ReLU Alternatives and Their Key Characteristics
Overview: The "Dying ReLU" Problem
The standard ReLU () suffers from the “dying ReLU” problem: if a neuron falls into the negative regime (), its output is 0 and its gradient is 0. Consequently, weights are not updated during backpropagation, and the neuron becomes permanently inactive.
The LU family of variants mitigates this by allowing negative values to propagate through the network, preserving gradient flow and improving information transmission.
Comparison Table
| Activation Function | Mathematical Definition | Gradient for | Key Advantages |
|---|---|---|---|
| Leaky ReLU | with fixed (e.g., ) | Constant | Prevents dead neurons; computationally efficient (no exponentials). |
| PReLU (Parametric ReLU) | with learnable parameter | Learnable parameter | Adaptable shape; the network learns the optimal negative slope. |
| ELU (Exponential LU) | Approaches | Outputs have mean (faster convergence); robust to noise. | |
| SELU (Scaled ELU) | Scaled exponential | Self-normalizing: maintains mean 0 and unit variance across layers. | |
| GELU (Gaussian Error LU) | Approximated via or sigmoid | Smooth, non-monotonic curve | Probabilistic gating; implicit regularization; standard for Transformers. |
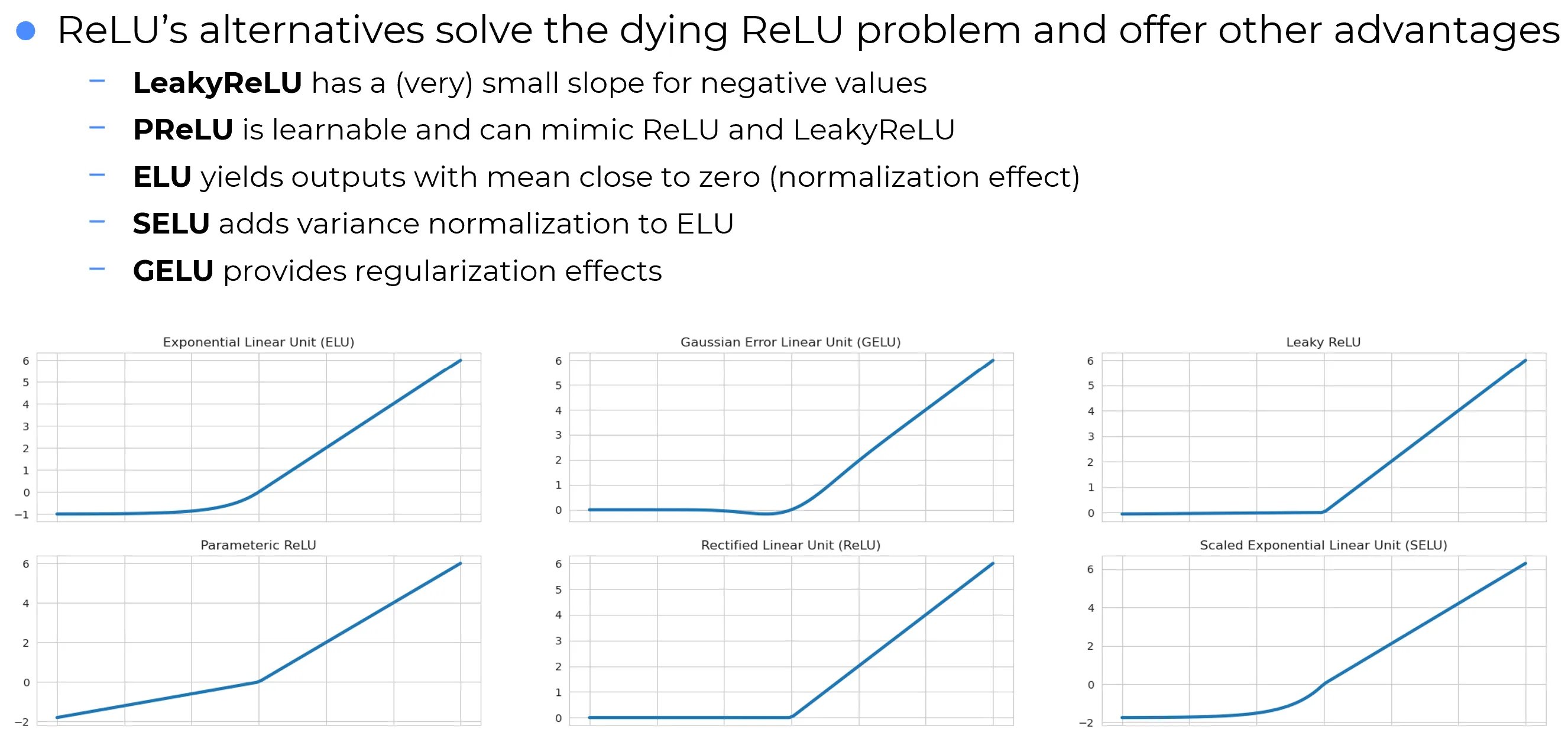
Detailed Analysis
1. Leaky ReLU
- Concept: A simple heuristic modification to standard ReLU. Instead of a hard zero for negative inputs, it introduces a small, fixed slope (typically ).
- Mechanism: if , and if .
- Benefit: Ensures that gradients never completely vanish (), allowing neurons to “recover” from the inactive state during training.
2. PReLU (Parametric ReLU)
- Citation: He et al., 2015
- Concept: Generalizes Leaky ReLU by treating the negative slope not as a hyperparameter, but as a learnable parameter to be optimized via backpropagation alongside weights and biases.
- Benefit: Significantly improves modeling capacity with negligible computational overhead (only one extra parameter per channel/neuron). It allows the network to decide whether it needs a linear response or a rectified one.
- Risk: Potential for overfitting on small datasets due to the increased degrees of freedom.
3. ELU (Exponential Linear Unit)
- Citation: Clevert et al., 2016
- Concept: Uses an exponential curve for negative values, saturating at .
- Benefit (Bias Shift): Unlike ReLU, which is non-negative (mean > 0), ELU produces negative outputs. This brings the mean of the activations closer to zero, functioning as a form of implicit normalization. This reduces the bias shift effect, speeding up convergence.
- Robustness: The saturation at makes the neuron robust to large negative noise.
4. SELU (Scaled Exponential Linear Unit)
- Citation: Klambauer et al., 2017 (Self-Normalizing Neural Networks)
- Concept: A specialized version of ELU equipped with fixed scale factors derived from fixed-point theory:
- Benefit (Self-Normalization): If weights are initialized correctly (LeCun Normal) and inputs are standardized, SELU guarantees that the output of each layer preserves a mean of 0 and a variance of 1. This eliminates the need for explicit Batch Normalization in very deep Fully Connected Networks (FNNs).
5. GELU (Gaussian Error Linear Unit)
- Citation: Hendrycks & Gimpel, 2016
- Concept: It weighs the input by its percentile in a Gaussian distribution: .
- Often approximated as: .
- Benefit (Stochastic Regularization): It can be seen as a smooth expectation of Dropout applied to ReLU. Unlike ReLU’s sharp corner at 0, GELU is smooth ( differentiable) and non-monotonic.
- Dominance: Because of its smoothness and curvature, it aids optimization in complex landscapes, making it the de-facto standard for Large Language Models (BERT, GPT-3/4, Llama).
Selection Guide: Which one to use?
The choice of activation function is a trade-off between gradient flow, computational cost, and inductive bias.
-
Standard Computer Vision (CNNs):
- Recommendation: ReLU or Leaky ReLU.
- Reasoning: Computational sparsity and efficiency are paramount on GPUs. The linearity of ReLU often suffices for convolutional feature extraction.
-
Deep Fully Connected Networks (without Batch Norm):
- Recommendation: SELU.
- Reasoning: Without normalization layers, deep networks suffer from exploding/vanishing gradients. SELU’s self-normalizing property stabilizes the variance propagation automatically.
-
Transformers & LLMs (NLP):
- Recommendation: GELU (or Swish/SiLU).
- Reasoning: These models require capturing complex, non-linear relationships in high-dimensional spaces. The smoothness of GELU aids the optimizer (e.g., AdamW) in navigating the loss landscape more effectively than the sharp kink of ReLU.
Practical Rule of Thumb
- Start with ReLU for simple baselines.
- If the network is dying (gradients vanish), switch to Leaky ReLU or GELU.
- If you are building a Transformer/LLM, use GELU by default.