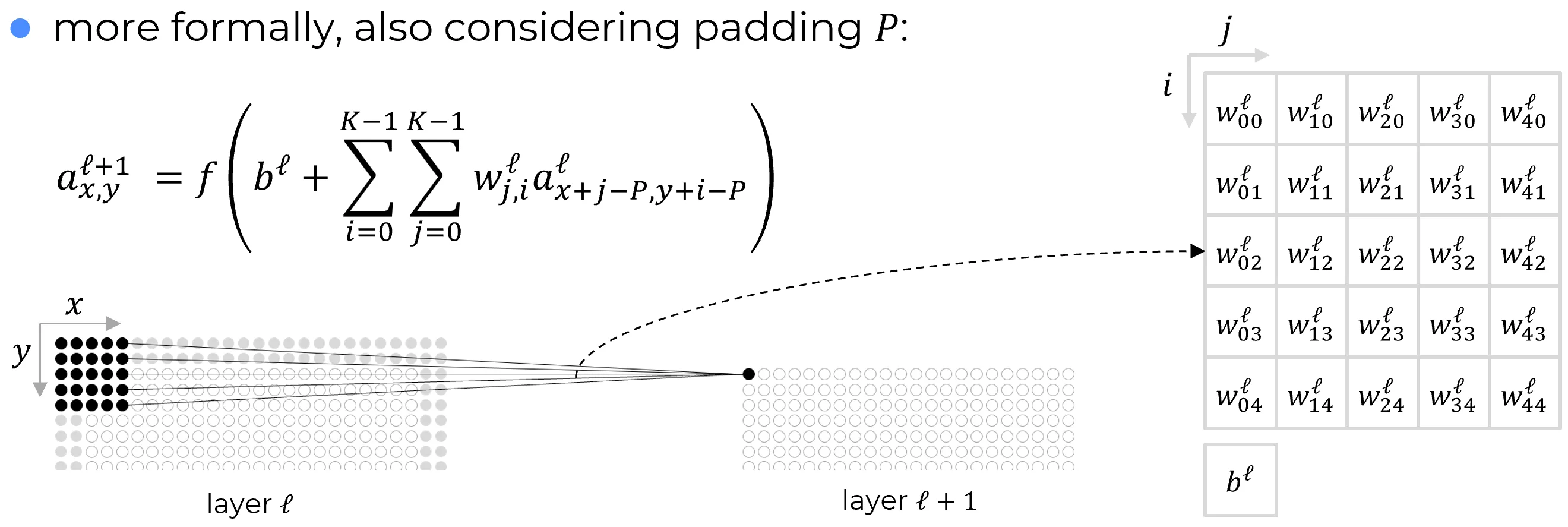
Equazione dell’attivazione convoluzionale (2D, padding simmetrico)
In presenza di un padding simmetrico di ampiezza (ovvero elementi aggiunti a ciascun lato del dominio: sopra, sotto, a sinistra e a destra nel caso ), la formula generale che calcola l’attivazione del neurone in posizione del layer è:
dove:
- è l’attivazione del layer precedente nella posizione corrispondente al punto del local receptive field (l’asse y punta verso il basso mentre l’asse x punta verso destra),
- è il valore del peso nella posizione all’interno della griglia (con indice di riga e indice di colonna),
- è un bias condiviso da tutti i neuroni del layer, analogamente ai pesi associati al lrf,
- è la funzione di attivazione (es. ReLU, sigmoid, tanh…).
Note
tiene conto del fatto che l’input originale è stato esteso simmetricamente con valori nulli, in modo che anche i neuroni situati ai bordi del dominio abbiano un LRF completo.
In tale formula si sta assumendo uno stride pari a 1, cioè il kernel si sposta di una sola posizione per volta, sia in orizzontale che in verticale.
🔎 Come si perviene a questa formula
- Il neurone in del layer osserva una finestra quadrata centrata in sull’input paddato.
- Le attivazioni del layer precedente, all’interno di quella finestra, sono moltiplicate per pesi condivisi e sommati.
- Si aggiunge un bias costante.
- Il tutto viene trasformato da una funzione (es. ReLU, sigmoid, tanh…).
Formula compatta layer convoluzionale
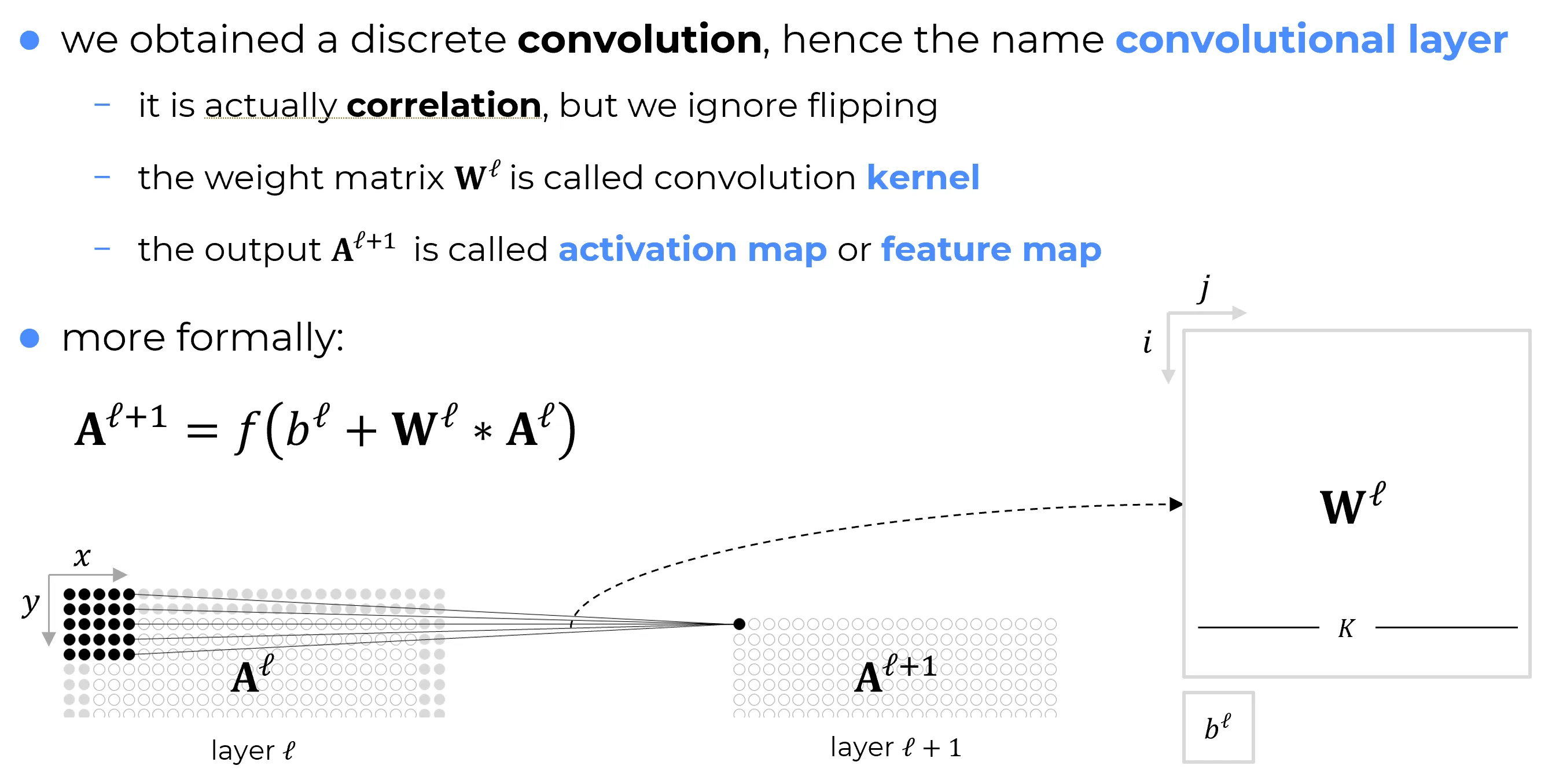
La formula compatta del layer convoluzionale è:
La suddetta formula descrive il calcolo dell’intero layer convoluzionale in forma matriciale e compatta.
Significato dei termini
- è la matrice delle attivazioni (o feature map) del layer , di dimensione .
- è la matrice dei pesi condivisi, detta anche kernel convoluzionale, di dimensione (o più in generale ).
- è un termine di bias scalare, condiviso da tutti i neuroni del layer.
- rappresenta l’operazione di convoluzione (o correlazione) tra il kernel e le attivazioni .
- è la matrice di output del layer , cioè la nuova feature map.
Dal punto di vista matriciale, la convoluzione restituisce una matrice intermedia:
A ciascun elemento di viene sommato il bias scalare , ottenendo:
La funzione di attivazione (scalare) viene quindi applicata elemento per elemento:
📌 Il risultato finale è la matrice delle attivazioni del layer .
Calcolo di un Singolo Elemento di Output
Per comprendere come viene generata la mappa di attivazione , si analizzi il calcolo di un singolo elemento in posizione .
Tale valore si ottiene dall’applicazione a cascata di una funzione di attivazione scalare non lineare (e.g. , , ) al risultato della convoluzione locale tra il kernel e l’input :
dove:
- è il padding,
- rappresenta la somma pesata delle attivazioni del local receptive field centrato in ,
- è il bias condiviso da tutti i neuroni del layer
📌 Campo recettivo e attivazione
Sebbene la formula calcoli un singolo valore , esso dipende da un’intera regione del layer precedente (il campo recettivo).
La convoluzione è un’operazione locale, mentre la funzione di attivazione è puntuale (agisce solo sul valore convoluto).
📦 Caso 2D
Nel caso bidimensionale con kernel di dimensione e padding simmetrico , la convoluzione è definita da:
Questa formula calcola l’output nella posizione come somma pesata delle attivazioni del local receptive field centrato in quella posizione.