Experiment setup
L’esperimento vede:
- neuroni nel livello hidden
- mini-batch di dimensione
- learning rate pari a
- funzione di costo cross-entropy
- dataset ridotto : campioni di training
In questo caso viene introdotto un parametro di regolarizzazione con valore .
Note
Nel codice, il parametro di regolarizzazione è memorizzato nella variabile lmbda, poiché lambda è una parola riservata in Python con un significato non correlato.
Uso di
test_dataal posto divalidation_dataPer il confronto dei risultati, viene utilizzato il dataset
test_data, in luogo delvalidation_data.
Tecnicamente sarebbe più appropriato usarevalidation_data, per tutti i motivi già discussi in precedenza (valutazione su dati non visti durante l’addestramento, tuning degli iperparametri, ecc.).Tuttavia, è stato scelto di usare
test_dataper consentire un confronto diretto con i risultati precedenti ottenuti senza regolarizzazione.È comunque possibile modificare facilmente il codice per usare
validation_data, ottenendo risultati molto simili.
>>> import mnist_loader
>>> training_data, validation_data, test_data = mnist_loader.load_data_wrapper()
>>> import network2
>>> net = network2.Network([784, 30, 10], cost=network2.CrossEntropyCost)
>>> net.large_weight_initializer()
>>> net.SGD(training_data[:1000], 400, 10, 0.5, evaluation_data=test_data, lmbda = 0.1, monitor_evaluation_cost=True, monitor_evaluation_accuracy=True, monitor_training_cost=True, monitor_training_accuracy=True)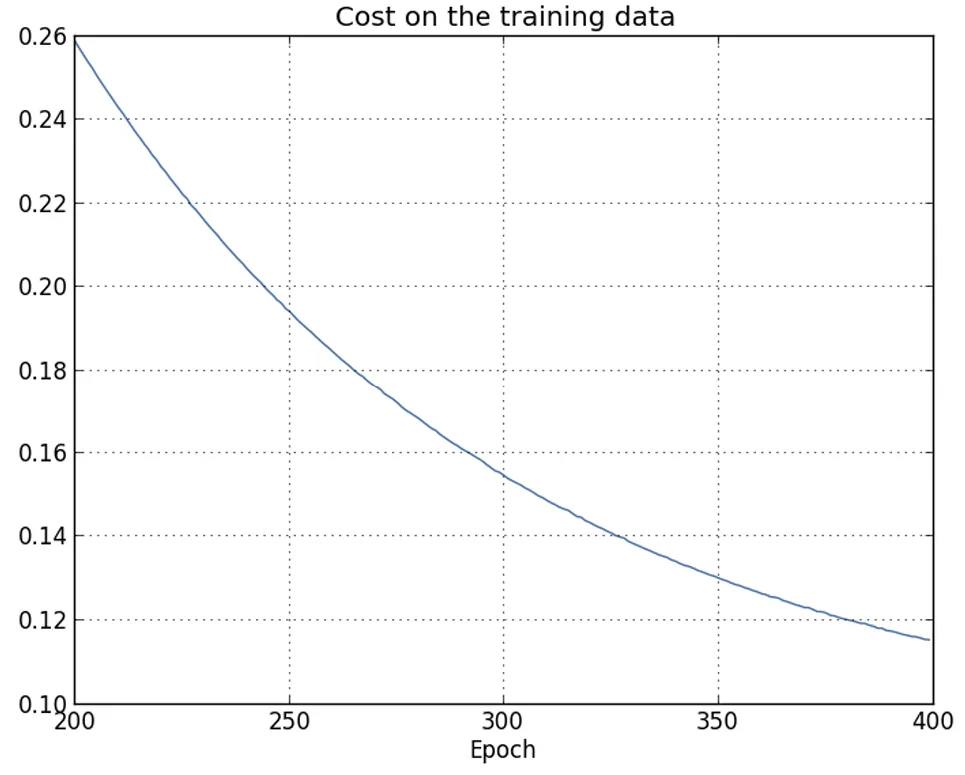 | 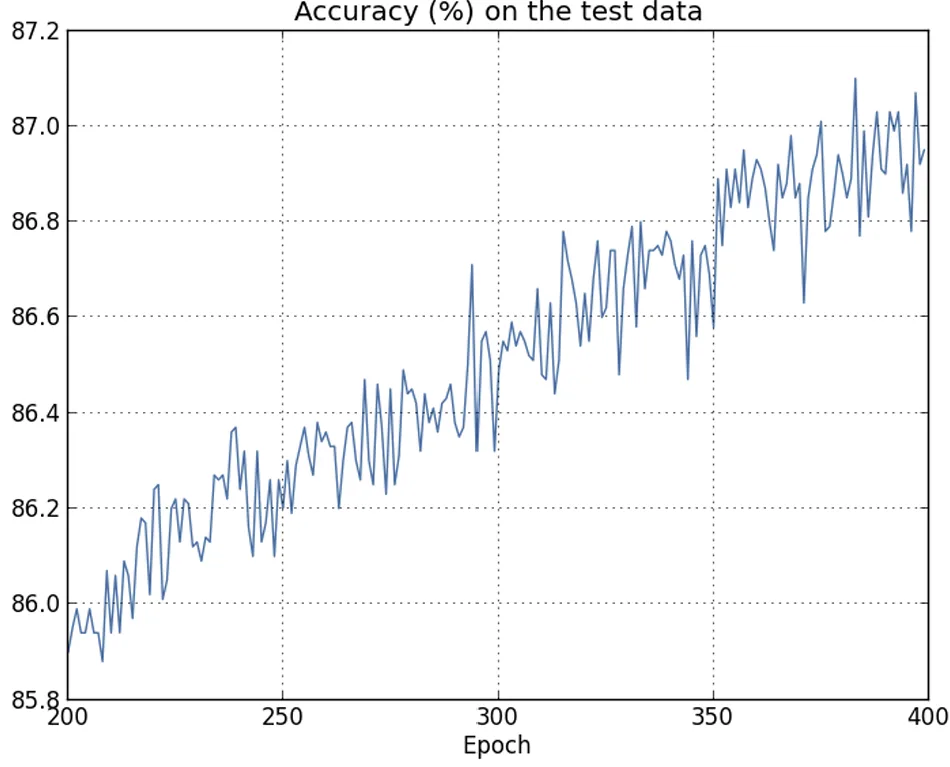 |
|---|---|
| La loss sui dati di training diminuisce durante tutto il tempo di training, in modo simile a quanto osservato nel caso senza regolarizzazione. | Questa volta l’accuratezza su test_data continua ad aumentare per tutte le 400 epoche. |
È evidente che l’utilizzo della regolarizzazione ha ridotto l’overfitting.
Inoltre, l’accuratezza ottenuta è sensibilmente più alta, con un picco di accuratezza nella classificazione pari all’, rispetto al picco dell’ ottenuto nel caso senza regolarizzazione.
Note
Si osserva che l’addestramento potrebbe proseguire oltre le 400 epoche, potenzialmente migliorando ancora i risultati.
Empiricamente, la regolarizzazione sembra favorire una migliore generalizzazione e ridurre in modo significativo l’overfitting.
Passaggio dal dataset ridotto a quello completo
Question
Cosa succede se si passa da un set di addestramento artificiale di 1.000 immagini al set completo di 50.000 immagini?
È stato già osservato che con il dataset completo, l’overfitting è meno problematico.
Tuttavia, si vuole verificare se la regolarizzazione continua ad apportare benefici.
Gli iperparametri vengono mantenuti invariati:
- Epoche: 30
- Learning rate: 0.5
- Mini-batch size: 10
🔧 Modifica del parametro di regolarizzazione
Dal momento che la dimensione del training set cambia da a , anche il fattore di weight decay subisce un cambiamento.
Se si mantenesse , il decadimento sarebbe troppo debole e l’effetto regolarizzante si ridurrebbe. Per compensare, si aumenta a 5.0.
Si procede quindi con l’addestramento della rete, dopo aver reinizializzato i pesi.
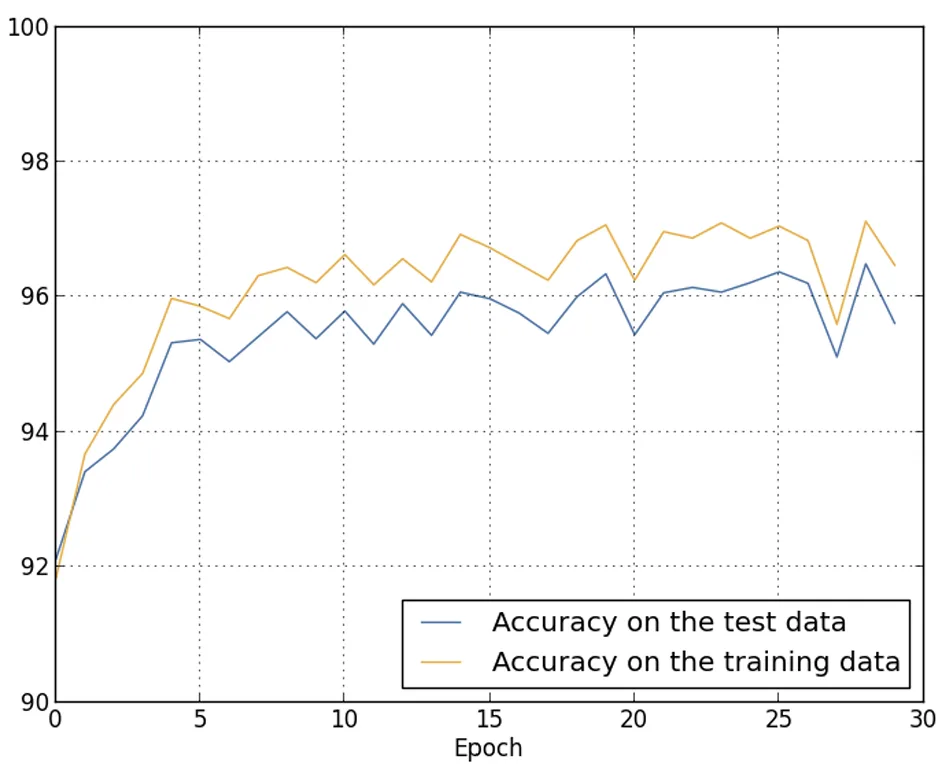
Si ottiene tale risultato:
Important
Ci sono diversi elementi positivi da evidenziare.
In primo luogo, l’accuratezza di classificazione sui dati di test è aumentata, passando dal 95,49% nel caso senza regolarizzazione al 96,49% con regolarizzazione. Si tratta di un miglioramento significativo.
In secondo luogo, si osserva che il divario tra i risultati sui dati di training e quelli sui dati di test si è notevolmente ridotto, attestandosi a meno dell’1%.
Pur trattandosi ancora di una differenza non trascurabile, è evidente che è stato compiuto un notevole passo avanti nella riduzione dell’overfitting.
Esperimento finale: 100 neuroni nascosti e regolarizzazione
Infine, si considera l’accuratezza di classificazione ottenuta utilizzando 100 neuroni nel layer nascosto e un parametro di regolarizzazione .
🎯 Goal
Non viene svolta un’analisi dettagliata dell’overfitting, poiché l’obiettivo è esclusivamente esplorativo: verificare quale livello di accuratezza si possa raggiungere combinando la funzione di costo cross-entropy con la regolarizzazione L2.
>>> net = network2.Network([784, 100, 10], cost=network2.CrossEntropyCost)
>>> net.large_weight_initializer()
>>> net.SGD(training_data, 30, 10, 0.5, lmbda=5.0, evaluation_data=validation_data, monitor_evaluation_accuracy=True)📈 Risultati
Il risultato finale è un’accuratezza del 97,92% sui dati di validazione, un notevole incremento rispetto al caso con 30 neuroni nascosti.
Con una leggera ottimizzazione degli iperparametri ( ad esempio eseguendo l’addestramento per 60 epoche, con learning rate e ) si riesce a superare la soglia del 98%, raggiungendo un’accuratezza del 98,04% sui dati di validazione.ℹ️ Il tutto con appena 152 righe di codice !!!
Benefici ulteriori della regolarizzazione
La regolarizzazione è stata descritta come un metodo per ridurre l’overfitting e migliorare l’accuratezza di classificazione.
Tuttavia, questo non è l’unico vantaggio osservato.Durante esecuzioni multiple della rete su MNIST, con diverse inizializzazioni casuali dei pesi, si è notato che:
- Le versioni non regolarizzate talvolta si “bloccano”, apparentemente intrappolate in minimi locali della funzione di costo.
- Di conseguenza, i risultati possono variare significativamente da una run all’altra.
Al contrario, le versioni regolarizzate tendono a restituire risultati molto più stabili e riproducibili.
🤔 Ipotesi euristica sul comportamento
In assenza di regolarizzazione, la norma del vettore dei pesi tende a crescere, a parità di altre condizioni.
Con il tempo, il vettore dei pesi può diventare molto grande, e ciò comporta che:
- Le modifiche introdotte dalla discesa del gradiente incidano poco sulla direzione del vettore (dato che il modulo è elevato).
- Il vettore dei pesi finisca per “puntare” nella stessa direzione, rendendo difficile per l’algoritmo di apprendimento adattarsi correttamente.
Questa dinamica può contribuire a rendere l’apprendimento meno efficace e meno stabile in assenza di regolarizzazione.