Gaussian initialization
Nei framework di Deep Learning più diffusi (Keras, TensorFlow, PyTorch), l’inizializzazione predefinita dei parametri di una rete neurale è di tipo gaussiano.
Note
Ogni parametro è inizializzato campionando da variabili aleatorie gaussiane standard indipendenti, caratterizzate da media e varianza .
Avvalendosi del formalismo matematico della teoria della probabilità, si può asserire che:
Ciò significa che ogni singolo parametro della rete (peso o bias) viene inizializzato in modo indipendente dagli altri, campionando da una distribuzione normale standard.
Una scelta semplice, ma che — come si vedrà di seguito — non è ottimale per reti neurali deep.
Perché l’inizializzazione gaussiana?
Le reti neurali prediligono operare su valori numerici compresi in un dato range. Qualora i parametri della rete siano stati inizializzati campionando da gaussiane standard , allora:
- circa il 99.7 % dei parametri ricade nel range che, essendo , corrisponde all’intervallo .
⚠️ Il problema dell’inizializzazione gaussiana dei parametri
Example
Struttura della rete e inizializzazione dei pesi
- Si consideri un MLP con neuroni di input.
- I pesi che connettono il layer di input al primo hidden layer sono inizializzati mediante gaussiane standard .
🎯 Focus: pesi verso un singolo neurone
- Ci si focalizza solo sui pesi che collegano i neuroni di input al primo neurone del layer hidden.
- Il resto della rete viene ignorato per semplicità dell’analisi.
🔧 Configurazione dell’input di training
Si assume un vettore di input in cui ogni neurone di input è:
- Attivo con probabilità ⇒
- Inattivo con probabilità ⇒
⌨ Calcolo input netto del neurone del hidden layer
Si consideri l’input netto al singolo neurone del layer hidden che si sta considerando:
500 termini in tale sommatoria si annullano, poiché il corrispondente input è zero. Pertanto, è una somma di variabili aleatorie :
- 500 termini corrispondenti ai pesi .
- 1 termine aggiuntivo dovuto al bias .
Essendo somma di variabili aleatorie gaussiane indipendenti è anch’essa gaussiana:
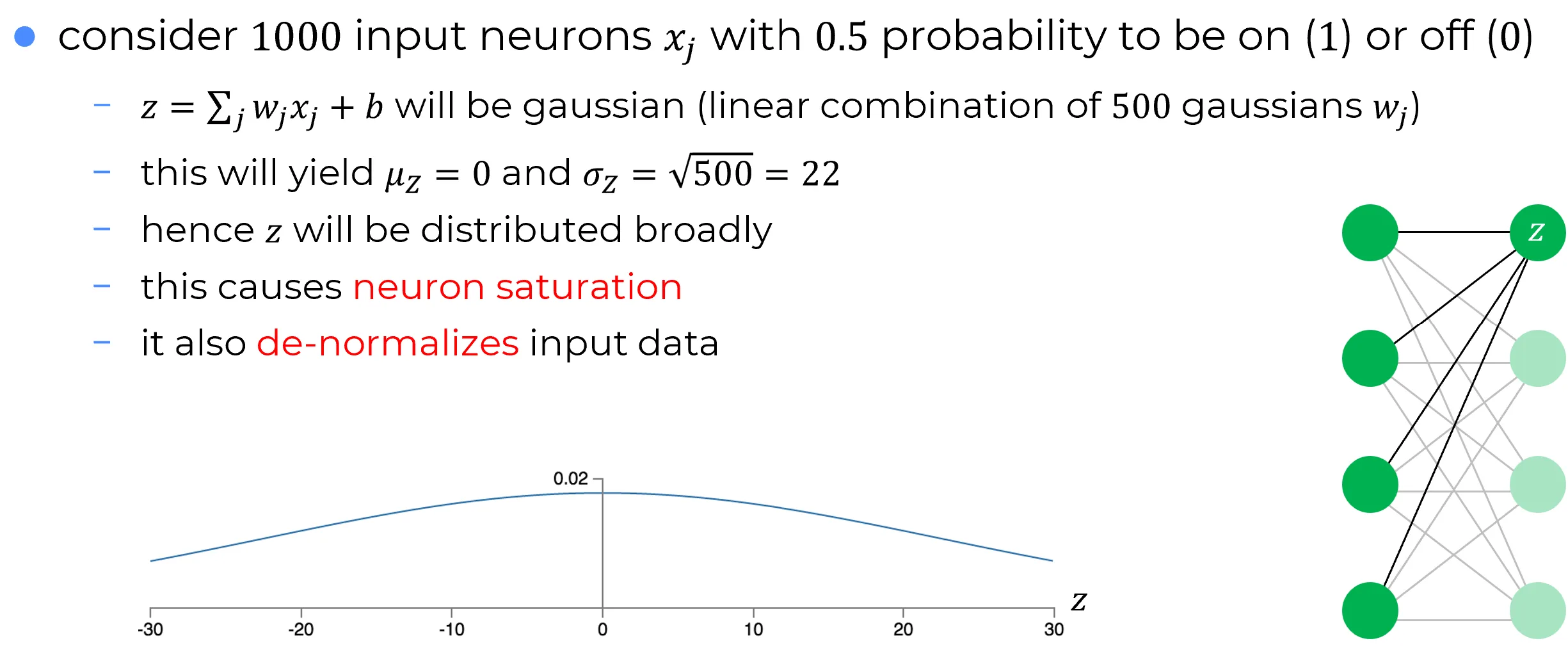
⚠️ Ma c'è un problema...
Dal grafico si osserva che ha un’alta probabilità di essere molto grande (z ≫ 1 o z ≪ -1).
- Se ciò accade, l’output σ(z) del neurone nascosto si avvicina a o → saturazione del neurone.
- In stato di saturazione, piccole variazioni dei pesi producono cambiamenti minimi nell’attivazione .
- Questi cambiamenti minimi si propagano debolmente al resto della rete, con un effetto trascurabile sulla funzione di costo.
- Conseguenza: apprendimento estremamente lento durante l’aggiornamento dei pesi con discesa del gradiente (ciò è stato discusso quando si sono usate le equazioni della back-propagation per mostrare che i pesi in input a neuroni saturati apprendono lentamente).
📌 Osservazione
Questo comportamento è analogo al problema dei neuroni di output saturati discusso in precedenza.
In quel contesto, la saturazione degli output veniva mitigata con una scelta intelligente della funzione di costo (e.g. cross-entropy).
Tuttavia, tale soluzione non risolve la saturazione nei neuroni hidden, poiché:
- La causa è legata all’inizializzazione dei pesi e al forward di con alta varianza.
- Le modifiche alla funzione di costo agiscono a valle, senza influenzare direttamente negli strati hidden.
In altre parole: l’ottimizzazione della funzione di costo “maschera” il problema negli output, ma non lo elimina alla radice negli hidden layer.
💡 Estensione agli Strati Nascosti Successivi
Lo stesso problema non si limita al primo strato nascosto:
- Se i pesi negli strati nascosti successivi vengono inizializzati con gaussiane standard ,
- Le attivazioni in questi strati tenderanno anch’esse a saturare vicino a o .
- Conseguenza: Apprendimento estremamente lento in tutta la rete, non solo nello strato iniziale.
Il cuore del problema rimane l’inizializzazione: il feed forward di segnali con varianza non controllata crea un “effetto domino” di saturazione negli strati profondi.