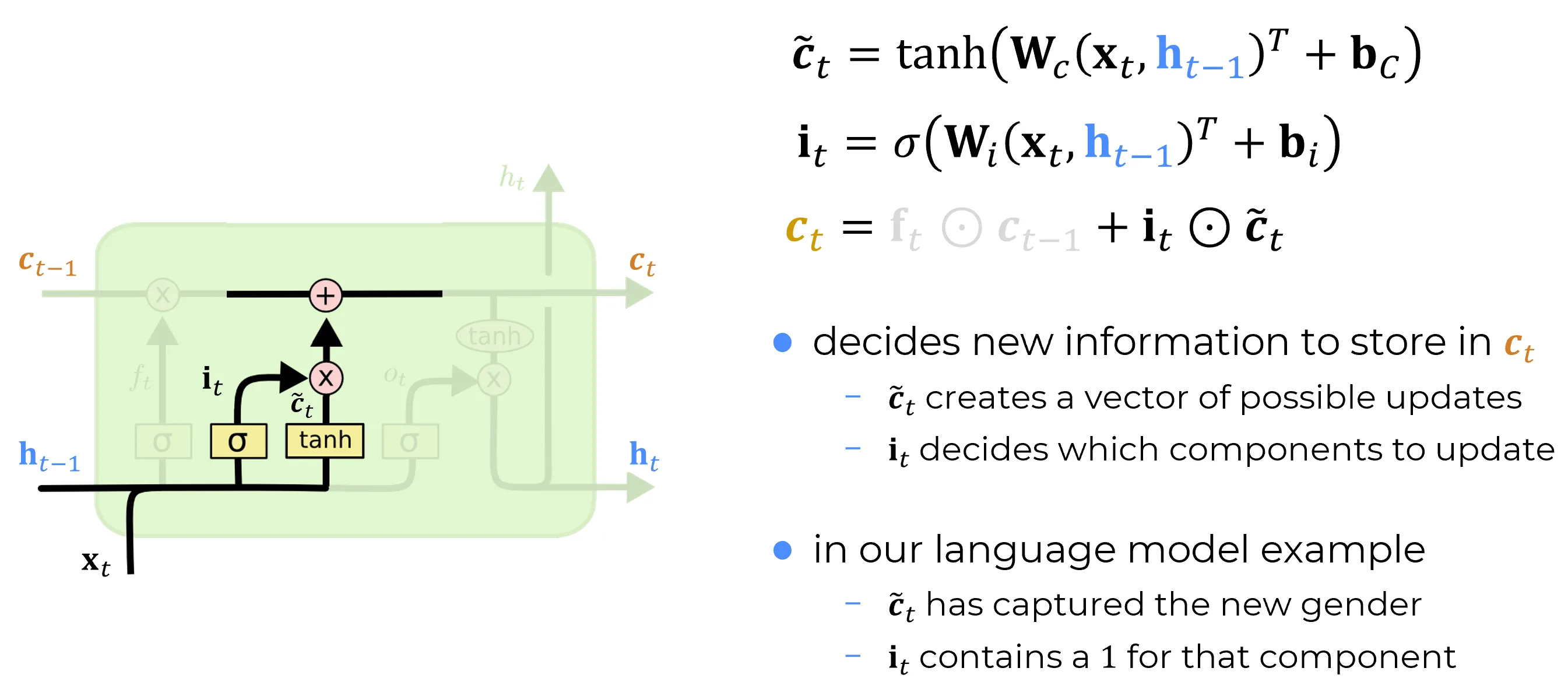
The forget gate decides what to erase from the previous cell state. The input gate decides what to write into the new one. Writing is split into two questions that the LSTM keeps strictly separate:
- What could be written? A candidate update , proposed by a tanh layer.
- How much of it should actually be written, coordinate by coordinate? A gate , produced by a sigmoid layer.
The two are combined element-wise into the additive contribution , and the cell state is updated as
This separation of what and how much is the architectural device that makes the cell’s memory both bidirectional in sign and selectively addressable. Both properties are unusual, and both are essential.
The candidate update
The candidate is computed by a single fully connected layer of width with tanh activation:
It depends on the same input pair as every other gate in the cell. Its parameters are independent of those of the forget and input gates.
Dimensions used in this note
symbol role single example mini-batch () current input previous hidden state previous cell state new cell state forget gate (from Forget gate) input gate candidate update input-to-hidden weights idem hidden-to-hidden weights idem biases (broadcast across columns) The element-wise products and act on operands of identical shape: no broadcasting is involved in the .
Why tanh and not sigmoid for the candidate
The forget and input gates use sigmoid because they play the role of multiplicative masks: values in act as continuous on/off switches, and there is no situation in which “negative keeping” or “negative writing” would make sense.
The candidate plays a different role. It is added to the cell state, so its sign matters: each coordinate of can either push up or push down the corresponding coordinate of . A bounded, zero-centred range is the natural choice. Sigmoid would constrain the candidate to non-negative values, breaking the symmetry and forcing the cell state to drift in one direction; tanh keeps the additive updates centred around zero, which keeps the cell state itself bounded in expectation.
So the role determines the activation: masks use sigmoid, contents use tanh. The same logic governs the choice of tanh in the vanilla RNN recurrence (see the “Why tanh?” callout there).
The input gate
The input gate is again a sigmoid layer with the standard structure:
Coordinate by coordinate, controls how much of the candidate is admitted into the corresponding slot of the cell state. A value near accepts the candidate in full; a value near rejects it; intermediate values blend it in partially.
Two questions, two networks, one input
A single network producing values in could in principle express both “what to write” and “how much” in one shot: a small magnitude would mean “write little”, a large one would mean “write a lot”. The LSTM deliberately refuses this conflation.
The reason is that gradient flow distinguishes the two. The candidate is added to , so its gradient receives the full upstream signal multiplied by ; the gate enters multiplicatively, so its gradient is multiplied by instead. Splitting the two networks gives the optimizer two independent levers for the same write operation, and it is consistently easier to train than a single fused layer. Modern attention-based architectures revisit exactly this trick, splitting content from routing through separate projections.
How the two combine
The new contribution to the cell state is the element-wise product
It is bounded coordinate-wise: even if every gate fires fully and every candidate saturates, no single update can add more than in magnitude to any slot of the cell state. The full cell state update,
then has a clean interpretation: each slot of memory is independently decayed by the forget gate and incremented by the gated candidate. The two operations commute with the coordinate structure, so the LSTM’s memory is, internally, scalar registers operating in parallel, each one with its own learned decay and its own learned write enable.
Each coordinate is an independent learned register
The cell state is not a single distributed representation in the way a vanilla hidden state is. Because the recurrence factorizes across coordinates,
the network can in principle dedicate different slots to different memories with different lifetimes: a slot with everywhere becomes a near-permanent register; a slot with at every boundary becomes a working-memory scratchpad. The gates that affect slot at time still depend on all coordinates of and (the -th row of the weight matrices is dense), but the update rule applied to each slot is independent of the others.
This is why probing studies on trained LSTMs occasionally find single coordinates of that track interpretable variables: line-position counters, quote-depth, sentence sentiment. The architecture explicitly affords such coordinate-level specialization.
Why the recurrence factorizes coordinate-wise
By the coordinate independence of , , so the -th coordinate of depends only on the -th coordinates of and . Applying this to both terms of the cell state update,
gives, component by component,
Slot of the new cell state depends on slot of the previous cell state and on slot of the candidate; coordinates do not mix. The coupling across coordinates lives entirely upstream, inside the four affine maps that produce from . Replace the recurrence’s with a general matrix multiplication and the property is lost: this is exactly what a vanilla RNN does, and it is why the vanilla RNN cannot dedicate isolated slots to isolated memories.
A language-model example, continued
Returning to the example from the forget gate note: while reading “Alice was walking”, the input gate writes a new value into the “subject gender” slot of the cell state. Concretely, the candidate coordinate might take a value near to encode “female subject”, and the input gate coordinate fires near to admit it. The forget gate has, at the same step, already cleared whatever was previously stored in slot , so the new gender simply replaces the old one. From that point until the gate decides to clear or overwrite slot again, the value rides the cell-state highway untouched.
The crucial property here is selectivity. At the same time step, the input gate may write into slot while leaving slot (say, “current verb tense”) completely alone, because . A vanilla RNN cannot do this: every step overwrites every coordinate of its hidden state in lockstep.
Mini-batch form
For a mini-batch of examples, vectors become matrices with one column per example. The shared weights are unchanged; the gate equations read
with , and broadcasting across columns. As always in the LSTM, the parameters are shared across both the batch dimension and the unrolled time dimension.
The last gate, the output gate, decides what fraction of the newly updated cell state becomes the externally visible hidden state .