lo stride S è maggiore di 1, la finestra (LRF) salta di S posizioni invece di scorrere di 1. In questo caso, il numero di posizioni valide è dato da:
Wout=⌊SWin−K+2P⌋+1
Info
La formula tiene conto del fatto che, partendo da indice 0 e saltando di S, l’ultima posizione utile è quella più grande per cui il filtro non esce dal dominio paddato.
Viene quindi calcolato quante volte il filtro “entra” nell’input con salto S, fino all’ultima posizione valida:
xmax=⌊SWeff−K⌋
e da qui il conteggio delle posizioni è xmax+1.
Applicando la stessa formula alla dimensione verticale o ad altre dimensioni spaziali:
Hout=⌊SHin−K+2P⌋+1
e in un dominio 3D si procede allo stesso modo per la profondità.
Padding che preserva la dimensione (Wout=Win)
Imponendo che la dimensione spaziale dell’output identica a quella dell’input (Wout=Win)
nella formula (con S=1): Wout=Win−K+2P+1
si ottiene: Win=Win−K+2P+1 Semplificando si arriva alla relazione che deve soddisfare il padding:
2P=K−1⟹P=2K−1
Tipo di Kernel
Concetto Chiave
Formula per il Padding (P)
Esempi Pratici
Dispari
Permette un padding esatto e simmetrico, mantenendo le dimensioni dell’output identiche a quelle dell’input (con stride 1).
P=2K−1
- Se K=3⟹P=1 - Se K=5⟹P=2
Pari / Generale
Fornisce un valore di padding “ragionevole” quando un kernel pari è inevitabile. La soluzione non è perfettamente centrata.
P=⌈2K−1⌉ (Equivalente a P=⌊2K⌋)
- Per K=4⟹P=⌊24⌋=2 - Per K=6⟹P=⌊26⌋=3
Il Caso Standard: Kernel di Dimensione Dispari
La suddetta formula evidenzia un concetto fondamentale.
Poiché il padding P deve essere un numero intero, una soluzione esatta e simmetrica è possibile solo quando il numeratore (K−1) è pari, e cioè quando la dimensione del kernel K è dispari. Questa è la ragione principale per cui nella pratica si usano quasi esclusivamente kernel di dimensione dispari (3×3,5×5, etc.).
In questo scenario, la formula è semplice e diretta.
Esempi:
Se K=3, il padding necessario è P=(3−1)/2=1.
Se K=5, il padding necessario è P=(5−1)/2=2.
I Kernel Pari Non Preservano Esattamente la Dimensione
Allorché si usi un kernel di dimensione pari con stride 1, è matematicamente impossibile preservare la dimensione esatta dell’input con un padding simmetrico. La formula con ceiling fornisce un valore di padding, ma l’output si ridurrà comunque.
Esempio con K=4:
Calcolo del Padding:P=⌈24−1⌉=⌈2−1⌉=1.
Dimensione di Output Risultante: Usando la formula generale Wout=Win−K+2P+1, si ottiene:
Wout=Win−4+2(1)+1=Win−1
Come si vede, la dimensione di output si riduce di 1 pixel. Questo avviene perché un kernel pari non ha un pixel centrale, rendendo impossibile una sovrapposizione perfettamente simmetrica.
PyTorch mapping & quick checks
Symbol ↔ PyTorch args
Math symbol
Meaning
PyTorch (Conv2d/MaxPool2d/AvgPool2d)
K
kernel size
kernel_size
P
(symmetric) padding per side
padding (int/tuple) or 'same'¹
S
stride
stride
D
dilation
dilation
Keff
effective kernel = D(K−1)+1
derived (no direct arg)
¹ Asymmetric padding in PyTorch: use torch.nn.ZeroPad2d((left, right, top, bottom)) or torch.nn.functional.pad(...) before the conv.
Output size (Conv/Pool) — PyTorch-exact
For 1D/2D/3D conv and pooling, PyTorch uses:
out=⌊Sin+2P−D(K−1)−1⌋+1
Equivalently, with effective kernel Keff=D(K−1)+1:
In your receptive-field derivations, replace every kernel size K with the effective kernel
Keff=D(K−1)+1
for layers that use dilation D>1.
All RF recurrences and closed forms remain valid with K←Keff.
Asymmetric padding (p_l vs q_l) in PyTorch
Your notes distinguish left/right padding (pl, ql). PyTorch’s Conv2d(..., padding=…) is symmetric; if you need asymmetric padding to match your pl,ql exactly: