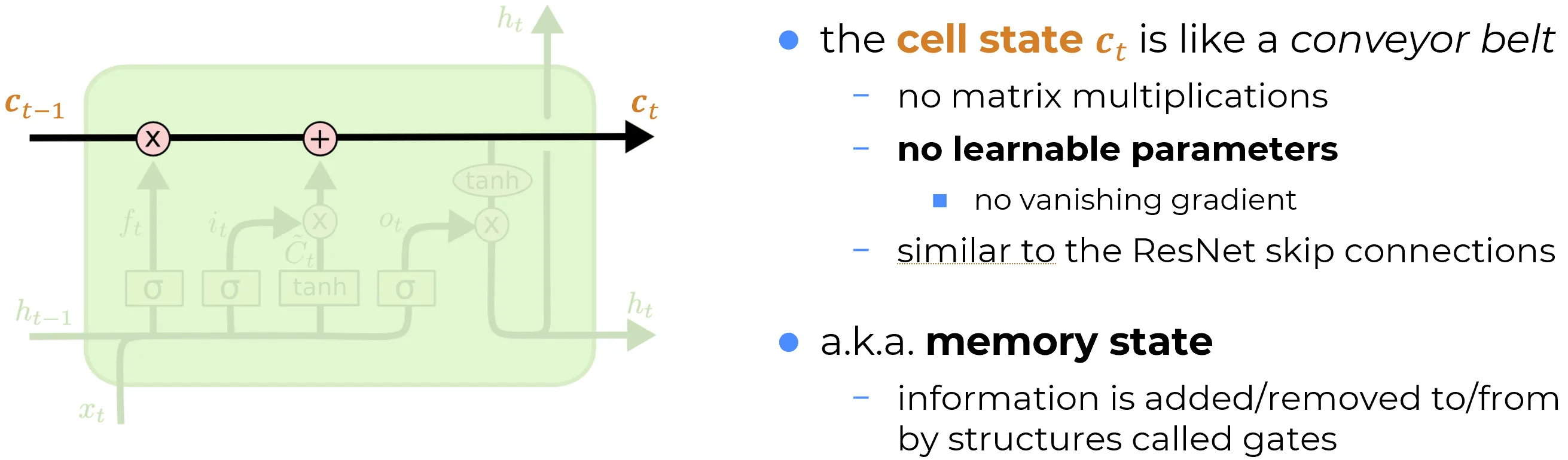
The black line at the top of the diagram is the cell state . It is the single most important object in the LSTM, because it is the place where the architectural fix anticipated in Vanilla RNNs limitations is implemented. Everything else in the cell exists to regulate what happens on this line.
What the line actually contains
Along the cell-state path, between on the left and on the right, only two operations are performed:
- an element-wise multiplication by the forget gate ;
- an element-wise addition of the gated candidate .
The resulting update is
The forget gate , the input gate and the candidate are produced by separate small networks, off to the side; they connect to the cell-state line only through the two junctions. The line itself never crosses a weight matrix and never goes through a non-linearity.
Dimensions used in this note
symbol role shape cell state gates (defined elsewhere) candidate update (defined in [[input-gate Input gate]]) All element-wise products on this line act on operands of identical shape , so no broadcasting is involved.
No parameters on the carry path
Read the diagram once more with this in mind: the route from to contains zero learnable weights and zero saturating activations. The gates inject parameters into the path through pointwise products, but the path itself is purely arithmetic.
This is what makes the cell state a skip connection along time. Information and gradient can travel along it for hundreds of steps without being squeezed through a matrix product or a tanh; the only thing that can attenuate them is the forget gate, and that attenuation is learned, not imposed.
Why this is the cure for vanishing gradients
The recurrent Jacobian along the cell-state line is, by direct differentiation of the update equation,
Coordinate independence: "no cross-coordinate mixing"
The Jacobian above is diagonal, not just small or bounded. The reason is a structural property of the operations on the cell-state line: the element-wise product , the pointwise sigmoid and the pointwise tanh all act one coordinate at a time,
never producing terms in which an output coordinate depends on an input coordinate . This is the property referred to throughout the LSTM notes as “no cross-coordinate mixing”, or equivalently coordinate independence of the update.
Inside the LSTM, cross-coordinate mixing happens only in the four affine maps that produce the gates and the candidate. The cell-state line itself, between and , is by construction free of any such mixing, and that is why its Jacobian is diagonal at every step. The derivation below makes this concrete.
Derivation, coordinate by coordinate
Writing the cell state update component by component, the -th coordinate of is
Two facts make this expression easy to differentiate with respect to :
- Coordinate independence of (see the callout above): depends on only when .
- The gates , and the candidate are functions of , not of , so they are constants under this partial derivative.
Both facts together give
where is the Kronecker delta. Stacked into a matrix, this is the diagonal matrix with on the diagonal:
The implication of coordinate independence is that each slot of the cell state evolves as an independent scalar register, a point developed in Input gate.
Compare this with the vanilla RNN Jacobian derived in BPTT Problems,
and the structural difference becomes visible at a glance. The vanilla Jacobian is a dense matrix scaled by the slope of : its spectral norm depends on , and the product across time either decays or blows up geometrically. The LSTM Jacobian is diagonal and bounded in per coordinate: across steps the product is
still diagonal, still bounded coordinate by coordinate. Setting along a direction keeps the product close to the identity for arbitrarily many steps; the gradient survives.
Why the product of diagonal matrices is diagonal
For two diagonal matrices and of the same size, ordinary matrix multiplication gives
So the product is again diagonal, and its -th diagonal entry is the product of the -th entries of and . Equivalently:
Iterating, the product of diagonal matrices is the diagonal matrix of element-wise products:
This is what makes the gradient analysis along the cell-state line a per-coordinate statement: there is no mixing across coordinates as steps accumulate.
The full backward-pass analysis is carried out in Gradient in LSTM.
The constant error carousel
In the original Hochreiter–Schmidhuber paper, the configuration , is called the Constant Error Carousel (CEC): the cell state evolves as and the error signal travels along the carousel without any change in magnitude. The 1997 paper actually proposed the cell with this CEC as the centerpiece; the forget gate was added later by Gers, Schmidhuber and Cummins in 2000 so that the carousel could also learn to stop.
The cell state is a leaky integrator
With the gates held fixed for a moment, and , substitute the scalar recursion into itself repeatedly:
Each step pushes the running memory through one more factor of , so the input from steps ago survives with weight : each slot is an exponentially weighted moving average of its past inputs. This is the same exponential average that drives the velocity in momentum and the moments in Adam. The weights sum to for , so the slot’s memory horizon is about steps: a decay of remembers roughly a hundred steps, a thousand, and the constant error carousel is the limit with infinite horizon.
The one thing the LSTM adds over a fixed moving average is that is recomputed at every step from . The decay is data-dependent and per-coordinate, so the cell can lengthen or shorten the memory of each slot in response to what it is currently reading.
The architectural pattern this exemplifies
The cell-state line is the historical ancestor of a pattern that recurs throughout modern deep learning: isolate an identity path through the model, and let learned modules perturb the state living on that path, never carry it themselves.
- In a ResNet block, the input travels through the identity shortcut while a small residual function is added to it. The Jacobian of with respect to is , so gradient flows through unimpeded across depth.
- In a Transformer block, the residual stream plays exactly the same role across layers, with attention and MLP sublayers contributing additive updates.
- In the LSTM cell, the cell state is the residual stream across time, with the gated update playing the role of and the forget gate adding a learned per-coordinate decay.
The LSTM came first, in 1997, six years before residual connections were introduced in feedforward networks by He et al. (2015). Reading it as a temporal residual stream is the cleanest way to see why it works, and why the same idea later made very deep feedforward and Transformer architectures possible.
One difference worth naming
A vanilla residual connection has Jacobian exactly on the shortcut: it never forgets. The LSTM’s Jacobian along the cell state is , which can decide to forget on a per-coordinate, per-step basis. The cell state is, in this sense, a learnable residual stream, slightly more expressive than a static identity shortcut. This added flexibility is also what makes the LSTM’s memory finite in practice: it can choose to clear itself.
That same data-dependent decay is the idea selective state-space models (Mamba, 2023) later reintroduced to rival attention on long sequences. Classical linear state-space models fix their recurrence coefficients, which parallelizes cleanly across time but cannot choose what to keep; making those coefficients input-dependent, exactly as the forget gate does, restores the selectivity. The LSTM had the mechanism in 1997, and the later work kept the input-dependent gating while changing only how it is computed, so that it parallelizes across the sequence.
The next three notes build the gates that act on this line one at a time, in the order in which they touch : the forget gate first, which scales ; then the input gate together with the candidate , which add new content; and finally the output gate, which decides how much of the updated to expose as the hidden state .