Optimizer choice is an empirical decision
There is no universally best optimizer
What exists in practice is a small set of strong defaults, a few recurring empirical tendencies, and a long list of task-specific exceptions. Optimizer choice should therefore be treated as a disciplined empirical decision: compare a few well-chosen alternatives rather than commit to one a priori.
Empirical benchmark
The figure below summarizes an empirical comparison across multiple tasks and neural-network architectures.
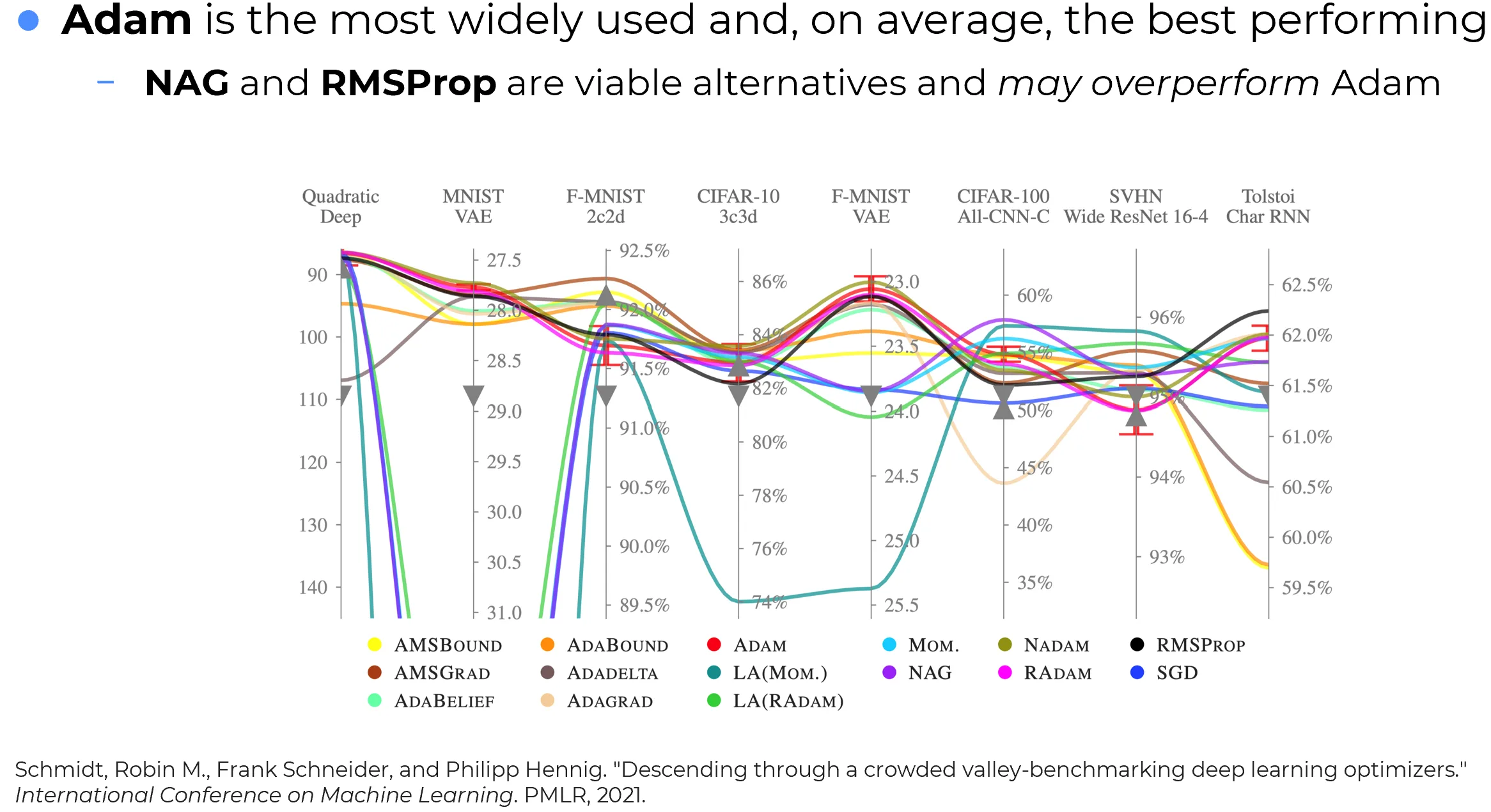
A careful reading of this benchmark supports a balanced conclusion:
- Adam achieves the strongest average performance across the benchmark considered;
- NAG and RMSProp remain strong competitors and can outperform Adam on specific tasks;
- no optimizer dominates uniformly on every problem.
How this figure should be interpreted
The statement “Adam performs best on average” is an aggregate empirical statement, not a theorem: averaged over the benchmark’s tasks, Adam gave the best overall result. It carries no guarantee for any single dataset, architecture, or training regime, and the variance across tasks is typically large enough that the per-task ranking looks quite different from the aggregate one.
First practical conclusion
When no strong task-specific prior is available, Adam (or AdamW) is one of the safest starting points. But it should be treated as a strong default, not as a reason to stop comparing optimizers altogether.
A practical shortlist
In serious experiments, it is usually better to compare a small set of optimizers with clearly different behaviours than to rely blindly on a single default.
A strong shortlist to try first
These three choices cover distinct optimization philosophies:
| family | character | strongest in |
|---|---|---|
| Adam / AdamW | adaptive coordinate-wise step, fast first-iteration progress | random initialization, heterogeneous gradient scales, Transformer-scale models |
| SGD + Momentum / NAG | non-adaptive, smooth trajectory, simpler dynamics | late-stage training, fine-tuning, vision CNNs where final generalization matters |
| RMSProp | adaptive without Adam’s first moment, classical adaptive baseline | RNN-style models, settings with strongly varying per-parameter gradient magnitudes |
Adam vs AdamW: the distinction that matters
If any weight decay is needed (and it usually is), the modern practical default is AdamW, never plain Adam with L2 mixed into the gradient. AdamW decouples weight decay from Adam’s adaptive rescaling, restoring the geometric meaning of weight decay that coupled Adam + L2 distorts. The full mathematical reason is derived in AdamW and in L2 regularization in depth; for the purposes of this note, the recipe is simply: AdamW Adam whenever
weight_decayis set.
Adam as a strong default
Adam is particularly effective when training begins from random initialization. In that regime:
- gradient scales can differ substantially across parameters;
- the optimization trajectory is still far from a well-formed basin;
- rapid coordinate-wise adaptation is often highly beneficial.
Adam combines a first-moment EMA in the numerator, a second-moment EMA in the denominator, and bias correction during the startup phase, which together let it make rapid progress from the very first iterations.
Why Adam became the default
Adam tends to work well immediately, often with less learning-rate fine-tuning than SGD-based methods. The combination of fast startup, low sensitivity to learning-rate choice, and competitive final accuracy on many benchmarks is what cemented its default status in modern deep-learning practice. The cost is a slightly more elaborate state machine and additional memory (see below).
Late-stage training and fine-tuning: where SGD still wins
The situation changes once the network is no longer at random initialization. Suppose that:
- the model has already been trained;
- the parameters already lie in a reasonably good region of the loss landscape;
- the goal is no longer broad exploration, but rather controlled exploitation.
In that regime, Adam may still work well, but its advantages are no longer automatic. The precise concern is the following:
- Adam rescales updates coordinate-wise using recent gradient statistics;
- this strong adaptivity can accelerate fitting to a new objective or new dataset;
- the same aggressiveness can move the model toward a solution that adapts quickly while preserving less of the structure learned before, or that generalizes less well.
By contrast, SGD with momentum or NAG often produces a more conservative trajectory in late-stage training. In some settings (especially in computer vision, with CNNs trained on ImageNet-style benchmarks), this leads to better final generalization or more stable fine-tuning behaviour.
Fine-tuning takeaway
In fine-tuning or late-stage exploitation, Adam should not be assumed to be automatically optimal. Its adaptive speed can be an advantage, but in some cases SGD + Momentum/NAG yields a better final trade-off between adaptation and preservation. The empirical pattern “Adam for pre-training, SGD for fine-tuning” is common enough in the literature to be worth testing explicitly at the start of any fine-tuning project.
An empirical tendency, not a hard law
The outcome depends on:
- the amount of new data,
- the similarity between pretraining and target data,
- the learning-rate schedule,
- the regularization strategy,
- the extent of adaptation desired.
Hidden costs: memory and computation
A practical consideration that is easy to overlook when reading optimizer-comparison plots is memory footprint. Each optimizer carries internal state proportional to the number of parameters, and the multiplicative factor varies significantly across families.
Memory cost per parameter
optimizer extra state per-parameter memory (multiples of ) SGD (no momentum) none (parameters only) SGD + Momentum / NAG velocity RMSProp second-moment EMA Adam / AdamW first-moment EMA and second-moment EMA For a model with parameters in , Adam’s state translates into roughly of GPU memory just for the optimizer, on top of the parameters themselves and the activation tensors required by backpropagation. This is one reason memory-efficient variants of Adam (Adafactor, 8-bit Adam, Lion) attract attention at large scale: they trade some of Adam’s empirical strength for substantially smaller optimizer state.
The compute per step is comparable across all four (a single forward / backward pass dominates by orders of magnitude), so the operative distinction is memory, not throughput.
Warmup and learning-rate scheduling are not separate decisions
Optimizer choice and learning-rate schedule are coupled. Two stylized observations:
Adam-family optimizers benefit strongly from linear warmup
Adam and AdamW compute adaptive denominators from running gradient statistics. Early in training these statistics are noisy and biased, and starting at full can produce unstable updates. A short linear warmup (typically to of total iterations) ramps the learning rate from to before the main schedule kicks in. Without warmup, modern Transformer-scale training with Adam/AdamW is often unstable or fails outright. See Cosine annealing for the standard warmup + cosine recipe.
SGD with momentum tolerates simpler schedules
SGD-family optimizers are typically run with a constant learning rate, a step decay, or a single cosine cycle without warmup. The absence of adaptive moments means there is no startup-bias issue to compensate for, and the per-step dynamics are stable from iteration zero given a well-chosen .
For a treatment of the schedule options themselves, see Choosing an LR scheduler.
Starting hyperparameters
The decision-making above is much easier when the comparison can be done quickly. The values below are reasonable starting points; they are not optimal for every task but they are very rarely catastrophic, and they give a solid baseline to iterate from.
| optimizer | starting lr | momentum / | weight_decay | notes | |
|---|---|---|---|---|---|
| SGD + Momentum | (CNN) / (MLP) | n/a | pair with step decay at % of training | ||
| NAG | same as SGD+Momentum | (Nesterov flag set) | n/a | small empirical edge over plain momentum | |
| RMSProp | or | classical default for RNNs | |||
| Adam | (use AdamW instead if decay desired) | bias-corrected; warmup recommended | |||
| AdamW | (CNN/MLP) / (Transformer) | (CNN) / (LLM) | to | the modern default; pair with warmup + cosine |
Where these come from
The values above match the published recipes for landmark architectures (ResNet for CNNs, BERT and GPT for Transformers, LSTM language models for RNNs). They are starting points that survive cross-task transfer reasonably well; for production training, all of them should be tuned on a validation set, ideally with a simple grid or Bayesian sweep.
Decision recipe
A pragmatic decision rule, in increasing order of compute investment:
- Quick prototype: start with AdamW at
lr=1e-3,weight_decay=1e-2, no scheduler. This trains nearly anything to a reasonable baseline in minutes. - First serious experiment: add a linear warmup + cosine decay schedule (see Cosine annealing); keep AdamW.
- Strong baseline: compare against SGD + Momentum (or NAG) with appropriate
lrand step decay. Especially worth doing if the task is fine-tuning, a CNN on ImageNet-style data, or a problem where final-accuracy parity matters more than convergence speed. - Final tuning: treat optimizer choice as a hyperparameter-selection problem, not as a fixed ideological commitment. Compare the two or three best candidates from steps 1–3 under their respective best schedules and hyperparameters; pick the winner on validation accuracy.
Summary
The most reliable practical view is:
- AdamW is the strongest and most reliable default optimizer in modern deep learning.
- SGD + Momentum / NAG and RMSProp remain serious alternatives and can outperform AdamW in specific regimes (most notably late-stage fine-tuning and certain computer-vision benchmarks).
- No optimizer is uniformly best across all tasks; the per-task variance across the empirical benchmark is large.
The right habit is not blind loyalty to one optimizer, but a short and well-designed comparison among a few strong candidates, with schedule, warmup, weight decay, and memory budget all treated as part of the comparison rather than as fixed choices made separately.