You learn by making mistakes
Author's anecdote
It’s mistakes that trigger change. For example, during a Cryptography class exercise, I gave the wrong answer when computing . I was nervous and froze until the professor corrected me. It was very embarrassing. And yet, as frustrating as it was, it’s precisely those clear-cut mistakes that make you learn faster. The next time, I correctly computed . Conversely, failing to learn from one’s mistakes undermines the learning process.
Question
Ideally, one would expect neural networks to learn quickly from their mistakes as well. But what happens in practice?
To answer that, consider the following example.
Toy Example: Sigmoid Neuron with a Single Input
Goal
The goal is to train this neuron to perform a trivial task: mapping the input to the output .
Of course, this is such a simple problem that one could easily determine suitable values for the weight and the bias without relying on any learning algorithm.
Nevertheless, it is instructive to observe how the neuron learns through gradient descent.

Let’s examine in more detail the learning process.
| 🟢MSE, lucky configuration | 🔴 MSE, unlucky configuration |
|---|---|
| Input: → Desired output: | Input: → Desired output: |
| Initial : | Initial : |
| Initial : | Initial : |
| Initial output: | Initial output: |
| Final output: | Final output: |
| Learning rate: | Learning rate: |
| Loss function: quadratic (MSE) | Loss function: quadratic (MSE) |
| ✅ “Fast” learning (though after epochs is hardly impressive)” | ⏳Slow learning: plateau lasting ~150 epochs |
| ✅ Substantial initial gradient | ⚠️ Near-zero initial gradient |
| 📉 The loss function decreases immediately | 💤 Initially flat curve, followed by a delayed descent. |
| 📌 and are updated right from the start | 📌 and remain nearly constant for a considerable number of iterations. |
Why is this behavior unusual?
This behavior is unusual when compared to human learning process.
As noted at the beginning of this section, human beings often learn more quickly when we make big mistakes.
Yet, it has just been showed that the artificial neuron struggles far more to learn when its error is large, much more than when the error is small.
Not an isolated case
This behavior is not limited to this simple example, but also appears in more complex neural networks.
What can be done?
- Why is the learning process so slow?
- Is it possible to find a way to mitigate this slowdown in learning?
🔍 1. Why is the learning process so slow?
Neuron saturation (due to the sigmoid) + gradient structure with MSE
In the case of a single neuron that must map the input to the desired output ,
the slowdown in learning is observed when the initial parameters are and .
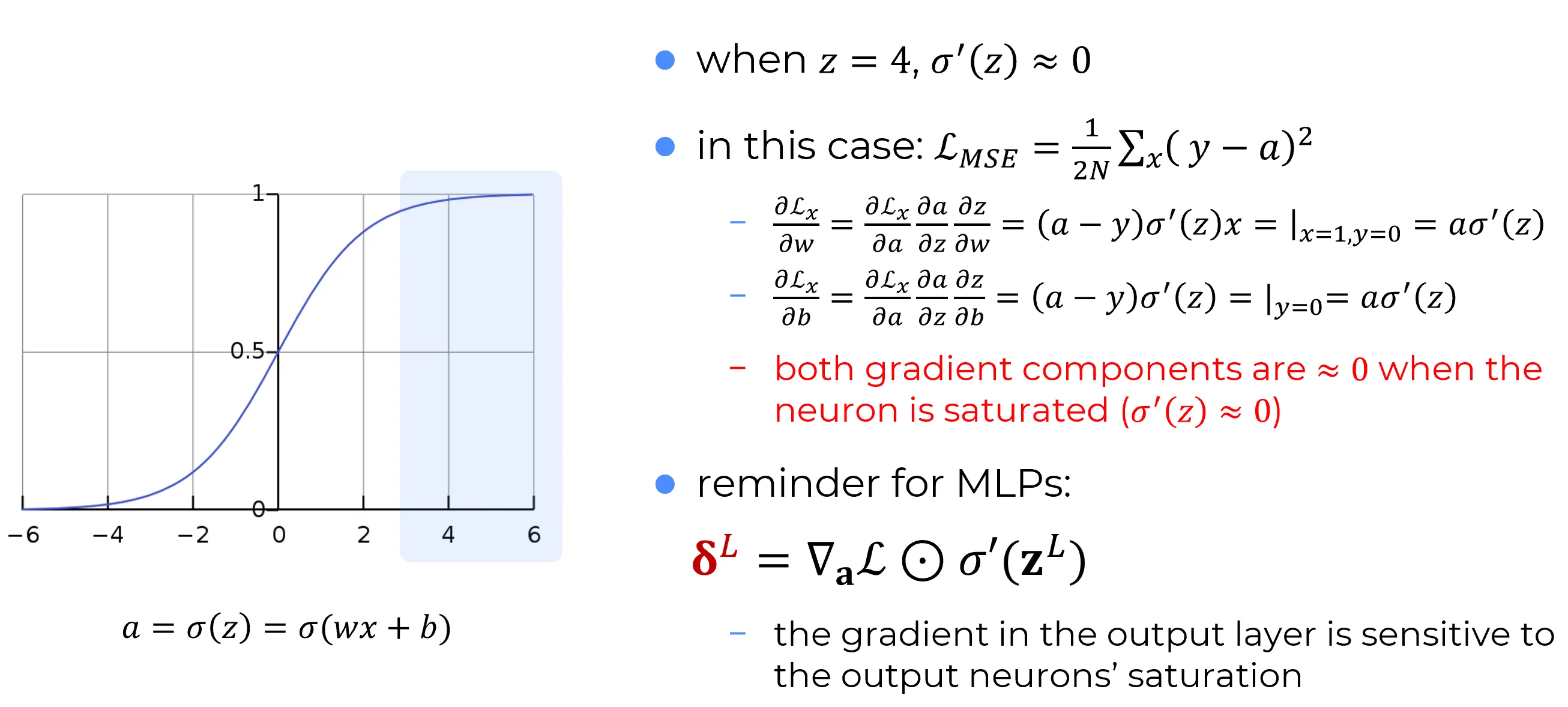
In this configuration, the net input is:A value of places the neuron in the saturation region (see figure below):
the sigmoid function is nearly flat, and its derivative is close to zero.🧠 The crucial point is that when using the MSE loss function,
neuron saturation directly implies the vanishing of the gradient,
because the derivative of the sigmoid (which is close to zero in the saturation region)
appears as a multiplicative factor in all components of the gradient.Specifically, as illustrated below, the partial derivatives of the loss for a single sample, , with respect to the parameters and are:
❗In both gradient components, the derivative appears as a multiplicative factor.
Whenever , the entire gradient vanishes, even if the error is large (i.e., the neuron is making a big mistake).❗⚠️ Therefore, the slowdown in learning is caused by the combination of two factors:
- Neuron saturation:
- Gradient structure induced by MSE, where multiplies every component
🔍 2. Possible solution
Croos-entropy loss
Based on the issues discussed above, one possible solution is to replace the MSE loss function with a different loss function, known as cross-entropy loss.