Glorot & Bengio (2011)
«Per ridurre il vanishing gradient si preferiscono funzioni di attivazione non limitate, come la Rectified Linear Unit.»
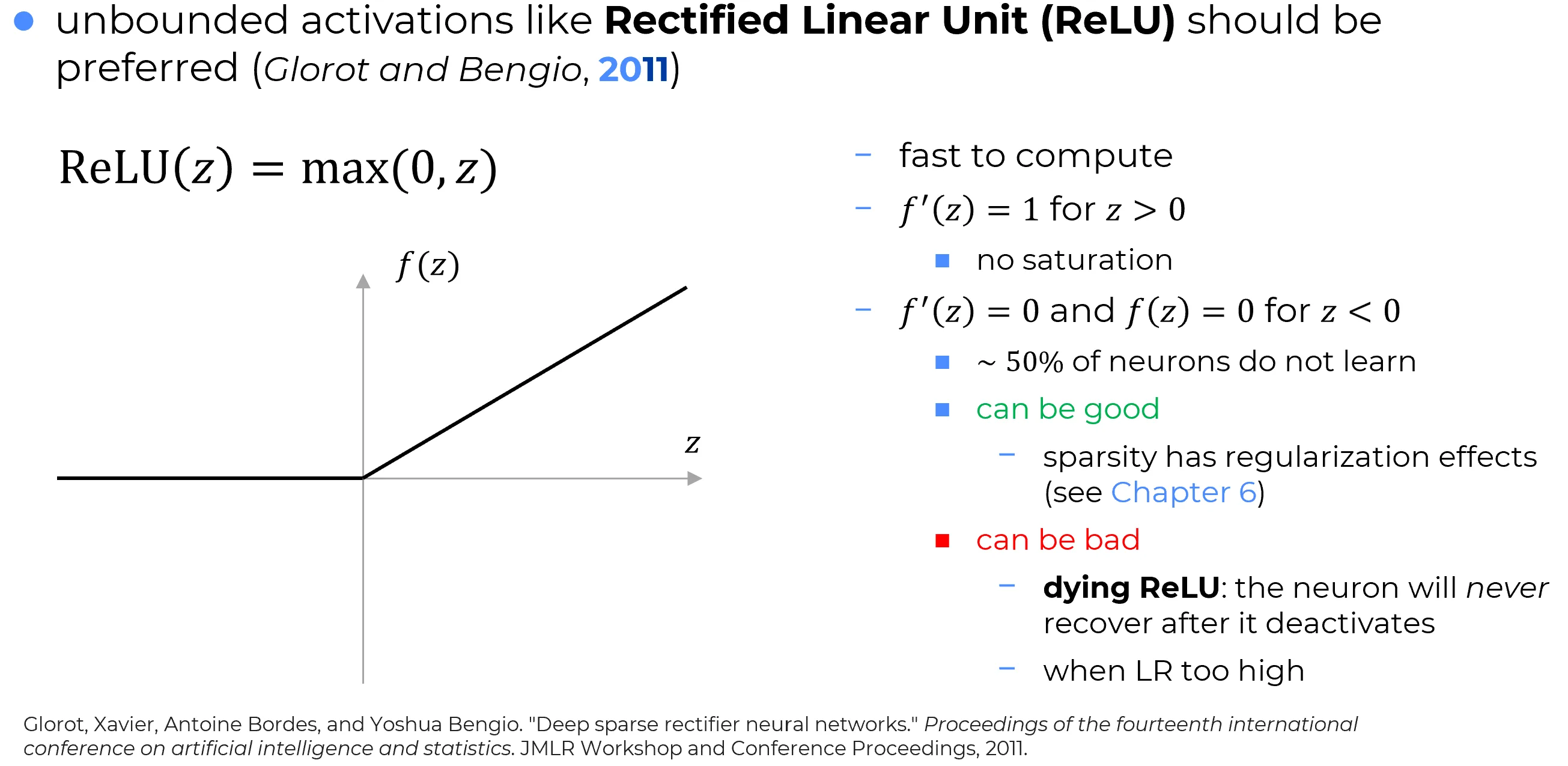
Definizione
La funzione di attivazione ReLU (Rectified Linear Unit) è definita come:
Vantaggi principali della ReLU
Computazionalmente economica:
Il calcolo richiede solo un’operazione di tipo , meno onerosa rispetto ad altre funzioni di attivazione più complesse.
Preservazione del gradiente:
Per la derivata è costante:
Nei layer profondi, dove normalmente il gradiente tende a svanire a causa della moltiplicazione di derivate , la ReLU permette al gradiente di mantenere ampiezza sufficiente per raggiungere anche i primi layer, facilitando l’addestramento delle reti profonde.
Limiti e implicazioni della ReLU
Important
Per la ReLU restituisce e .
Poiché metà del dominio dell’input viene annullata, se tutto è inizializzato uniformemente, ≈ 50% dei neuroni risulta inattivo fin dall’inizio.
Pro — Sparsità
- Una parte della rete rimane inattiva, riducendo il rischio di overfitting.
Infatti, se tutti i neuroni sono attivi, è più probabile che la rete memorizzi i pattern presenti nei dati di input, perdendo capacità di generalizzazione su dati nuovi.
Al contrario, se solo una parte della rete viene effettivamente utilizzata, diminuisce la probabilità che la rete si limiti a memorizzare i dati di training, favorendo una maggiore capacità di generalizzazione.- La sparsità è stocastica:
a ogni iterazione alcuni neuroni si attivano, altri si disattivano, favorendo rappresentazioni dinamiche e robuste.
Contro — Dying ReLU
- Se , la derivata e il neurone smette di aggiornarsi.
Con un learning rate elevato, è più probabile che il neurone venga “spinto” nel dominio negativo (ossia passi da una zona di attivazione a una zona di disattivazione) e una volta lì, a causa del gradiente nullo, rimane bloccato e non si riattiva più: muore.- Se un learning rate elevato induce molti neuroni a “morire”, la rete collassa progressivamente, riducendo drasticamente la sua capacità espressiva.
- La ReLU si rivela dunque un’arma a doppio taglio: eccellente in certi contesti, ma pericolosa in altri (e.g. NLP).
Quando usare (o evitare) la ReLU
✅ Ottima per immagini:
- È stato empiricamente osservato che l’enorme eterogeneità locale delle immagini riduce significativamente la probabilità del fenomeno di Dying ReLU.
Ogni patch di un’immagine tende a essere unica, garantendo una variabilità elevata negli input ai neuroni, e minimizzando il rischio che molti neuroni vengano spinti stabilmente in zona .
Per questo la ReLU funziona molto bene in ambito computer vision.
Bannata in NLP (bassa eterogeneità → rischio dying ReLU):
- Nei dati testuali, le sequenze di parole (es. bigrammi, trigrammi) si ripetono frequentemente, generando input meno variabili nei layer della rete. Ciò aumenta la probabilità che i neuroni saturino nel dominio negativo (), restando intrappolati con derivata nulla (neuroni morti). Pertanto, nei Large Language Models (LLM) la ReLU è bannata
Funzione continua ma non differenziabile ovunque
La funzione è continua su tutto , ma non è differenziabile in . Infatti:
Per , la derivata è .
Per , la derivata è .
In , la derivata non esiste, poiché il limite sinistro e destro non coincidono:
⚡ Backpropagation con ReLU in PyTorch
La ReLU non è differenziabile in . PyTorch gestisce questo caso definendo convenzionalmente:
- Gradiente = 1 per ,
- Gradiente = 0 per .
✅ Questo trucco non compromette l’efficacia della ReLU, che continua a funzionare bene in addestramento.