The Elephant in the Model: Complexity vs. Generalization
Note
One of the fundamental principles of scientific modeling is that a model that fits the data perfectly is not necessarily a good model.
This idea was captured in a famous anecdote involving two giants of 20th-century physics and mathematics.
The Nobel Prize–winning physicist Enrico Fermi was once asked for his opinion on a mathematical model proposed to solve an important open problem in physics.
The model showed excellent agreement with the experimental data, yet Fermi remained skeptical.
“How many free parameters does the model have?” The answer was: “Four.”
At that point, Fermi replied, quoting his friend, the mathematician John von Neumann:
John von Neumann
“With four parameters I can fit an elephant, and with five I can make it wiggle its trunk.”
The message from von Neumann is as ironic as it is insightful.
Fit vs. Generalization
With sufficient complexity (free parameters), a model can be forced to fit an extremely wide range of datasets, without truly capturing the underlying structure of the phenomenon it is meant to describe.
Overfitting
A sufficiently complex model can be forced to “describe an elephant,” but this does not imply that it has truly understood what an elephant is. This is the classic sign of overfitting: a model that fits the training data perfectly may simply have memorized those data, including noise and idiosyncrasies, instead of having learned a general rule.
This captures the core of the issue: such a model will perform extremely well on the data it has already seen, but will almost certainly fail to make accurate predictions on new data, because it has not developed a true understanding of the problem.
This observation is even more relevant in the context of modern Deep Learning.
Example
An MLP with a single hidden layer of 30 hidden neurons for classifying MNIST digits can have about 24,000 parameters.
An MLP with a single hidden layer of 100 hidden neurons can reach about 80,000 parameters.
The most modern deep neural networks can have millions or even billions of parameters.
Question
Can the predictions of such highly parameterized models really be trusted?
Answer
The decisive benchmark for a model is its ability to make predictions on data it has never seen before, not its performance on already known data.
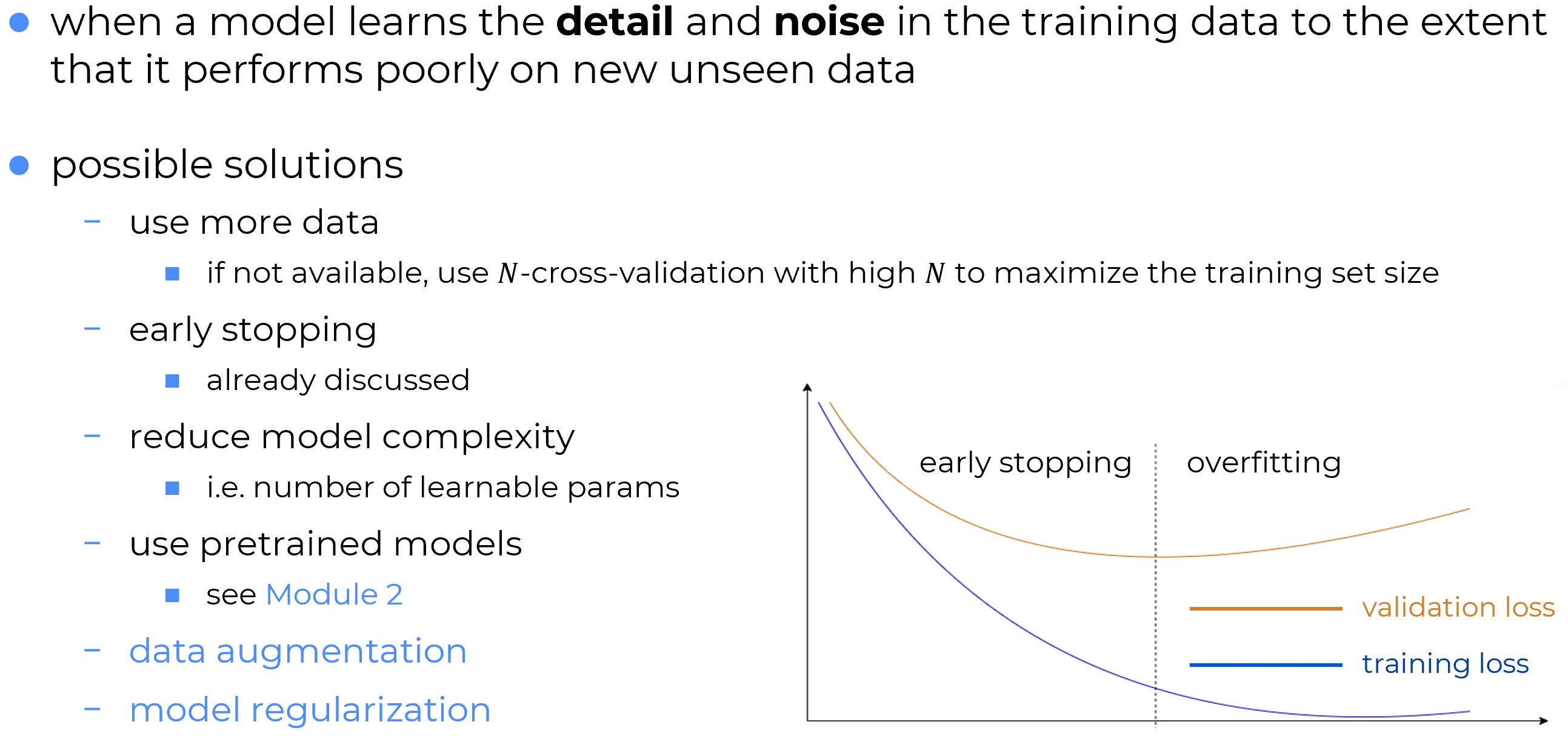
Mitigating Overfitting: Core Strategies
Several well-established strategies exist to mitigate overfitting and improve a model’s generalization ability.
-
Use More Data: This is the most effective solution. A larger and more diverse training set makes it harder for the model to “memorize” noise and forces it to identify more robust underlying patterns. Data are the essential ingredient of Deep Learning.
-
Early Stopping: The model’s performance on a separate validation set is monitored, and training is stopped as soon as the performance on this set stops improving, thus preventing overfitting.
-
Reduce Model Complexity: A simpler model (with fewer layers or fewer neurons) has a lower capacity to memorize training data and is therefore forced to find more general solutions.
-
Use Pre-trained Models (Transfer Learning): Training can start from a model that has already been trained on a very large dataset (e.g., ImageNet). Such a model has already learned general and robust features, which can then be transferred to the specific problem with shorter and more targeted training.
-
Data Augmentation: If collecting new data is not feasible, artificial samples can be generated by applying transformations (e.g., rotations, flips) to the existing data. This increases the diversity of the training set.
-
Model Regularization: To ensure the model learns robust and generalized patterns rather than becoming overly dependent on specific, potentially noisy features in the training data, techniques such as L1/L2 regularization (which adds penalties to the loss function to discourage large weights) and Dropout (which randomly deactivates neurons during training) are used. Additionally, techniques like Batch Normalization, while primarily designed to stabilize and accelerate training, also provide a slight regularizing effect as a beneficial side effect.
Complementary Strategies
These approaches are not mutually exclusive. In practice, they are often combined to achieve stronger generalization - for instance, using transfer learning together with data augmentation and early stopping.