Note
Multi-Layer Perceptrons (MLPs) are universal function approximators, yet their core architectural assumptions make them fundamentally intractable for high-dimensional, topologically structured data like images, audio, or time series.
The paradigm shift toward Convolutional Neural Networks (CNNs) is frequently misrepresented as an attempt to reverse-engineer the visual cortex. In reality, it is a strictly algorithmic evolution, driven by the imperative to resolve three precise mathematical and computational bottlenecks inherent to dense architectures.
🔴 The Loss of Spatial Prior
The Flattening Problem
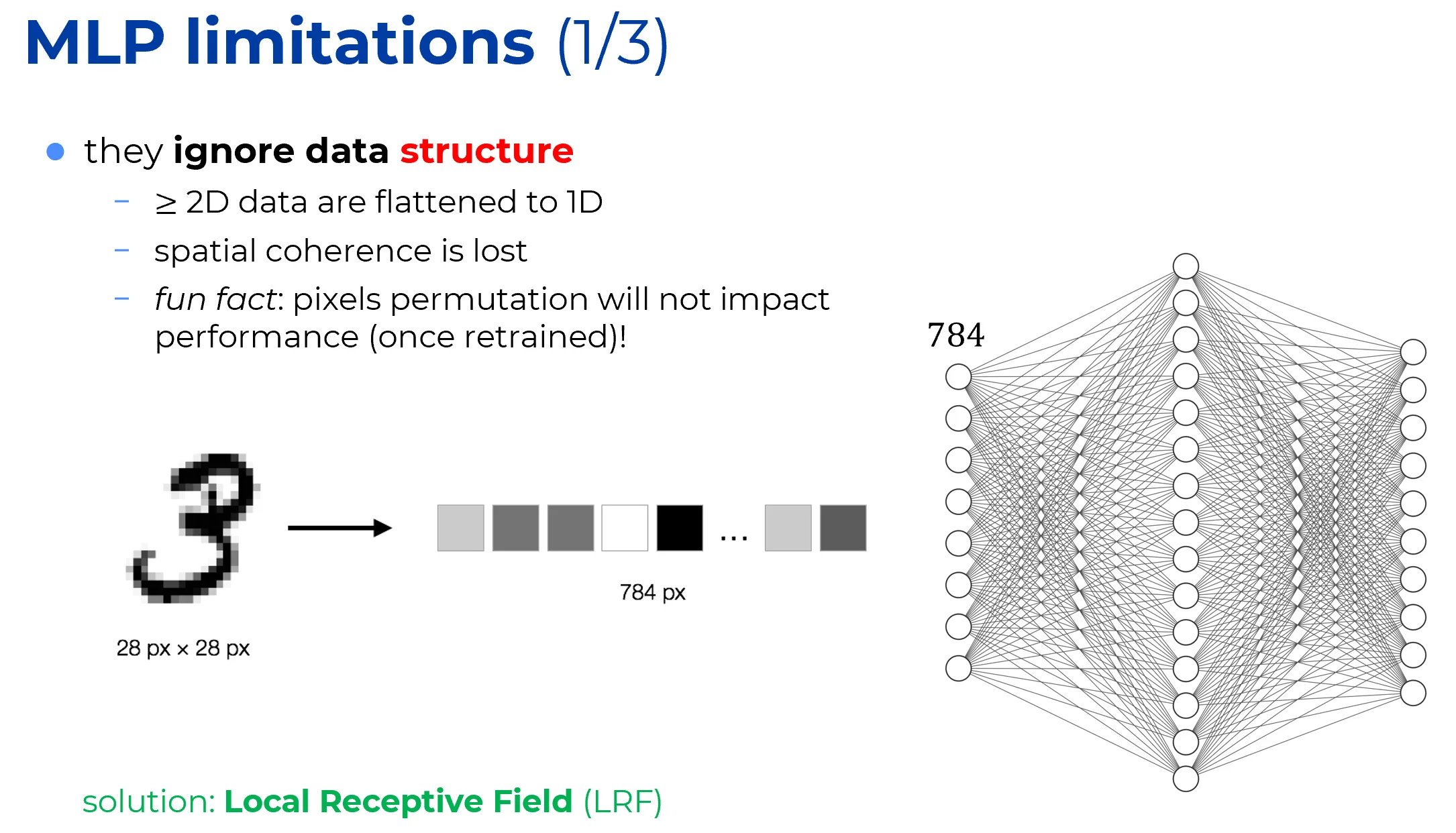
Traditional neural networks, such as MLPs, require their inputs to be flat 1D vectors.
Whenever the input data possesses a topological structure (e.g., a 2D grid of pixels), it must be flattened before it can be multiplied by the weight matrix:
Strictly speaking, flattening does not destroy information in an information-theoretic or set-theoretic sense, as the mapping is perfectly invertible.
The issue is purely architectural: by vectorizing the input, the network discards the spatial prior. The model no longer encodes the inductive bias necessary to exploit the inherent topological structure of the data.

Example: images and spatial priors
In a grayscale image
- neighboring pixels are statistically highly correlated. For example, the value of a pixel at coordinates is strongly related to its immediate vertical neighbor at .
- when the image is flattened into a vector using row-major order, the topological adjacency is destroyed. If is mapped to coordinate , its vertical neighbor is mapped to .
In the first fully connected hidden layer of an MLP,
the weight matrix treats all dimensions of symmetrically. Therefore there is no architectural constraint (no inductive bias) forcing the model to recognize that and represent physically adjacent locations in the original image.
Consequently, spatial locality is not encoded. The network must waste representational capacity to blindly rediscover this topological proximity by inferring it from the training data, rather than having the spatial prior built directly into its architecture.
✅ Solution
Introducing local receptive fields restores the structural prior of the data. Instead of connecting a neuron to the entire flattened input, CNNs restrict each unit’s connections to a small, contiguous spatial neighborhood (e.g., a patch). By doing so, spatial locality is encoded directly into the architecture, eliminating the need for the network to rediscover topological proximity from scratch.
🔴 MLPs do not scale well
Parameter growth in dense layers
For an MLP layer with input dimension and output dimension , the weight matrix contains parameters, plus biases.
Therefore, the parameter footprint scales multiplicatively as .
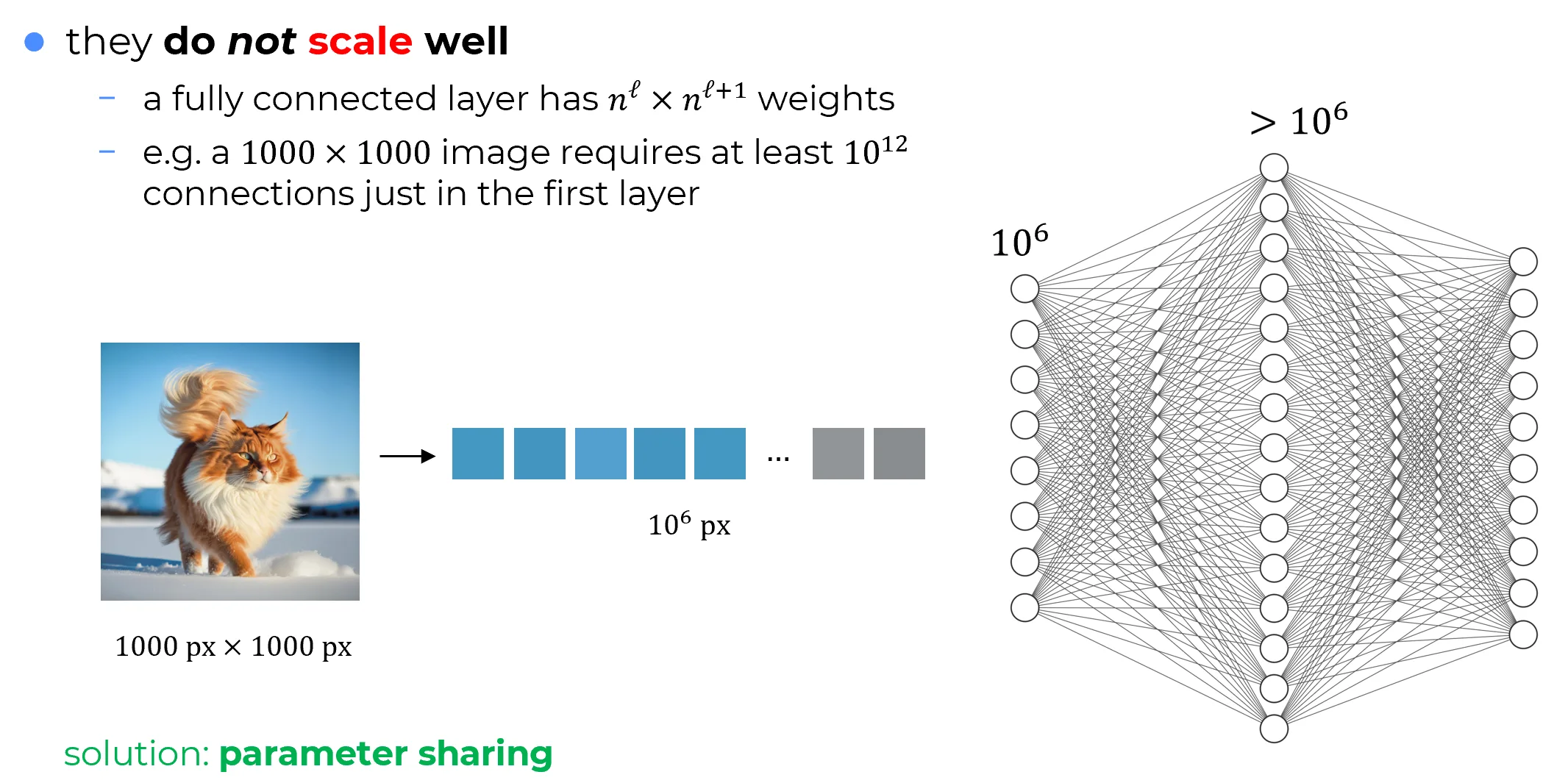
High-resolution images
Consider a modest image.
After flattening, the input vector size isTo prevent a catastrophic information bottleneck, the first hidden layer must maintain a representational capacity comparable to the input, requiring roughly units. The corresponding dense weight matrix contains:
weights.
The VRAM Wall
In standard 32-bit floating-point precision (FP32), storing this single weight matrix requires
Furthermore, this accounts only for the static weights. During training, tracking gradients and modern optimizer states (like Adam’s momentum and variance buffers) inflates this requirement to over 12 Terabytes for a single layer!
Important
Dense connectivity is therefore computationally and memory-wise prohibitive for high-dimensional structured inputs. The limitation is not merely inefficient; it hits a hard, insurmountable physical hardware wall.
✅ Solution
To break the quadratic scaling bottleneck, CNNs abandon the use of independent weights for every spatial location. Instead, they employ parameter sharing.
A single, highly compact set of weights (a kernel, e.g., a matrix) is systematically swept across the entire input volume. Rather than learning independent parameters for a high-resolution image, the network learns just 9 parameters that are reused at every spatial coordinate.
This mechanism does more than just solve the VRAM crisis. It injects a profoundly powerful inductive bias: a visual feature (such as an edge or a texture) learned in one region of the image is automatically detectable anywhere else. This property, known as translation equivariance, is the theoretical cornerstone of modern computer vision.
🔴 The Failure of Hierarchical Composition
The reason MLPs have been proposed and studied for decades is the belief that adding more layers could lead to increasingly sophisticated levels of abstraction.
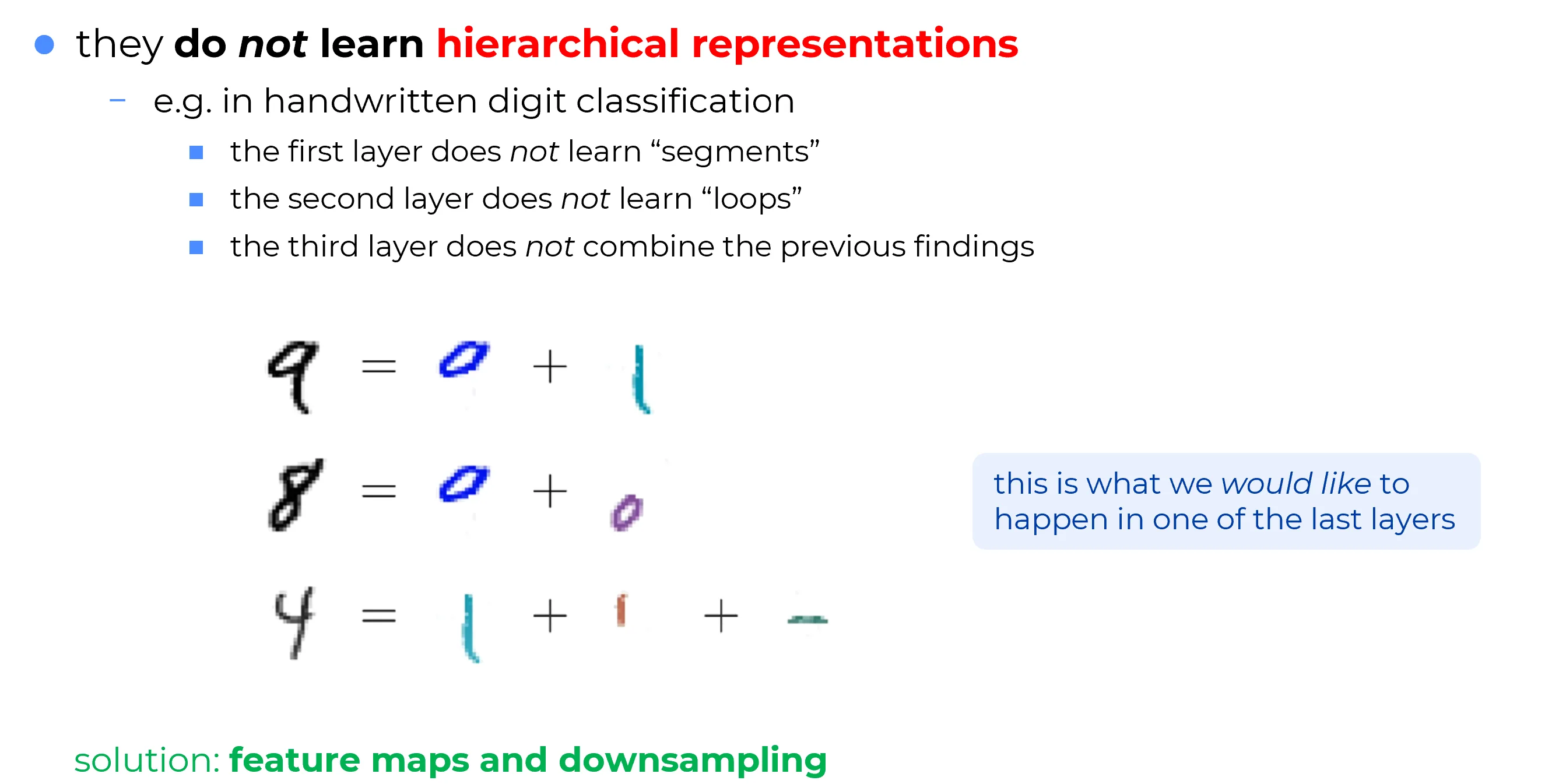
At the visual level, the human brain operates precisely in this manner: effortlessly building sophisticated abstractions from raw sensory data. In a task such as handwritten digit classification, an ideal network is expected to mirror this process by constructing abstractions progressively:
- Layer 1: Detection of local primitive strokes (e.g., vertical or horizontal segments).
- Layer 2: Composition of primitives into intermediate geometric structures (e.g., loops).
- Layer 3+: Aggregation into complete conceptual objects (e.g., the recognition of a ‘9’ as the union of a top loop and a vertical bottom stroke).
The Black Box Reality
While this human-like abstraction is the theoretical goal, traditional MLPs systematically fail to realize it. In practice, MLPs behave as unstructured black boxes. Inspection of their learned weights reveals no evidence of compositional reasoning similar to that of humans; the internal representations are neither interpretable nor easily understandable.
The Absolute Coordinate Bottleneck
This lack of interpretability is not magic, but a direct mathematical consequence of dense connectivity. Because parameters are strictly tied to absolute spatial coordinates, a generic, location-independent feature detector cannot be learned. For instance, a vertical segment located on the left side of a '' is processed by one specific subset of input weights, whereas the identical segment located on the right side of a '' activates an entirely different subset.
The Collapse of Abstraction
In the absence of translation equivariance (weight tying), the concept of a primitive stroke must be redundantly relearned for every possible pixel coordinate. Consequently, representational capacity is exhausted in duplicating low-level detectors, preventing the formation of a unified vocabulary of primitive shapes. Without this foundational vocabulary, intermediate structures (such as loops) are never cleanly extracted, and the intended deep cognitive hierarchy collapses into an inefficient, brute-force template matching system.
✅ Solution
Feature Maps & Downsampling
Convolutional layers resolve this by producing Feature Maps. A single shared kernel detects a “vertical stroke” universally across the entire input domain, ensuring translation equivariance. By interleaving these equivariant feature maps with Downsampling (pooling) operations, the network aggregates local features over progressively larger spatial regions. This explicit architectural mechanism forces the network to naturally build the desired compositional hierarchy: universal local edges are spatially aggregated into shapes, which are ultimately composed into global objects.