In the previous sections, we explored how diffusion models can generate diverse samples by learning to reverse a noising process. However, often we want to control what the model generates, for example, generating an image of a specific object or style. This is known as conditional generation. Guidance techniques are methods to steer this generation process towards desired attributes.
The core idea behind many guidance techniques is to modify the sampling process, specifically how the model predicts the less noisy sample from . Recall from DDPMs (Section 1.6) that the model predicts the noise added to to get . The reverse process then uses this predicted noise to estimate the mean of .
Guidance methods typically alter the effective noise prediction or, equivalently, the score , to incorporate the desired condition .
3.1. The Role of Score Matching and Noise Prediction
To fully appreciate why predicting the noise is so effective and how it relates to guiding the generation process, it’s helpful to briefly touch upon the concept of score-based generative models (also known as score matching).
The “score” of a data distribution at a point is defined as the gradient of the log-probability with respect to the data: . Score-based models aim to learn this score function for the data distribution at different noise levels.
The key intuition connecting this to noise prediction in DDPMs is that the score of the noised data distribution can be shown to be proportional to the negative of the noise that was added to to obtain (when conditioned on ). Specifically, for , we have .
So, a model that is trained to predict the noise is implicitly learning a scaled version of the score . This is why the terms “noise prediction model” and “score-based model” are often used interchangeably in the context of diffusion models, as they are learning essentially the same underlying quantity. The equations for classifier guidance, which explicitly use the score , highlight this connection.
While a deep dive into score-based models is beyond the scope of this note, understanding this connection provides a richer perspective on why diffusion models work and how guidance mechanisms are formulated. For those interested in a comprehensive exploration that covers VAEs, DDPMs, DDIMs, and Score-Based Models in detail, the following guide is an excellent resource:
3.2. Classifier Guidance
Classifier guidance, introduced by Dhariwal and Nichol (2021), uses a separate, pre-trained classifier to guide the diffusion sampling process. The classifier is trained to predict the class of a noisy image .
The Core Idea: Modifying the Score
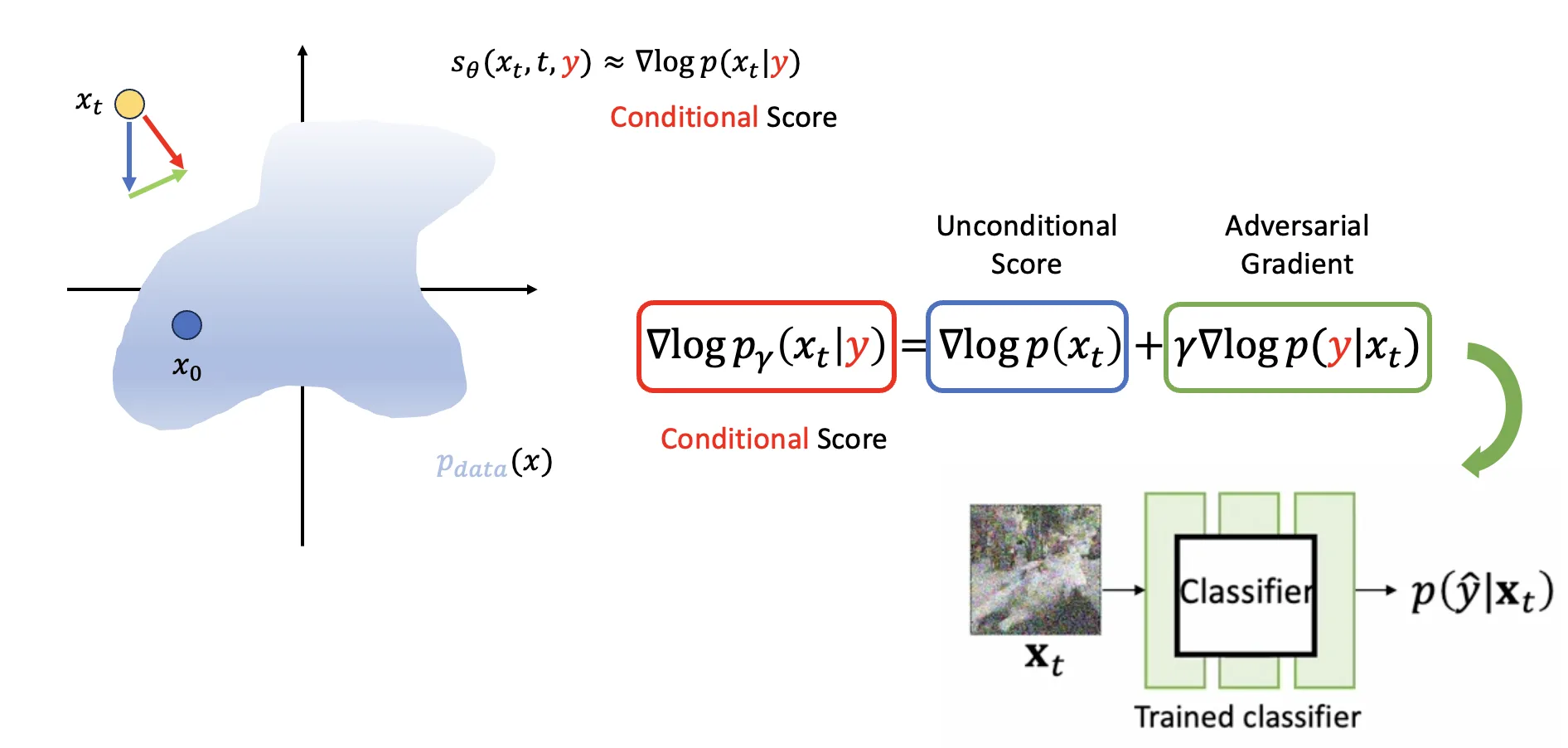
The goal is to sample from the conditional distribution . Using Bayes’ theorem:
Taking the logarithm and then the gradient with respect to :
Let’s break this down:
- : This is the score of the unconditional distribution that our diffusion model has learned to approximate. If our model predicts the noise, this score is related by .
- : This is the gradient of the log-likelihood of the condition given . This term is provided by the external classifier . It “points” in a direction that makes it more recognizable as class by the classifier.
The guided score is then a combination, often with a guidance scale (also denoted or guidance_scale):
This modified score then leads to an adjusted noise prediction that is used in the DDPM sampling step:
The term is often absorbed into a single guidance scale hyperparameter. The sign depends on whether the gradient is added to the score or subtracted from the noise.
How it Works in Practice
During each step of the reverse diffusion process:
- The diffusion model predicts the unconditional noise .
- The current noisy image and the target class are fed to the classifier .
- The gradient of the log probability of class with respect to the input , i.e., , is computed. This requires to have gradients enabled.
- The unconditional noise prediction is adjusted using this gradient and the guidance scale.
- The sampling step proceeds using this adjusted noise.
Pseudo-code for Classifier Guidance
# classifier_model: Pre-trained image classification model p_phi(y|x_t)
# model: Unconditional diffusion model epsilon_theta(x_t, t)
# scheduler: DDPM scheduler for timesteps and updates
# y: Target class label
# guidance_scale: Strength of the classifier guidance
input = get_noise_from_standard_normal_distribution(...) # Initial noisy image x_T
for t in tqdm(scheduler.timesteps): # Iterate from T down to 0
# Ensure input requires gradients for the classifier
input_with_grad = input.detach().requires_grad_(True)
# 1. Predict unconditional noise
with torch.no_grad():
noise_pred_uncond = model(input, t).sample # epsilon_theta(x_t, t)
# 2. Get classifier gradient
log_probs_y = classifier_model(input_with_grad, t).log_softmax(dim=-1)[:, y]
# log p_phi(y|x_t)
# 3. Compute gradient for guidance
class_gradient = classifier_model.get_class_guidance(input_with_grad, y)
# nabla_{x_t} log p_phi(y|x_t)
# 4. Adjust noise prediction
noise_pred_guided = noise_pred_uncond + class_gradient * guidance_scale
# 5. Perform sampling step
input = scheduler.step(noise_pred_guided, t, input).prev_sampleNote on Pseudo-code:
The exact implementation details, especially the sign and scaling of
class_gradient, can vary. The key is that the classifier’s gradient steers the sampling. Theclassifier_model.get_class_guidanceencapsulates the gradient computation .
Pros and Cons of Classifier Guidance
Pros:
- Can guide any pre-trained unconditional diffusion model without retraining it.
- Allows leveraging powerful, off-the-shelf classifiers.
Cons:
- Requires a separate classifier model, which must be robust to noisy inputs (often requires training the classifier on noisy data).
- The guidance is limited to the classes the classifier was trained on.
- Can be computationally more expensive due to classifier forward/backward passes at each step.
- Guidance can sometimes lead to adversarial examples for the classifier, resulting in artifacts if the guidance scale is too high.
3.3. Classifier-Free Guidance (CFG)
Classifier-Free Guidance (CFG), proposed by Ho and Salimans (2022), offers a way to guide diffusion models without needing an external classifier. It has become a very popular and effective technique.
The Core Idea: Jointly Trained Conditional Model
The key idea is to train a single diffusion model that is conditioned on (e.g., class label, text embedding). During training, this model is occasionally fed a null condition (e.g., a zero vector for class embeddings, or an empty string embedding for text). This means the model learns both conditional generation and unconditional generation (when ).
At sampling time, the model makes two predictions:
- : The noise prediction conditioned on the desired .
- : The noise prediction for unconditional generation.
The final noise prediction used for sampling is an extrapolation from the unconditional prediction in the direction of the conditional one:
Here, is the guidance scale (often denoted or guidance_scale).
- If , we get unconditional generation: .
- If , we get standard conditional generation: .
- If , the generation is pushed further in the direction of , often improving sample quality and adherence to the condition, at the cost of diversity.
Equivalently,
How it Works in Practice
- Training – Train a conditional diffusion model . With some probability (e.g., 10-20 %), replace the true condition with a null/empty condition .
- Sampling – At each step :
- Compute and .
- Combine them: .
- Use in the DDPM sampling step.
Pseudo-code for Classifier-Free Guidance (Text-to-Image Example)
# model: conditional diffusion model epsilon_theta(x_t, t, y_embedding)
# scheduler: DDPM scheduler
# text_condition: e.g. "a photo of a cat"
# guidance_scale: CFG strength
# text_encoder: encodes text to embeddings
cond_emb = text_encoder.encode(text_condition)
uncond_emb = text_encoder.encode("") # empty string
x = torch.randn_like(image_shape) # x_T ~ N(0,I)
for t in scheduler.timesteps:
with torch.no_grad():
eps_uncond = model(x, t, encoder_hidden_states=uncond_emb).sample
eps_cond = model(x, t, encoder_hidden_states=cond_emb).sample
eps_guided = eps_uncond + guidance_scale * (eps_cond - eps_uncond)
x = scheduler.step(eps_guided, t, x).prev_sample