While Denoising Diffusion Probabilistic Models (DDPMs) have shown remarkable success in generating high-fidelity samples, they typically require many sampling steps (e.g., or more) due to their stochastic nature, making generation slow. Denoising Diffusion Implicit Models (DDIMs), introduced by Song, Meng, and Ermon (2020), offer a significant improvement by formulating a non-Markovian generative process that allows for much faster sampling with comparable or even better sample quality.
A key insight of DDIM is that the DDPM objective function does not strictly depend on the Markovian nature of the forward noising process. This allows DDIM to use the same trained DDPM model but employ a different, more flexible sampling procedure.
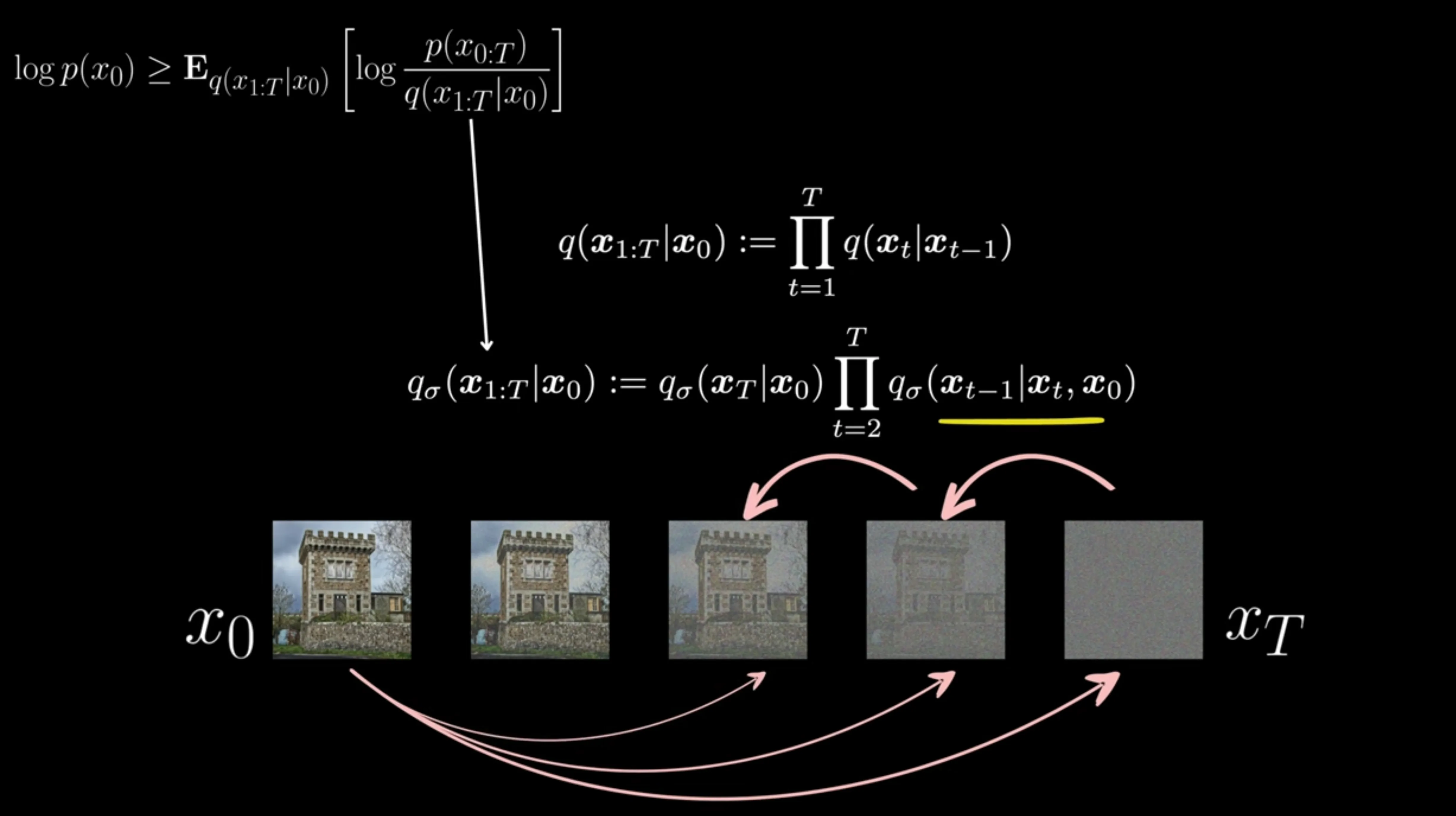
Credits: https://www.youtube.com/watch?v=n2P6EMbN0pc&t=805s
2.1. From DDPM to DDIM: The Core Idea
Recall that DDPMs define a forward process and learn to approximate the reverse process . The DDPM objective (simplified loss) is:
This objective only depends on the marginal . It does not explicitly depend on the step-by-step Markovian structure of .
Let’s understand why:
Recall the KL divergence term in the DDPM objective:
in which the forward process is defined as:
Where the mean and variance are:
and the reverse process is defined as:
where is the learned mean and is a fixed variance.
Let’s define a more general forward process in terms of matrices and :
where and are matrices that can be learned or defined.
and at the same way a more general reverse process:
The KL term in this case becomes:
And since in many DDPM implementations ignore the variance term, we can see that the objective function is not strictly dependent on the Markovian nature of the forward process. The DDPM objective can be optimized with respect to any forward process that has the same marginal distribution as the original DDPM.
DDIM leverages this by proposing a class of non-Markovian forward processes that share the same marginals but lead to a different generative process. The remarkable part is that the same network trained for DDPM can be used.
2.2. DDIM Forward Process: Non-Markovian Sampling
The author of DDIMs propose the following Non-Markovian forward process:
with this new kernel definition:
As discussed in Sec. 2.1 if we can prove that:
we don’t need to train a different model and we can reuse the DDPM one.
Mathematical Proof
Important
Okay, let’s detail the proof. The core of this demonstration is to show that the marginal distribution for any timestep in the DDIM non-Markovian forward process has the same form as in the original DDPM formulation. This is key to why a DDPM-trained model can be used with DDIM. We will use a proof by induction, working backward from timestep .
Recall: Gaussian Marginalization Rule
Before diving into the proof, let’s state the Gaussian marginalization rule that we will use. If we have two random variables and such that:
- The distribution of is Gaussian:
- The conditional distribution of given is also Gaussian and linear in :
Then, the marginal distribution of , denoted , is also Gaussian and is given by:
In our context, for the inductive step:
- will represent (the state at timestep ).
- will represent (the state at timestep ).
- will be .
- will be the DDIM kernel .
- will be the target marginal .
Proof by Induction
We want to prove the following statement for all :
This states that the distribution of the noisy sample given the original data is a Gaussian with mean and covariance $(1-\bar{\alpha}_k)I`.
1. Base Case:
Let’s consider the timestep . The DDIM forward process starts with . It is defined to match the DDPM marginal at the final timestep :
Thus, holds.
2. Inductive Hypothesis:
Assume that is true for some timestep , where . This means:
In terms of our Gaussian marginalization rule ():
3. Inductive Step:
We need to show that is true, i.e., .
We use the DDIM non-Markovian kernel :
Let’s identify , , and from this kernel for our form, where and . The mean is:
So:
Now, we apply the Gaussian marginalization rule to find .
Mean of :
The two terms with fractions cancel out:
This matches the mean required for .
Covariance of :
Since :
This matches the covariance required for .
Therefore, we have shown that if is true, then is also true:
4. Conclusion of Induction:
Since the base case holds, and we have shown that for , by the principle of mathematical induction (working backwards from down to ), the statement is true for all .
This means that for any timestep , including as shown in the user’s provided text and image, the marginal distribution under the DDIM non-Markovian process is indeed . This is the same form as the marginals in the original DDPM, which is why the same trained network can be used for DDIM sampling. The objective function only depends on these marginals, not the specific step-by-step structure of the forward process.
2.3. The DDIM Generative Process
The DDIM forward process impose a generative process (reverse process) that is a specific instance of a more general family. Instead of the DDPM sampling step:
where for DDPMs.
DDIM introduces a more general sampling step. The key is how is constructed from and the predicted noise .
Starting from the DDIM kernels:
and since we proved that the marginal is the same:
and we know that we are minimizing the KL with the reverse process , so:
we end-up to DDIM sampling step via the reparameterization trick:
where , is a new parameter controlling the stochasticity of the process and:
The Parameter: Bridging DDPM and DDIM
The stochasticity parameter is defined as:
Here, (eta) is a hyperparameter that interpolates between different processes:
-
If : Then . The DDIM sampling step becomes:
With some algebra, one can show that . Substituting and simplifying, this recovers the DDPM sampling equation:
So, DDPM is a special case of DDIM when . This process is stochastic.
-
If : Then . The DDIM sampling step becomes deterministic:
Substituting :
This is the Denoising Diffusion Implicit Model (DDIM). Since no random noise is added at each step (beyond the initial ), the entire generation process from to is deterministic given the model .
This means that for a fixed starting noise , DDIM () will always produce the exact same image .
2.4. Why is this process called “Implicit”?
The term “implicit” in DDIM refers to the fact that the model implicitly defines a generative process. Unlike DDPMs, where the reverse process is explicitly defined as a Gaussian with learned mean and fixed variance, DDIMs with define a deterministic mapping . This mapping generates samples without explicitly defining their probability density. The probability is defined implicitly through the transformation where .
2.5. Faster Sampling with DDIM
The original DDPM paper (Ho et al., 2020) required or more steps for generation. DDIM can produce high-quality samples in as few as to steps. This speed-up is a major advantage.
How is this achieved? Instead of sampling at every timestep from the original DDPM schedule, DDIM allows sampling from a subsequence of timesteps , where . For example, if and we want steps, we can choose a subsequence like .
The DDIM update rule uses and (where is the current step and is the previous step in the subsequence). The prediction of remains the same:
And the update to get (for ):
Why does this work?
- Consistency of Prediction: The model is trained to predict the noise component, which in turn allows a prediction of . This prediction of is relatively stable across different values. DDIM leverages this by directly using the predicted to guide the trajectory towards a cleaner image.
- No Compounding Noise (for ): In DDPM, noise is added at each step (). Small errors in can be amplified by this noise. In deterministic DDIM (), no new noise is injected. The process directly “denoises” towards the predicted . This allows for larger “jumps” between timesteps without significant degradation in quality. The path from to is much smoother.

Credits: https://www.youtube.com/watch?v=IVcl0bW3C70
2.6. Deterministic Process, Invertibility, and Encoding
The deterministic nature of DDIM (when ) implies a unique mapping from , which is also invertible. This enables a key feature: encoding a real image into its corresponding latent representation .
Encoding: Because the model is trained to predict the noise component from a noisy image at any timestep , we can use the same model in reverse, simply by shifting the timestep index forward.
If the reverse (denoising) step is:
Then the encoding (noising) step becomes:
Where:
In this formulation, we are leveraging the fact that was trained to predict the noise given and , so during encoding we can feed in with to simulate the forward trajectory of noising.
By iteratively applying this forward deterministic step starting from , we obtain a latent representation such that when passed through the DDIM generative process, it will reconstruct with high fidelity.
This property is extremely useful for:
- Image Reconstruction: Verifying model fidelity.
- Image Manipulation/Editing: Modifying the latent code and then decoding can lead to controlled edits of the original image. For example, one can interpolate between latent codes of two images.
- Semantic Latent Spaces: The structure of the latent space learned via DDIM can capture semantic features of the data.
2.7. DDIM vs DDPM: A Quick Comparison
| Feature | DDPM | DDIM () | DDIM () |
|---|---|---|---|
| Training | Learns via | Uses DDPM-trained model | Uses DDPM-trained model |
| Forward Process | Markovian (fixed noise schedule) | Implies a non-Markovian process (same ) | Same as DDPM |
| Generative Steps | (e.g., 1000+) | (e.g., 20-100) | for similar behavior |
| Stochasticity | Stochastic (noise at each step) | Deterministic (no noise ) | Stochastic (same as DDPM) |
| Invertibility | Not directly invertible | Invertible (allows encoding ) | Not directly invertible |
| Sampling Speed | Slow | Fast | Slow |
| Sample Quality | High | High (often better than DDPM for same number of model evaluations if ) | High (similar to DDPM) |
| Typical Use | Standard high-quality generation | Fast generation, image editing, latent space exploration | Equivalent to DDPM sampling |
2.8. Implementation Details for DDIM Sampling
The key is to use the same network trained for DDPM. The DDIM sampling loop is modified for fewer steps and the deterministic update rule.
Pseudo-code for DDIM Sampling && Encoding (with and without )
# DDIM Sampling and Encoding Pseudo-code (with η=0 for deterministic process)
def ddim_sample(model, x_T, timesteps):
"""
Sample from a trained diffusion model using DDIM.
Args:
model: The trained epsilon_θ model that predicts noise
x_T: Starting noise (typically sampled from N(0, I))
timesteps: List of timesteps to use for sampling (subset of original
schedule)
For example, if original T=1000, we might use
timesteps=[1000, 950, 900,..., 50]
Returns:
x_0: The generated sample
"""
x_t = x_T
for i in range(len(timesteps) - 1):
# Current and next timestep in the subsequence
t = timesteps[i]
t_prev = timesteps[i + 1]
# Get the current alpha values
alpha_bar_t = get_alpha_bar(t)
alpha_bar_prev = get_alpha_bar(t_prev)
# Predict the noise component using the model
pred_noise = model(x_t, t)
# Predict x_0 from x_t and predicted noise
pred_x_0 = (x_t - math.sqrt(1 - alpha_bar_t) * pred_noise) /
math.sqrt(alpha_bar_t)
# Use the predicted x_0 and the noise to compute x_{t-1} (DDIM update)
# For η=0 (deterministic DDIM)
x_t_prev = math.sqrt(alpha_bar_prev) * pred_x_0 + math.sqrt(1 -
alpha_bar_prev) * pred_noise
# Update x_t for next iteration
x_t = x_t_prev
return x_t # This is x_0 after the final iteration
def ddim_encode(model, x_0, timesteps):
"""
Encode a real image x_0 into its latent representation x_T using DDIM.
Args:
model: The trained epsilon_θ model that predicts noise
x_0: The real image to encode
timesteps: List of timesteps to use for encoding (subset of original
schedule, in reverse)
For example, if original T=1000, we might use
timesteps=[50, 100, ..., 1000]
Returns:
x_T: The latent representation
"""
x_t = x_0
for i in range(len(timesteps) - 1):
# Current and next timestep in the subsequence
t_prev = timesteps[i]
t = timesteps[i + 1]
# Get the current alpha values
alpha_bar_prev = get_alpha_bar(t_prev)
alpha_bar_t = get_alpha_bar(t)
# Predict the noise component using the model
pred_noise = model(x_t, t_prev)
# Predict x_0 from x_t and predicted noise
pred_x_0 = (x_t - math.sqrt(1 - alpha_bar_prev) * pred_noise) /
math.sqrt(alpha_bar_prev)
# Compute x_t using DDIM forward step (encoding)
x_t_next = math.sqrt(alpha_bar_t) * pred_x_0 + math.sqrt(1 - alpha_bar_t) * pred_noise
# Update x_t for next iteration
x_t = x_t_next
return x_t # This is x_T after the final iteration
def ddim_sample_with_eta(model, x_T, timesteps, eta=0.0):
"""
Sample from a trained diffusion model using DDIM with controllable
stochasticity.
Args:
model: The trained epsilon_θ model that predicts noise
x_T: Starting noise (typically sampled from N(0, I))
timesteps: List of timesteps to use for sampling
eta: Controls stochasticity (0.0 = deterministic DDIM, 1.0 = DDPM
equivalent)
Returns:
x_0: The generated sample
"""
x_t = x_T
for i in range(len(timesteps) - 1):
# Current and next timestep in the subsequence
t = timesteps[i]
t_prev = timesteps[i + 1]
# Get the current alpha values
alpha_t = get_alpha(t)
alpha_bar_t = get_alpha_bar(t)
alpha_bar_prev = get_alpha_bar(t_prev)
# Compute beta values
beta_t = 1 - alpha_t
beta_tilde = (1 - alpha_bar_prev) / (1 - alpha_bar_t) * beta_t
# Set sigma according to eta parameter
sigma_t = eta * math.sqrt(beta_tilde)
# Predict the noise component using the model
pred_noise = model(x_t, t)
# Predict x_0 from x_t and predicted noise
pred_x_0 = (x_t - math.sqrt(1 - alpha_bar_t) * pred_noise) /
math.sqrt(alpha_bar_t)
# Compute coefficient for the noise direction
direction_coefficient = math.sqrt(1 - alpha_bar_prev - sigma_t**2)
# Use the predicted x_0 and the noise to compute x_{t-1}
#(DDIM update with stochasticity)
x_t_prev = (math.sqrt(alpha_bar_prev) * pred_x_0 +
direction_coefficient * pred_noise +
sigma_t * torch.randn_like(x_t))
# Update x_t for next iteration
x_t = x_t_prev
return x_t # This is x_0 after the final iteration
References
-
Song, J., Meng, C., & Ermon, S. (2020). Denoising Diffusion Implicit Models. arXiv preprint arXiv:2010.02502. (Presented at ICLR 2021)
-
Ho, J., Jain, A., & Abbeel, P. (2020). Denoising Diffusion Probabilistic Models. arXiv preprint arXiv:2006.11239.