Overview
The gradient descent (GD) algorithm will be introduced by balancing intuitive reasoning with mathematical rigor.
The discussion begins with arbitrary real-valued functions , which provide a natural geometric perspective, and is subsequently generalized to real-valued functions . In this progression, the role of derivatives is examined, the gradient is identified as the direction of steepest ascent, and from this the update rule governing the descent process is derived.
Once the mathematical foundations are established, the focus shifts to the application of gradient descent in the training of neural networks, where the loss function depends on a very large number of parameters (i.e., weights and biases). This progression, from low-dimensional intuition to high-dimensional practice, highlights both the elegance of the underlying mathematics and the challenges inherent in scaling the algorithm to modern Deep Learning.
Gradient Descent in
Let’s consider a function
which depends on two variables, and .
Goal attains its global minimum.
The objective is to determine the point at which
For a simple illustrative example, the graph of such a function can be inspected directly, and the minimum identified by eye.
Note
Of course, this simplicity is somewhat artificial: the function in the example is deliberately chosen to be well-behaved so as to serve as a pedagogical aid.
A general function may depend on a large number of variables and exhibit far more complex landscapes, making visual inspection infeasible.
When Calculus Fails
One classical approach is to apply calculus: by computing derivatives, one can attempt to identify critical points where achieves local extrema. While this strategy may succeed for functions of one or a few variables, it quickly becomes impractical in higher dimensions. In neural networks, for instance, the loss function typically depends on billions of weights and biases in a non trivial way, making analytical minimization via calculus essentially intractable.
Limits of 2D Intuition
Although the initial visualization in two dimensions provides useful intuition, it has its limitations. When considering functions of very high dimensionality, the two-dimensional picture inevitably breaks down. Nonetheless, cultivating multiple complementary intuitions is central to effective mathematical reasoning: one must learn when a given visualization is appropriate, when it ceases to be reliable, and how to transition between different perspectives as the problem demands.
The valley analogy
Since an analytical calculus-based minimization quickly becomes impractical in high dimensions, an alternative perspective arises from an analogy.
The function can be envisioned as defining the shape of a valley, with its graph representing the surrounding landscape.
If one imagines placing a ball somewhere on the slope, intuition suggests that it will eventually roll down toward the bottom of the valley.
Intuitive insight
This picture provides a natural metaphor for searching for a minimum: starting from an arbitrary point, the descent of the ball can be viewed as the iterative process guiding the parameters toward a lower value of the function.
Not a physical simulation
Of course, this analogy should not be interpreted literally. The objective is not to replicate the physical laws governing a real ball (e.g., friction, inertia, gravity), but rather to design an algorithmic procedure that reliably moves toward the minimum.
The ball-rolling metaphor serves as a heuristic to stimulate intuition; the actual “laws of motion” governing the descent will be chosen deliberately to ensure convergence to the bottom of the valley.
To sharpen the valley analogy, consider small displacements of the parameters.
Suppose the point is perturbed by an increment in the direction and in the direction.
By a first-order Taylor approximation, the resulting change in the function is given by
The objective is to select the increments and such that , i.e., so that the movement corresponds to rolling down the valley toward lower values of the function.
To express this more compactly, define the vector of changes in
where the superscript is understood to denote transposition, converting between row and column representations.
Next, the gradient of the loss function is introduced as the vector of partial derivatives:
This compact notation collects all first-order derivatives of into a single vector.
It is worth emphasizing that should be regarded as one mathematical object, the gradient vector, rather than as two separate pieces joined by a symbol.
In essence, the symbol serves as notational shorthand indicating “this is the gradient of .”
Although in more advanced contexts can be interpreted as an operator in its own right (e.g., within differential geometry), in this setting it suffices to treat simply as the vector of partial derivatives defined above.
On the basis of these definitions, the expression for can be reformulated as
This relation explains why is designated as the gradient vector: it establishes a direct correspondence between variations in the parameters and variations in the loss .
Crucially, the formulation also indicates a principled way to ensure that is negative.
By prescribing
with denoting a small constant known as the learning rate, equation can be rewritten as follows:
Since , it follows that .
Thus, within the limits of the linear approximation, the loss is guaranteed to decrease under this update rule.
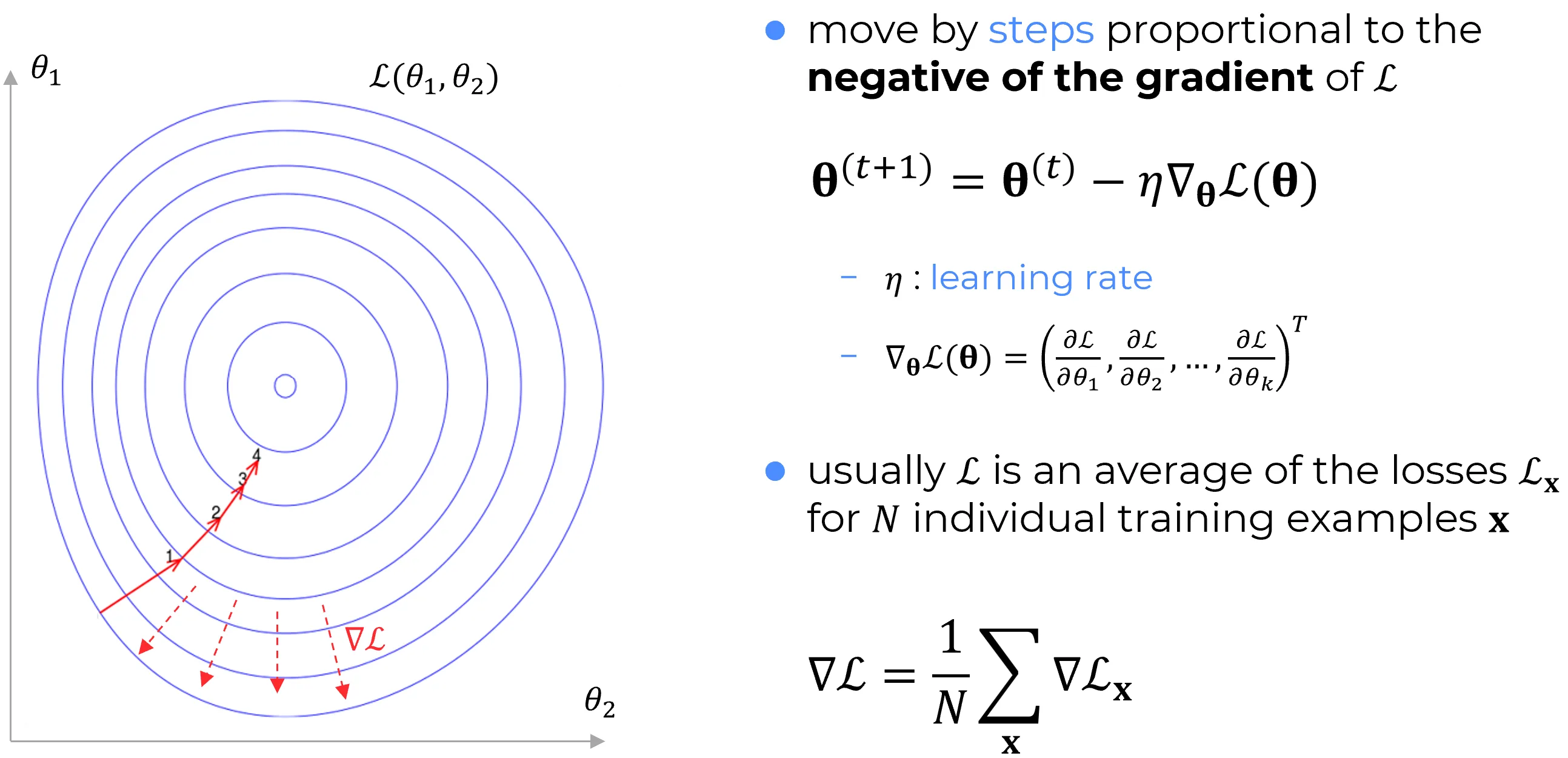
This observation motivates the law of motion underlying the gradient descent algorithm:
Repeated application of this update drives the parameters downhill, progressively reducing , until, ideally, the process converges to a global minimum.
In summary, the gradient descent algorithm operates by repeatedly computing the gradient and updating the parameters in the opposite direction, effectively moving “downhill” along the slope of the loss landscape.
It should be emphasized that this procedure does not replicate the dynamics of real physical motion. A ball rolling in a valley possesses momentum, which may carry it across the slope or even momentarily uphill before friction eventually ensures a downward trajectory. In contrast, the update rule of gradient descent prescribes an immediate step downhill at each iteration. Although simplified, this mechanism remains highly effective for locating minima.
Important
Correct functioning of the algorithm depends critically on the choice of the learning rate .
- If is too large, the linear approximation used to derive the update rule no longer holds, and it is possible to obtain , which would defeat the purpose of the method.
- If is too small, parameter updates become negligible, causing the algorithm to converge excessively slowly.
In practice, the learning rate is often scheduled or adapted over time to balance these considerations, ensuring that the approximation remains valid while maintaining a reasonable rate of convergence.
Gradient Descent in higher dimensions
The discussion so far has considered the case where depends on just two variables.
However, the same reasoning extends directly to functions of many variables.
Suppose that is a function of parameters .
Then the change in resulting from a small perturbation
is approximated by
where the gradient is the vector of partial derivatives
As in the two-variable case, choosing
with denoting the learning rate, ensures that the approximate change is negative.
Thus, the parameters can be iteratively updated according to the rule
which provides a systematic procedure for descending toward a minimum even when depends on many variables.