Introduction to Diffusion Models
Diffusion Models are generative models that model a target distribution by learning a denoising process at varying noise levels. This concept is inspired by nonequilibrium thermodynamics, in which a physical system starts from a structured, low-entropy state that is gradually “diffused” or driven toward a more disordered, high-entropy equilibrium state over time. In principle, the system can be steered back toward a more ordered configuration, although this typically requires precise control and information about the underlying dynamics. In diffusion-based generative models, we begin with real data and then apply a stochastic “diffusion” of noise step-by-step. Each step slightly corrupts the data by adding Gaussian noise to arrive at a highly noisy, nearly featureless distribution that is mathematically close to a pure Gaussian distribution .
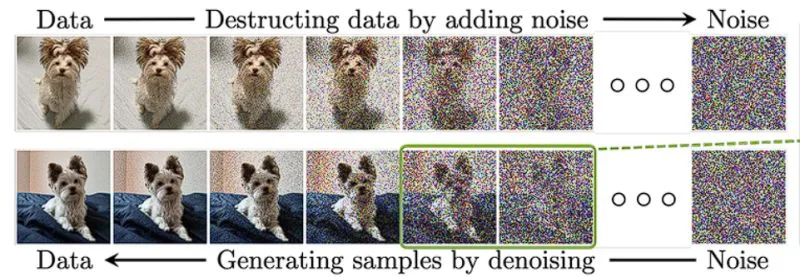
Our goal is to understand the mathematics behind this “denoising” magic, starting with a core concept in generative modeling: the ELBO.
1.1. The Evidence Lower Bound (ELBO) - A Quick Refresh starting from VAEs

In many generative models, like VAEs, we want to model the true data distribution .
The likelihood function tells you: How likely it is to observe your data, given some parameter values.
Directly maximizing the likelihood can be tricky. VAEs introduce a latent variable and aim to maximize . This is often intractable, so we maximize a lower bound instead, called the Evidence Lower Bound (ELBO):
Let’s start by rewriting the log-likelihood of the data :
We introduce an approximate posterior (the “encoder”) and becomes our “decoder”. The ELBO is derived as:
Using Jensen’s inequality ():
This can be rewritten into a more familiar form:
Here:
- is the reconstruction likelihood: how well can we reconstruct from sampled from our encoder ?
- is a Kullback-Leibler (KL) divergence that acts as a regularizer, pushing the distribution of latent codes to be similar to a prior distribution (often a standard Gaussian).
What is ?
It’s defined as:
It measures how much the approximate posterior differs from the prior . It is always non-negative, and equals zero if the two distributions match exactly.
Why choose as a standard Gaussian?
Choosing as a standard Gaussian simplifies the KL divergence term and ensures that the latent space is well-regularized. This choice also facilitates the reparameterization trick, which allows us to backpropagate through the sampling process. By reparameterizing as , where , we can compute gradients with respect to and directly, enabling efficient optimization.
1.2. ELBO for Sequential Latent Variables (Precursor to Diffusion)
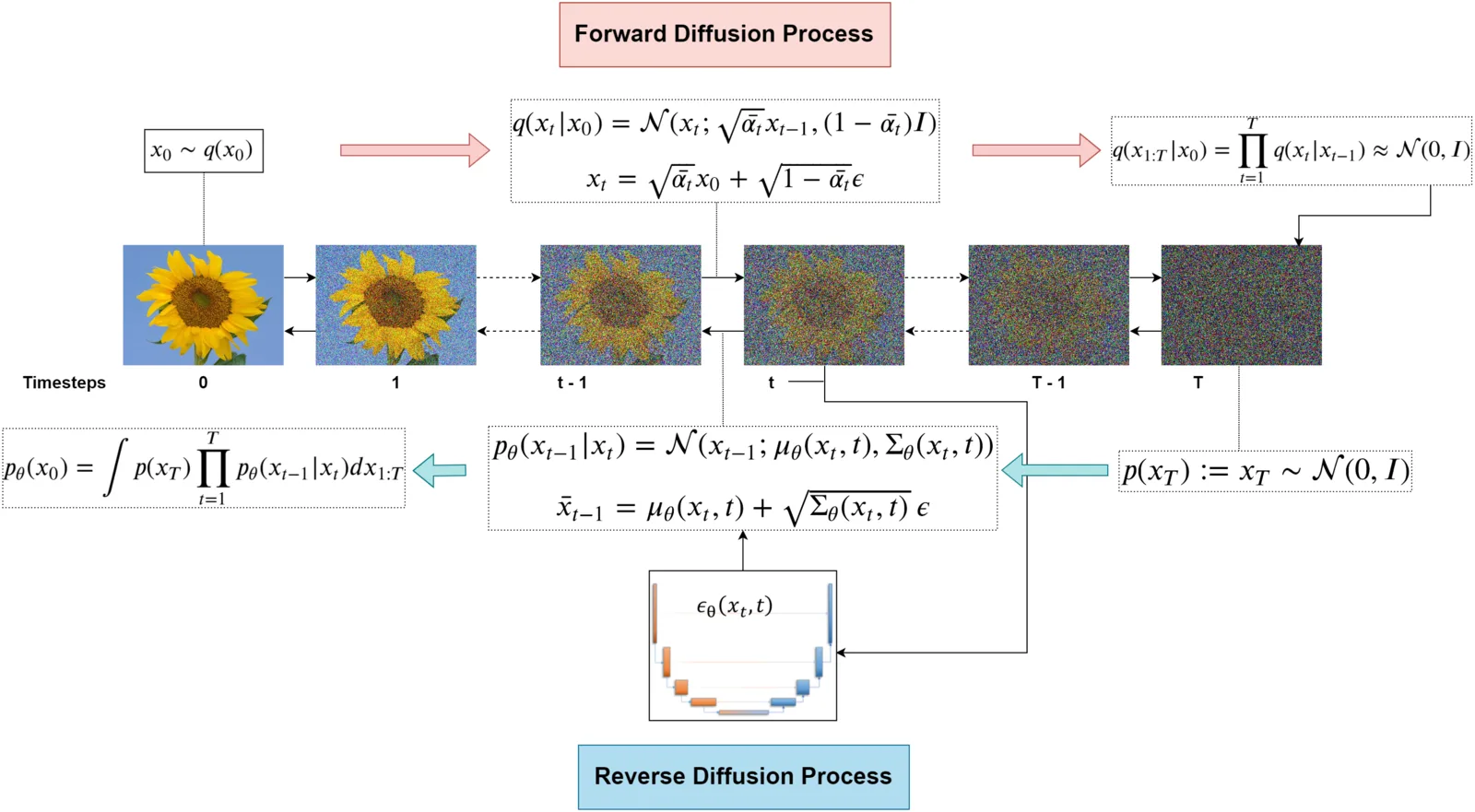
Diffusion models can be seen as a type of latent variable model, but with a sequence of latent variables .
- is our original clean data.
- are increasingly noisy versions of .
- is ideally pure noise (e.g., a sample from ).
The goal is still to maximize . We can write a similar ELBO for this sequence: Let denote the sequence . We want to maximize . We can express this using the chain of latent states: , where . The ELBO becomes:
Here, is the (fixed) forward noising process, and is the model we want to learn (the reverse denoising process).
1.3. The Two Markov Chains behind Diffusion Models
Diffusion models are characterized by two key processes:
a. Forward Process (Diffusion Process) ➡️
This process gradually adds Gaussian noise to an image over timesteps. It’s a fixed Markov chain, meaning it’s not learned. It’s defined as:
Here, are small positive constants representing the noise schedule (variance). Let . Then:
A wonderful property of this process is that we can sample directly from at any timestep , without iterating through all intermediate steps. Let :
This means we can get by:
This is super useful for training! We can pick any from our dataset, pick a random , and generate a noisy in one shot.
b. Reverse Process (Denoising Process) ⬅️
This process learns to reverse the noising steps. It’s also a Markov chain, aiming to predict the slightly less noisy given the noisier . This is where our neural network (parameterized by ) comes in:
The goal of training is to make a good approximation of the true (but intractable) reverse conditional .
1.4. Decomposing the ELBO for Diffusion Models
Let’s expand the ELBO. The joint probability is given by the reverse process: where is a prior, usually .
The forward process is given by: (where is given for ).
The ELBO can be rewritten and decomposed into several terms (after some algebra!):
A more convenient decomposition for minimization (we minimize ) looks like this:
Let’s break down these terms that we want to minimize:
- : This is a reconstruction term. It measures how well the model can reconstruct the original data from the first noisy version .
- for : These are KL divergence terms. They measure the difference between the model’s reverse step and the true posterior of the forward process. This true posterior tells us what should look like given and the original clean image .
- : This term compares the distribution of the final noised sample (derived from ) with a prior (e.g., ). Since the forward process is designed such that is approximately for large , and is chosen as , this term is often small and doesn’t depend on , so it’s usually ignored during training.
The core of the learning happens in the terms (and , which can be seen as a special case).
Why is a normal Gaussian as ?
As approaches infinity, the forward noising process adds so much noise that the original data is completely obliterated. The resulting distribution converges to a standard Gaussian due to the central limit theorem and the design of the noise schedule. This ensures that , the prior for the reverse process, can also be modeled as , simplifying the training and sampling processes.
Step-by-Step Explanation:
Step 1: Analyze as :
Typically, the noise schedule is defined such that:
- Each is small and satisfies .
- As , the cumulative product approaches zero:
Step 2: Evaluate mean and covariance of in this limit:
Given the distribution:
- Mean: As ,
- Covariance: As ,
Thus,
Final Result:
Therefore, the final limiting behavior is elegantly expressed as:
1.5. Analyzing the KL Divergence Terms ()
To minimize , we need to characterize . Using Bayes’ theorem:
Since the forward process is Markovian, . We know , , and are all Gaussians. After some lovely math involving products of Gaussian PDFs and completing the square, we find that is also a Gaussian:
Where the mean and variance are:
Our model’s reverse step is . The KL divergence between two Gaussians and simplifies nicely. If we fix the variance of our model (e.g., set or , as is common), the KL divergence term becomes proportional to the squared difference between the means:
So, we need our neural network to predict .
1.6. Parameterizing the Mean with Noise Prediction
This is where the magic simplification happens! The mean depends on , which is not available during the reverse (generation) process. However, during training, we do have . Recall the forward sampling equation: . We can re-arrange this to express in terms of and the noise :
Now, substitute this expression for back into the equation for . After some algebraic simplification, can be re-written as:
Instead of making our neural network directly predict this complex mean, we parameterize it to predict the noise that was added at step . Let be the noise predicted by our neural network (usually a U-Net architecture). We define our model’s mean as:
This is a key implementation point! Our network learns to predict noise.
Now, the squared difference term in becomes:
So, the loss term (for ) becomes:
The term (reconstruction) can also be formulated in a similar way or handled by this noise prediction framework at .
1.7. The Simplified Loss Function (The Big Reveal!)
The full ELBO contains these weighted noise prediction terms. However, Ho et al. (2020) in their paper “Denoising Diffusion Probabilistic Models” (DDPM) found that a much simpler, unweighted version of this loss works remarkably well in practice. They propose to train the model by minimizing the following simple mean squared error between the true noise and the predicted noise:
This is it! This is the objective function that most diffusion models are trained on. We simply:
- Pick a random training image .
- Pick a random timestep .
- Sample a random noise vector .
- Create the noised image .
- Feed and to our neural network .
- Ask the network to predict the original noise that was added.
- The loss is just the Mean Squared Error between the true and the predicted .
It’s beautifully simple and incredibly effective.
1.8. Why this Simplification Works and Implementation Details
- Why simplify? The weighting factors can be complex to tune, and empirically, the unweighted version performs very well and is more stable. It effectively re-weights the importance of different timesteps.
- Choice of : The variance of the reverse process is often set to or . The DDPM paper found that both choices work well.
1.9. Deriving the Reverse Sampling Formula
Let’s derive the formula for sampling during the reverse process step-by-step:
-
First, recall that the true posterior for the reverse process is:
-
Where the mean can be derived using Bayes’ rule:
-
We can’t use this directly in practice, since we don’t know the true during sampling. However, given our noise prediction network, we can estimate from :
-
Substituting this estimate into the formula for , and after algebraic simplification, we get the DDPM sampling equation:
Where is the variance term from the true posterior.
This formula is the heart of the DDPM sampling process. Notice how:
- The first term denoises the noisy sample using our predicted noise
- The second term adds a controlled amount of new noise to maintain the stochastic nature of the process
When we apply this formula step by step from down to , we gradually transform random noise into a coherent data sample.
Beta Schedules: Designing the Noise Trajectory
The choice of noise schedule significantly impacts sample quality and training dynamics:
-
Linear schedule: A simple linear increase from 0.0001 to 0.02 (original DDPM paper)
- increases linearly from to
- Easy to implement but not optimal for all data types
-
Cosine schedule: A smoother, more natural decay proposed by Nichol & Dhariwal
- Uses cosine function to create a schedule that adds noise more gradually at first
- Better preserves data structure in early timesteps
- Improves sample quality
-
Learned schedule: The values are optimized jointly with model weights
- More complex but can adapt to specific data characteristics
- Requires additional training complexity
The optimal schedule balances between preserving low-frequency information early in the diffusion process and adding sufficient noise to cover the data distribution.
1.10. Implementation Details
Pseudo-code for Training
# Training Algorithm
for each training step:
x_0 = sample_from_data() # Original image
t = random_timestep(1, T) # Random timestep
epsilon = sample_noise() # Noise ~ N(0, I)
# Generate noised image
x_t = sqrt(alpha_bar[t]) * x_0 + sqrt(1 - alpha_bar[t]) * epsilon
# Predict noise using the model
epsilon_pred = model(x_t, t)
# Compute loss
loss = mse_loss(epsilon, epsilon_pred)
# Update model parameters
optimizer.step(loss)Pseudo-code for Sampling
# Sampling Algorithm
x_T = sample_noise() # Start with pure noise
for t in range(T, 0, -1):
epsilon_pred = model(x_t, t) # Predict noise
mu_t = (1 / sqrt(alpha[t])) * (x_t - beta[t] / sqrt(1 - alpha_bar[t]) * epsilon_pred)
if t > 1:
z = sample_noise() # Add noise for intermediate steps
else:
z = 0 # No noise at the last step
x_t_minus_1 = mu_t + sigma[t] * z
x_0 = x_t_minus_1 # Final generated imageReferences
- Ho, J., Jain, A., & Abbeel, P. (2020). Denoising Diffusion Probabilistic Models. arXiv preprint arXiv:2006.11239.
- Kingma, D. P., & Welling, M. (2013). Auto-Encoding Variational Bayes. arXiv preprint arXiv:1312.6114.
- Sohl-Dickstein, J., Weiss, E., Maheswaranathan, N., & Ganguli, S. (2015). Deep Unsupervised Learning using Nonequilibrium Thermodynamics. arXiv preprint arXiv:1503.03585.