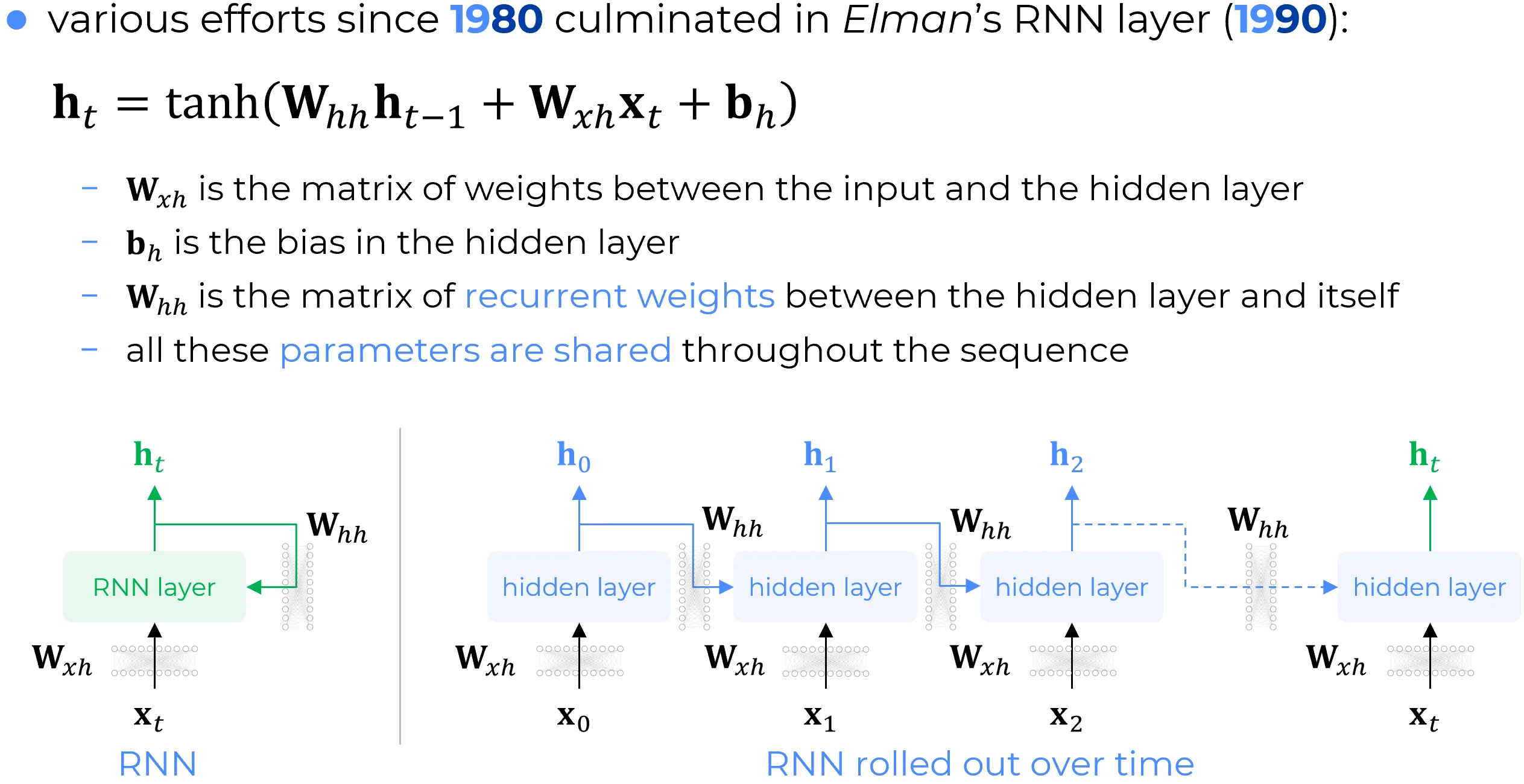
In precedenza è stato introdotto il vanilla RNN layer : si tratta di un layer, tipicamente completamente connesso, il cui output viene reimmesso come input al layer stesso.
Nella la fase di addestramento, ciascun layer RNN, facente parte di una rete neurale, può essere sostituito in modo equivalente dal suo “srotolamento” nel tempo (unrolling), generando un numero di layer pari ai passi temporali richiesti dai dati di addestramento. Poiché tutti i layer “srotolati” sono in realtà istanze del medesimo layer, essi condividono gli stessi parametri, un fatto che comporta conseguenze di notevole importanza.
Nel 1990, un paper di Elman definì formalmente il layer RNN.
Definizione vanilla RNN layer
Si tratta di un layer che, ricevendo in input i dati correnti e lo stato dell’iterazione precedente , applica a entrambi delle trasformazioni lineari ad hoc, definite da specifiche matrici dei pesi. Si ha quindi una trasformazione lineare specifica per lo stato precedente, una trasformazione lineare specifica per l’input e un termine di bias. A tale combinazione lineare viene poi applicata una funzione di attivazione, che in questo contesto non è la sigmoide, bensì la tangente iperbolica .
Pertanto:
dove:
-
è la matrice dei pesi tra lo strato di input e lo strato nascosto.
-
è il vettore di bias dello strato nascosto.
-
è la matrice di trasformazione dello stato da nascosto a nascosto, nota anche come matrice dei pesi ricorrenti.
Note
Le matrici dei pesi e sono condivise lungo l’intera sequenza dei layer srotolati nel tempo. Pertanto, mentre nella figura seguente in basso a sinistra si osservano due trasformazioni matriciali associate alle rispettive frecce, nell’architettura equivalente srotolata queste due matrici sono condivise, ovvero sono le medesime per tutta la sequenza temporale.