Important
La Ricorrenza costituisce l’approccio fondamentale, e storicamente il primo, per implementare una forma di memoria nelle reti neurali. Mediante tale paradigma, la rete acquisisce uno stato interno che le permette di processare le informazioni in modo sequenziale e dipendente dal contesto passato.
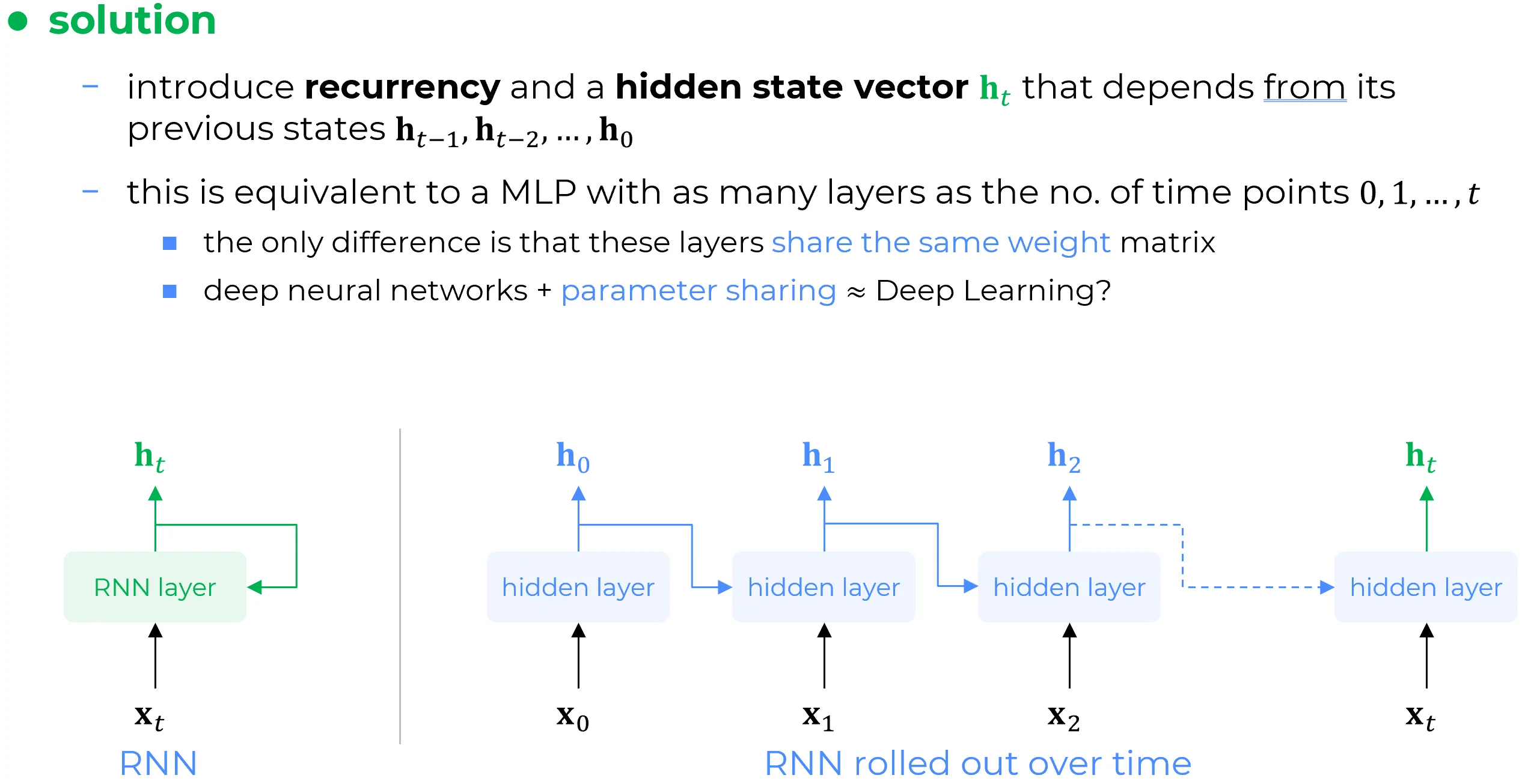
Si consideri un layer generico di rete neurale (ad esempio, uno layer completamente connesso, convoluzionale o di altra natura), il quale costituirà il layer ricorrente (RNN Layer). Tale layer genera una rappresentazione latente , definita “nascosta” poiché questo layer potrebbe non essere quello finale (output layer) dell’architettura di cui è parte. Il vettore rappresenta quindi l’output del layer in questione. Mutuando la terminologia dei Multi-Layer Perceptron (MLP), tale layer è a tutti gli effetti un hidden layer e il suo output è un “hidden vector “. Il vettore di stato nascosto viene fornito in input al medesimo layer nell’iterazione successiva . Ciò significa che l’output prodotto all’iterazione corrente viene riutilizzato come input nell’iterazione seguente. Questo processo incarna il concetto di stato, poiché l’informazione prodotta in un dato istante viene preservata per essere utilizzata in un momento successivo, secondo uno schema che si ripete iterativamente nel tempo. Il ricercatore che per primo comprese la necessità della ricorrenza nelle reti neurali fu John Hopfield.
Di conseguenza, il vettore a una generica iterazione è denominato vettore di stato nascosto proprio perché il vettore nascosto all’iterazione dipende funzionalmente dal vettore nascosto all’iterazione , il quale a sua volta dipende da quello all’iterazione , e così via ricorsivamente, in una catena di dipendenze che risale fino all’istante iniziale. Pertanto, quello che tradizionalmente viene definito forward pass della rete diviene in tale contesto un processo ricorsivo: si produce un output che viene impiegato per la computazione successiva, il cui risultato verrà a sua volta utilizzato per la computazione seguente, in una sequenza che, teoricamente, può estendersi indefinitamente.
Note
La rappresentazione a sinistra nella figura illustra efficacemente il meccanismo di memoria. Tuttavia, per poter addestrare una rete di tale natura, è necessaria una diversa prospettiva. A tal fine, nella parte destra della figura in basso è riportata una rappresentazione equivalente, la quale fornisce spunti per le modalità di addestramento di una rete dotata di un meccanismo di memoria intrinseco. Tale rappresentazione non è altro che lo “srotolamento nel tempo” (unrolling) del layer RNN per un numero di passi temporali pari alla lunghezza delle sequenze utilizzate durante l’addestramento.
Example
Se, ad esempio, si adoperano segmenti di serie temporali di lunghezza , lo strato RNN viene di fatto replicato volte. Partendo dal dato iniziale , il layer produce un vettore nascosto . Quest’ultimo, unitamente al secondo dato , viene fornito come input allo stesso layer nella seconda iterazione, generando un nuovo vettore nascosto . Tale vettore, insieme al terzo dato , alimenterà nuovamente lo stesso later per produrre a valle della terza iterazione, e così via.
Condivisione dei Parametri e Profondità: l'essenza del Deep Learning nell'Architettura Ricorrente
Inoltre, è fondamentale osservare che i layer nascosti dell’architettura srotolata nel tempo sono in realtà istanze del medesimo layer, che viene riutilizzato ricorsivamente. Di conseguenza, l’architettura “srotolata” (a destra nella figura) è funzionalmente equivalente a un MLP molto profondo in cui i parametri di tutti gli strati sono identici. Si realizza così il principio della condivisione dei parametri (parameter sharing). Pertanto, la suddetta architettura srotolata nel tempo racchiude in sé sia il concetto di profondità (depth) sia quello della condivisione dei parametri, che sono due delle componenti costitutive fondamentali di ciò che si intende per Deep Learning.
Paternità del Deep Learning: Il Ruolo delle Reti Ricorrenti
Questo approccio ricorsivo è stato fin da subito considerato una forma di Deep Learning, poiché si ottiene un’architettura profonda strati, e ciò già negli anni ‘80. Gli ideatori di tali modelli sostennero infatti di aver concepito il Deep Learning prima che questo divenisse universalmente noto nell’era delle reti neurali convoluzionali (CNN).
This chain-like nature reveals that recurrent neural networks are intimately related to sequences and lists. They’re the natural architecture of neural network to use for such data.
English version save in anotehr place the following
The initial solution proposed to give memory to neural networks was to introduce Recurrency. Recurrency introduces in neural networks a memory mechanism.
Consider a generic neural network layer (it could be a fully connected layer, a convolutional layer, whatever layer you want) this will be our RNN layer. This layer will generate some hidden representation (hidden because this layer I’m considering may not be the final output layer of the architecture of which it’s a part of) which is the output of this layer, so is the output of a certain layer of the network. In MLP terminology this layer is a hidden layer and its output is an hidden vector.
Now the hidden state vector is given to the same layer in the next iteration , meaning that what is produced at this current iteration will be used at the next iteration: this is the concept of the state because what I’m producing now will be used later, and then this patterns will repeat through time. The guy that understood that in neural networks we need recurrency was Hopefield. So at a generic time point is called a hidden state vector only because the hidden vector at iteration will depend on the hidden vector at iteration which itself depend on the hidden vector at iteration and this goes back to the first iteration. So what we used to call forward pass of the network now it’s recursive: starting produce something that will be used later to produce something which will be used later to produce something and so on recursively theoretically indefinitely.
The left part of above figure is a nice depiction of the memory mechanism but then we need to be able to train such a network. So on the left side of the above figure is depicted an equivalent representation of the left part which gives us insights on how to train such a network which now has a memory mechanism in itself. The left part is the unrolling of the RNN layer into as main time points that we feed in the training phase. So if time series chunks of length 50 then the RNN layer will be replicated 50 times because starting from the initial data point an hidden vector will be produced by the layer and then this will be the input together with the second data point again to the layer in the second iteration and the layer will give as output another hidden vector which will be the input together with the third data point again to the same layer to produce another hidden vector and so on.
And this is definitely been regarded as deep learning because we have an architecture 50 layers deep and this was in the 80s. The people who invented these things they claimed to have invented deep learning before deep learning was known in the CNNs era.
Furthermore, since those hidden layers are actually all the same layer which is enrolled through time. Therefore the unrolled architecture on the right in the above picture is equivalent to a many layers MLP where the parameters of these layers are all the same: so this is parameter sharing. So that unrolled architecture on the right has in itself both the concept of and parameter sharing which are the constitutive components of deep learning paradigm.