Convolution, in its broadest sense, is a mathematical operator defined on two real-valued functions, and , yielding a third function. To give some intuition for the definition, it helps to examine a specific example that clarifies both its meaning and applications.
Example
Consider a thermometer that measures the outdoor temperature in real time.
Because of sensor imperfections, the readings fluctuate with noise. If one wants to know the true temperature trend, it is not enough to look at a single noisy measurement — instead, it helps to average over recent measurements.To do this more effectively, more recent temperatures should count more than older ones. This is achieved by applying a weighting function , where is the age of the measurement.
The smoothed temperature signal can be obtained by applying this weighted averaging at every instant:
This operation is called convolution. The convolution operation is typically denoted with an asterisk:
In this example:
- is required to be a valid probability density function; otherwise, the result would not constitute a weighted average.
- must be equal to 0 for all negative arguments; otherwise, it would incorporate information from the future, which lies beyond feasible capabilities.
Note
These restrictions are specific to this example. In general, however, convolution is defined for any functions for which the above integral exists and can be employed for purposes other than weighted averaging.
In the terminology of convolutional networks:
- the argument (in this example, the function ) to the convolution is often referred to as the input
- the argument (in this example, the function ) as the kernel
- the resulting output is sometimes called the Feature Map.
Discrete convolution
In the previous example with the thermometer, the assumption of having a measurement available at every instant is not realistic. In practice, when working with data on a computer, time is discretized, and the sensor provides data at regular intervals. A more realistic assumption is that the thermometer produces one measurement per second. The time index can then take only integer values. Under the assumption that both and are defined only for integer , the discrete convolution can be introduced:
Note
Since each element of the input and kernel must be explicitly stored separately, it is usually assumed that these functions are zero everywhere except for the finite set of points at which values are stored. This implies that, in practice, the infinite summation described above can be implemented as a summation over a finite number of array elements.
Info
In Machine Learning applications, the input is typically a multidimensional array of data, and the kernel is a multidimensional array of parameters that are adapted by the learning algorithm. Such multidimensional arrays are referred to as tensors.

2D Discrete Convolution
Convolutions are often applied along more than one axis at a time. For example, if a two-dimensional image is used as input, it is natural to employ a two-dimensional kernel as well:
Convolution is commutative, which means that it can equivalently be written as:
Proof
Definition. For two arrays/functions and :
Step 1. Compute .
Step 2. Change variables.
Let , , soSubstituting:
Step 3. Reorder terms.
Step 4. Rename dummy indices.
The summation indices are dummy variables: they can be renamed without changing the value of the expression.
Thus:Conclusion.
The convolution is therefore commutative.
Note
The formulation is usually easier to implement because the summation indices and correspond to positions in the kernel, which has a fixed and small size (e.g., ).
This means that and always range over the same interval, regardless of the output position .
In the first formulation, by contrast, and index the image itself, so their valid range depends on , making the implementation more cumbersome.
Why the "Flip" in Convolution?
Answer: for commutativity.
The “flip” (using ) is the key mathematical detail that makes convolution a commutative operation, meaning . This is proven by a simple change of variables in the summation as showed in the previous proof. This property is crucial for two main reasons:
Mathematical Consistency: It makes convolution a well-behaved operation that works elegantly with tools like the Fourier Transform (where convolution becomes simple multiplication).
Intrinsic Interaction: It correctly models the interaction between a signal () and a system (). The result is an intrinsic property of their interaction, independent of the frame of reference (“who moves over whom”). In contrast, cross-correlation lacks the flip, is not commutative, and its result depends on the perspective, making it suitable for tasks like template matching.
2D Cross-Correlation
Note
Although the commutative property of convolution is useful for mathematical proofs, it is not usually an important property in the implementation of a neural network.
Many neural network libraries implement a related function called the cross-correlation, which is the same as convolution but without flipping the kernel:
Warning
Many Machine Learning libraries implement cross-correlation but call it convolution.
Important
From now on, the term “convolution” is used to refer to both operations. It will be specified whether the kernel is flipped in contexts where this distinction is relevant.
Info
In the context of Machine Learning, the learning algorithm will learn the appropriate values of the kernel in the appropriate place, so an algorithm based on convolution with kernel flipping will learn a kernel that is flipped relative to the kernel learned by an algorithm without the flipping. It is also rare for convolution to be used alone in machine learning; instead convolution is used simultaneously with other functions, and the combination of these functions does not commute regardless of whether the convolution operation flips its kernel or not
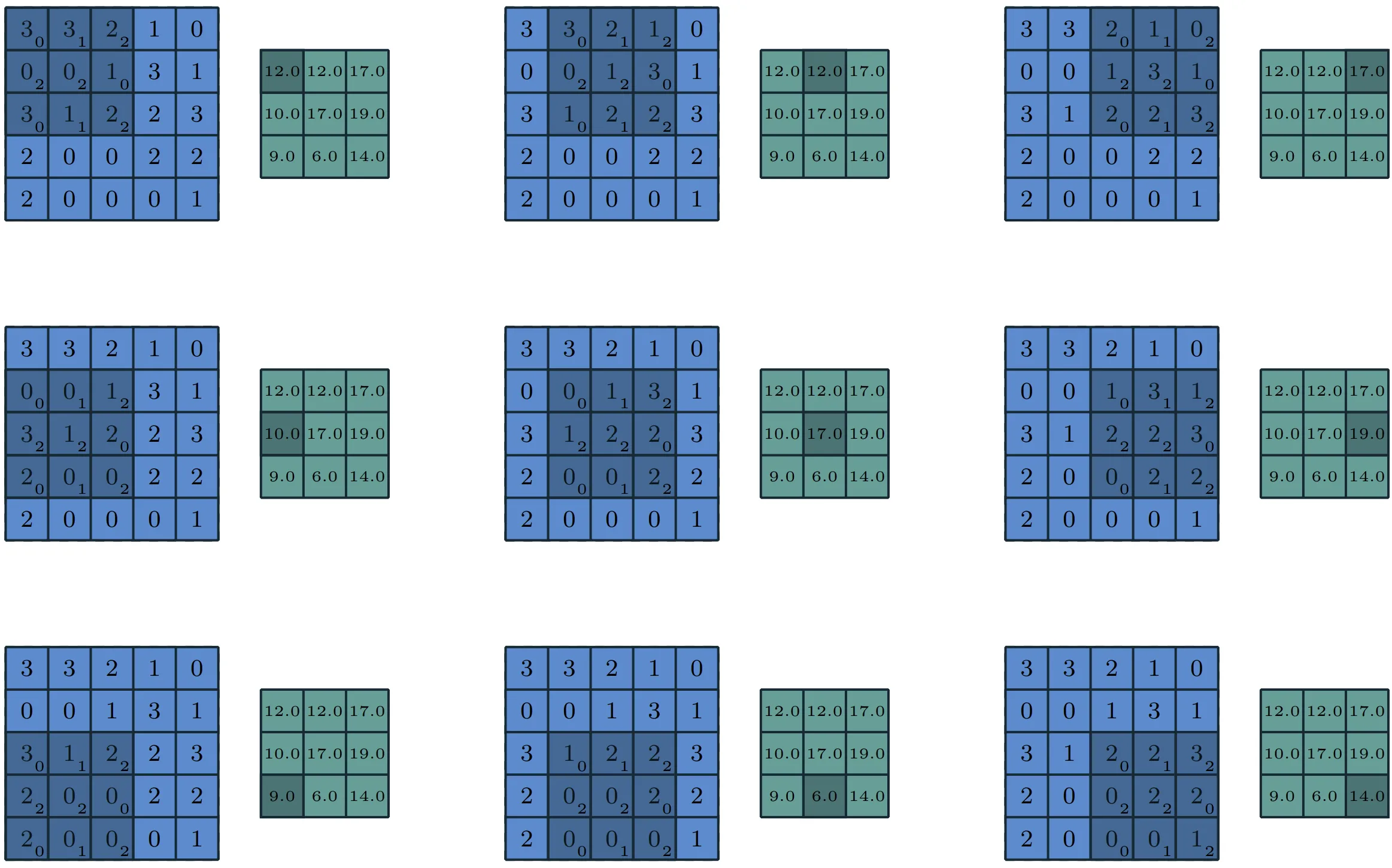 |
|---|
The table above shows two examples of 2D convolution without flipping the kernel. The output is restricted to positions where the kernel fits entirely inside the image; this type of operation is sometimes called a “valid” convolution.
Convolution as matrix multiplication
Important
Discrete convolution can be viewed as multiplication by a matrix, but the matrix has several entries constrained to be equal to other entries.
For example, for univariate () discrete convolution, each row of the matrix is constrained to be equal to the row above shifted by one element.
The Matrix Representation of 1D ‘Valid’ Discrete Convolution
Let’s consider a simple 1D signal and a kernel:
- Input Signal :
- Kernel :
A ‘valid’ convolution (implying no padding or kernel flipping) calculates the output only at positions where the kernel fully overlaps the signal:
This operation can be expressed as a single matrix multiplication () by constructing a corresponding Toeplitz matrix , as follows:
This proves how the sliding operation of convolution can be regarded as a single matrix multiplication.
Toeplitz matrix
Looking at the matrix :
it can be observed the following pattern:
- the second row is exactly the first row shifted one position to the right.
- the third row is the second shifted one position to the right.
This special structure, with constant diagonals, is precisely a Toeplitz matrix.
2D case
In case, convolution corresponds to a doubly block circulant matrix.
The underlying principle remains the same, but the matrix structure becomes more elaborate in order to manage the 2D nature of the image.
In addition to these equality constraints between elements, convolution usually corresponds to a sparse matrix (a matrix whose elements are mostly zero).
This is because the kernel is generally much smaller than the input image.
Looking again at the above Toeplitz matrix , notice how many zeros are present: this is due to the kernel ( elements) being smaller than the input ( elements).
In a real case, with an image of millions of pixels and a kernel of size , the matrix would be enormous but almost entirely filled with zeros.
Note
Any neural network algorithm that works with matrix multiplication and does not depend on specific properties of the matrix structure should work with convolution, without requiring any further changes to the neural network.
Typical convolutional neural networks do make use of further specializations in order to deal with large inputs efficiently, but these are not strictly necessary from a theoretical perspective.