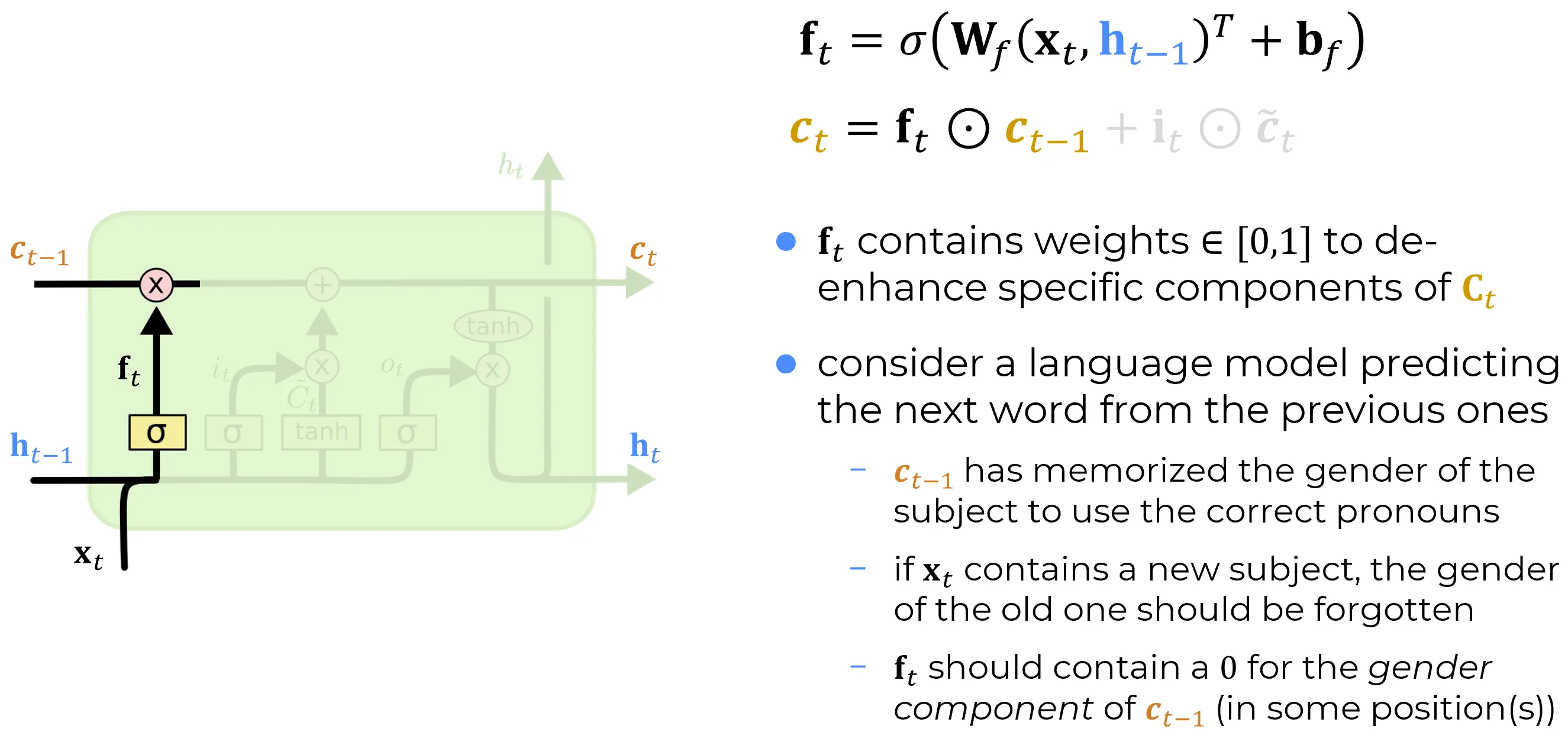
The forget gate is the first of the three gates that act on the cell state. It produces a vector that scales the previous cell state coordinate by coordinate before the new content is added:
This is the only mechanism by which the LSTM can erase information from its memory. Without it, the cell state would be a strictly accumulating buffer; with it, the cell state becomes a finite, refreshable register whose contents the network learns to manage.
Definition
The forget gate is a single fully connected layer of width with sigmoid activation. It consumes the current input and the previous hidden state , and returns
The sigmoid is applied element-wise, so each coordinate of is an independent value in , and the product rescales each coordinate of by its own learned factor.
"Element-wise sigmoid" written out
Let denote the pre-activation. The notation means: apply the scalar sigmoid to each coordinate independently,
This is a vector-valued function of a vector input, , that does not mix coordinates: the output at slot depends only on the input at slot . The coordinates of are therefore independent of each other given the pre-activation, even though the pre-activation itself is computed from a dense affine map. The same applies to throughout the LSTM.
Dimensions used in this note
symbol role single example mini-batch () current input previous hidden state previous cell state forget gate input-to-hidden weights idem hidden-to-hidden weights idem bias (broadcast across columns) The product (and in mini-batch form) acts on operands of identical shape: no broadcasting is involved in the .
Pointwise reading of the gate
If the pre-activation vector evaluates to , the gate fires as
Applied component-wise to , this keeps roughly 88% of the third coordinate, halves the second, and erases nearly 90% of the first. The forget gate is not a binary mask; it is a continuous, per-coordinate volume knob.
Why sigmoid, and not anything else
The choice of is dictated by the role of in the cell state update.
- The output must lie in , because is meant to rescale, not to flip sign or amplify. A value of keeps the corresponding coordinate intact; a value of erases it; intermediate values smoothly interpolate between the two.
- The function must be smooth and differentiable, so that the gating decision is learnable end-to-end. A hard mask would block gradient flow.
- The function must be monotone, so that “raising the pre-activation” unambiguously means “keep more”. This makes the optimization landscape interpretable: each component of has a clear sign of effect.
The sigmoid is essentially the unique smooth choice that satisfies all three at once. It also gives the gate a clear interpretation as the Jacobian of the cell-state recurrence: differentiating the cell-state update with respect to gives exactly , so the forget gate is the recurrent Jacobian (see Cell state and Gradient in LSTM).
The forget gate decides how long memories live
Setting at every step keeps coordinate of the cell state alive indefinitely; the contribution of to persists almost undiminished. Setting at a particular step wipes that coordinate in a single step.
Because depends on , the network can condition the preservation of each memory slot on the current context. A language model can keep “the subject is plural” while reading the verb, then forget it at the end of the clause; a control system can keep “the previous action” until the consequence is observed, then clear it. This is what the vanilla RNN could not do at all: there, preservation was a knife-edge of the spectrum; here, it is a decision the model takes at every step.
A worked example: gender of the subject
Consider a character-level language model reading the sentence “Alice was walking and she was happy.”
While processing the word Alice, the input gate writes into one coordinate of a representation of the grammatical gender of the subject (this is the job of the input gate). Several time steps later, when the model encounters she, that same coordinate is still needed to disambiguate the pronoun. The forget gate is what keeps it alive in the meantime: at every intermediate step, the corresponding component of stays close to , so the gender information passes through the cell-state line essentially unchanged.
Now suppose the sentence ends and a new, unrelated one begins. At the period (or whatever boundary signal is encoded in and ), the network can drive the same component of to a value near : the previous subject’s gender is deleted in a single step, freeing the slot for the next sentence’s subject. The cell state has a finite capacity, on the order of slots, and the forget gate is what makes that capacity reusable.
Mini-batch form
In practice the cell processes a mini-batch of sequences in parallel. Input, hidden state, and gate become matrices whose columns are the per-example vectors:
The weights and the bias are shared across all examples in the batch (and, in the unrolled cell, across all time steps), so their shapes do not change. The vectorized forget gate reads
with added to every column via broadcasting and applied element-wise. This is the form actually executed on GPU and the one assumed in all subsequent equations.
On the "concatenated weight matrix" notation
Many references write the gate as with a single matrix acting on the vertical concatenation of and . Block-matrix multiplication makes the two forms identical:
The compact form is convenient on paper and matches the way modern frameworks store the parameters (a single fused weight tensor for all four gates), but it hides the fact that the input and the previous hidden state are conceptually distinct sources of context. The explicit form is used throughout these notes.
A practical detail: initializing the forget bias
A common and consequential trick: initialize rather than (Jozefowicz, Zaremba and Sutskever, 2015). With zero bias, the sigmoid starts at , so a freshly-initialized LSTM forgets half of its memory at every step; across, say, twenty steps the residual is , and the cell state path is effectively dead at initialization. Setting shifts the sigmoid to roughly , so the cell state survives initialization long enough for the gradient signal to teach the gate when it actually needs to forget. This is the kind of detail that decides whether an LSTM trains at all on long sequences.
Saturated gates stop learning
A sigmoid gate has derivative , which collapses toward zero as the pre-activation grows large in magnitude. A gate pushed deep into saturation, pinned at almost exactly or , therefore receives almost no gradient and can become stuck: it can no longer learn to change its decision. This is the reason the forget-bias trick targets , where sits on the responsive part of the curve, rather than a large value such as , where would begin in saturation and resist ever learning to forget. The same caution applies to all four gates: a healthy LSTM keeps its gates off the flat extremes for most of training, and a coordinate whose gate saturates early effectively freezes that coordinate’s behaviour for the rest of the run.
The next gate, the input gate, decides what is added to the cell state once the forget step has rescaled it.