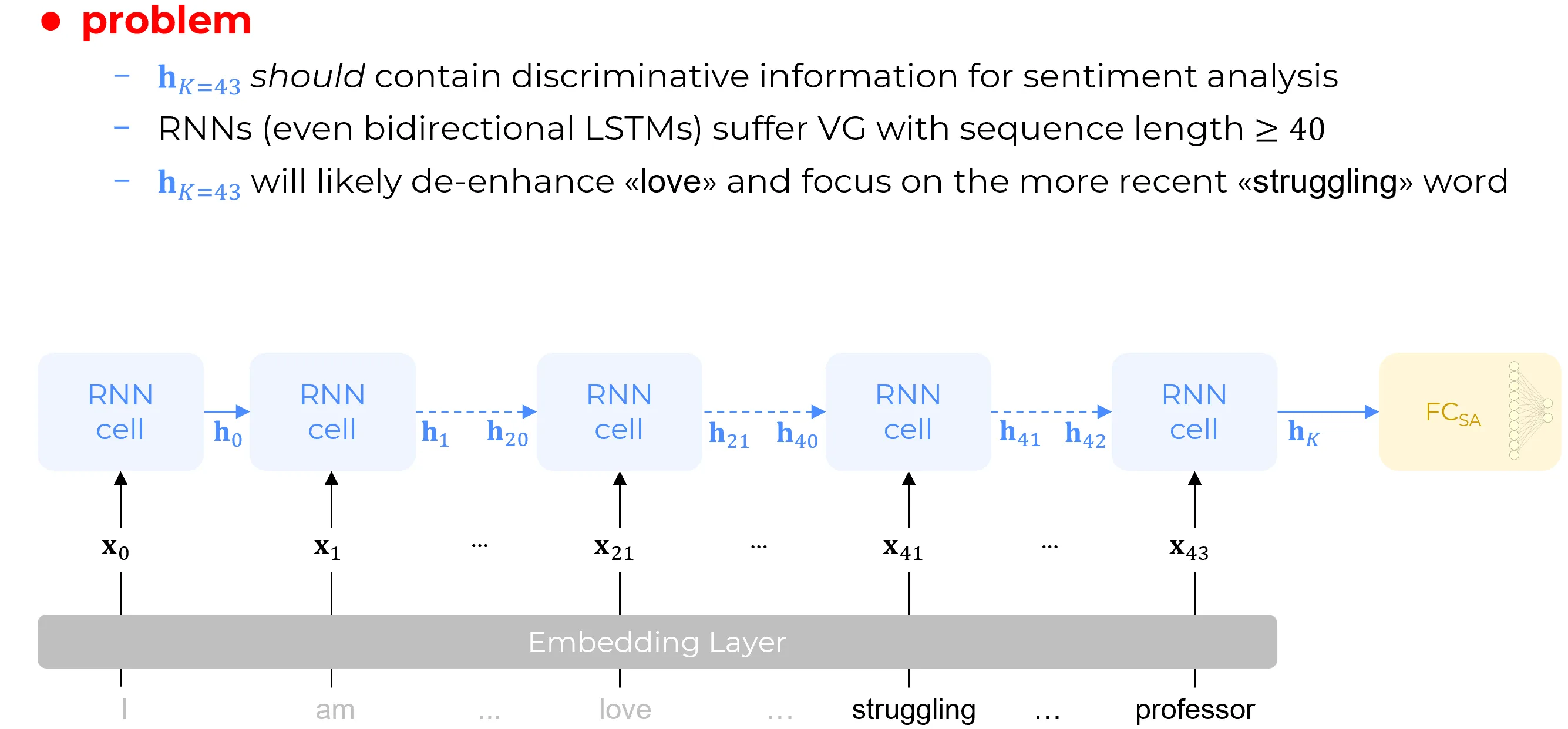
the last hidden state vector should contain discriminative information for sentiment analysis however LSTMs and GRUs (even bidirectional LSTMs) and other variations of the vanilla RNN layer they do suffer of vanishing gradient problem (inserisci qui riferimento) with sequence length : it has been empirically demonstrated that even thought the LSTM is designed to model somehow memory and state (we’ve seen how this is done using the gates), however the information that is kept , retained in the hidden state vector and also in the cell state in the case of the LSTM is forgotten after some iteration because of the vanishing gradient. So is the maximum span of memory of traditional recurrent nets and now we have a sentence that is words long so this feature vector will likely focus on the most recent words and likely not remembering the less recent ones. If we consider the whole tweet again then the last hidden state vector will mainly see the second part of the sentence (struggling … professor) because the first part of the sentence (I .. am ..love) will likely be forgotten.
The word “love” is in the first part of the sentence so now we have the hidden state vector that is actually encoding the second part of the sentence which is not positive: “hard” and “struggling” are not a positive term. So the hidden state vector will likely contain negative features that will be likely to be recognized by the fully connect sentiment analysis to be a negative emotion even though the overall message conveyed by tweet is a positive one. This is what we call misunderstanding: the network is misunderstanding the tweet because it is not considering the whole sentence of the tweet but just the few last words. This comes to the following meme where the computer stand for chatbots based on RNNs architecture. These chatbots pre transformers era didn’t understand context, they were likely answering correctly a single question if the information was somewhere local to that context but if the information was two, three, four, five sentences earlier than the current then there was no way the chatbot was giving the expected answer. Similar reason hold for the sentence translation because sentence translation require a full understanding of the context.
Sebbene la parola “amore” (love) si trovi nella parte iniziale della frase, il vettore di stato nascosto finale, , codifica di fatto la porzione conclusiva della sequenza, la quale non presenta una valenza positiva: termini come “difficile” (hard) e “faticoso” (struggling) non sono positivi.
Di conseguenza, è probabile che il vettore di stato nascosto contenga feature semantiche negative, le quali verrebbero a loro volta interpretate dallo strato densamente connesso () come indicative di un’emozione negativa, nonostante il messaggio complessivo veicolato dal tweet sia di natura positiva. Questo fenomeno è definibile come un’incomprensione (misunderstanding): la rete fraintende il significato del tweet poiché non considera la frase nella sua interezza, ma si limita a ponderare unicamente le parole più recenti.
Tale limite concettuale richiama i meme seguenti, nel quale il computer simboleggia i chatbot basati su architetture di tipo RNN. Nell’era precedente all’avvento dei Transformer, questi assistenti virtuali mostravano una scarsa capacità di comprendere il contesto. Erano in grado di rispondere correttamente a una singola domanda solo qualora l’informazione necessaria fosse localizzata nelle immediate vicinanze; tuttavia, se tale informazione risiedeva in frasi precedenti di due, tre, quattro o cinque posizioni, era pressoché impossibile per il chatbot fornire la risposta attesa.
Un ragionamento analogo si applica alla traduzione automatica delle frasi, giacché anche tale compito richiede una comprensione olistica e completa del contesto.
✅ Solution 1: Concatenation
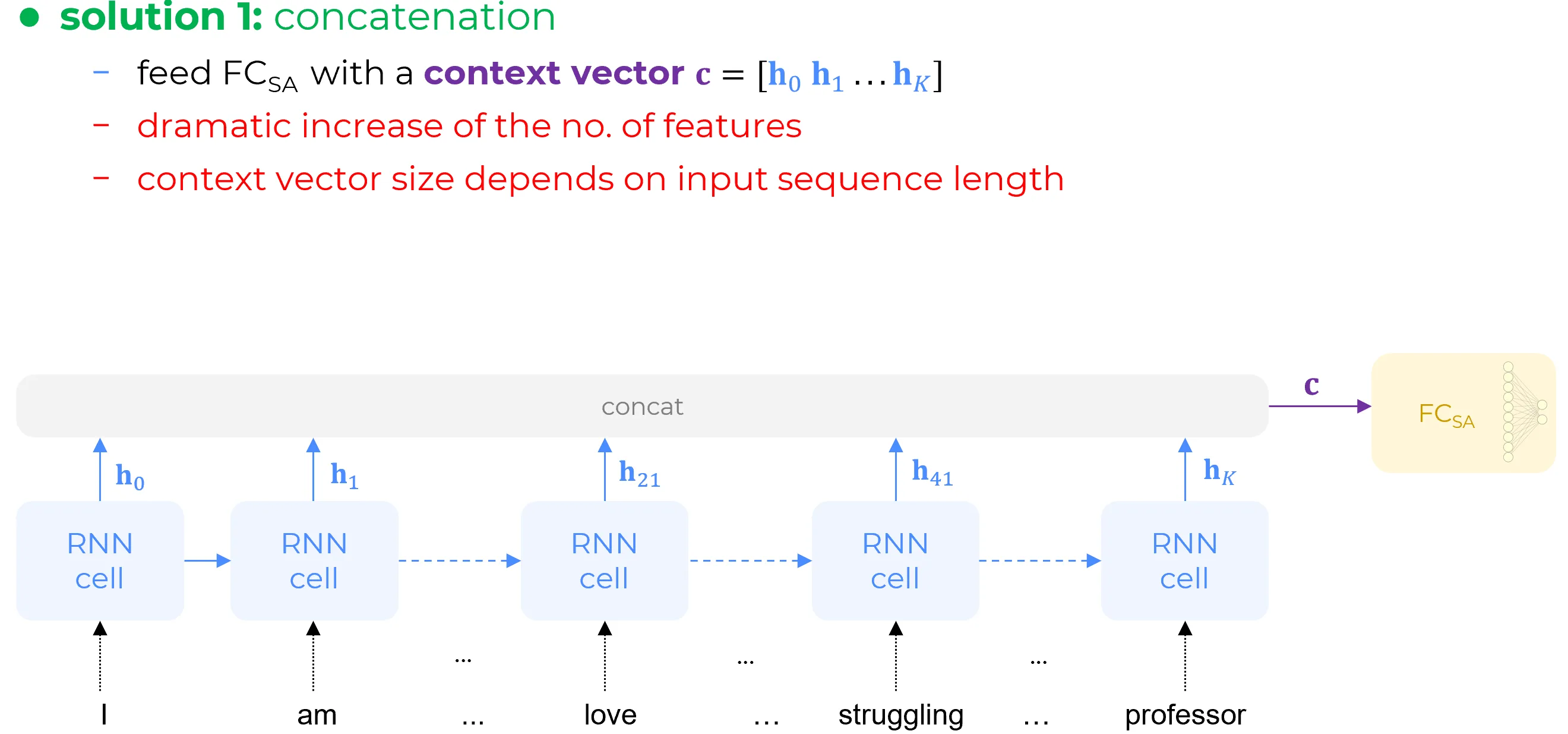
A possible solution is to concatenate all of the hidden state vectors for the entire sequence and mow should contain all the information. So if the problem is that we forgot some information then let’s just use all available hidden state vectors together but unfortunately doing this via concatenation the number of features will increase dramatically because if each hidden state vector has let’s say 100 hundred feature then by concatenating of such vectors will yield features. This means that solving the problem by concatenating all hidden state vector for the entire sequence produces a number of features which scales exponentially with the length of the sequence of words. What if a book is give as input to this architecture? Modern transformers can handling a book easily but in this case is a problem. Another problem is that with concatenation then context vector resulting from the concatenation of all the hidden state vectors would depend on the sequence length
Una soluzione potenziale consiste nel concatenare tutti i vettori di stato nascosto generati per l’intera sequenza. In questo modo, il vettore di contesto risultante dovrebbe, in teoria, contenere l’informazione completa. Se il problema risiede nella perdita di informazione pregressa, l’impiego congiunto di tutti i vettori di stato nascosto disponibili appare come un approccio logico.
Tuttavia, realizzare ciò mediante concatenazione introduce una criticità notevole: il numero di caratteristiche (features) aumenta in modo drastico. Infatti, supponendo che ciascun vettore di stato nascosto abbia, ad esempio, 100 caratteristiche, la concatenazione di 43 di tali vettori produrrebbe un vettore finale di 4300 caratteristiche. Ciò significa che la risoluzione del problema tramite questa tecnica genera un numero di caratteristiche che scala linearmente () con la lunghezza della sequenza.
Cosa accadrebbe se si fornisse in input a tale architettura un intero libro? Le moderne architetture Transformer sono in grado di gestire facilmente una simile mole di dati, ma nel caso delle RNN ciò costituirebbe un ostacolo insormontabile.
Un’ulteriore problematica risiede nel fatto che, con la concatenazione, il vettore di contesto risultante avrebbe una dimensione variabile, direttamente dipendente dalla lunghezza della sequenza in input, rendendo impossibile l’utilizzo di strati successivi a dimensione fissa.
✅ Solution 2: Combination
Another solution is replacing the concatenation of all hidden state vector by averaging them. Averaging has solved the problem because now being the context vector obtained by averaging all the hidden state vectors it has the same size as individual hidden state vectors. However this works under the assumption that all the hidden state vectors are equally important.
We would like to have a mechanism that will give more importance to elements of the sequence which are more relevant for the subsequent task.
