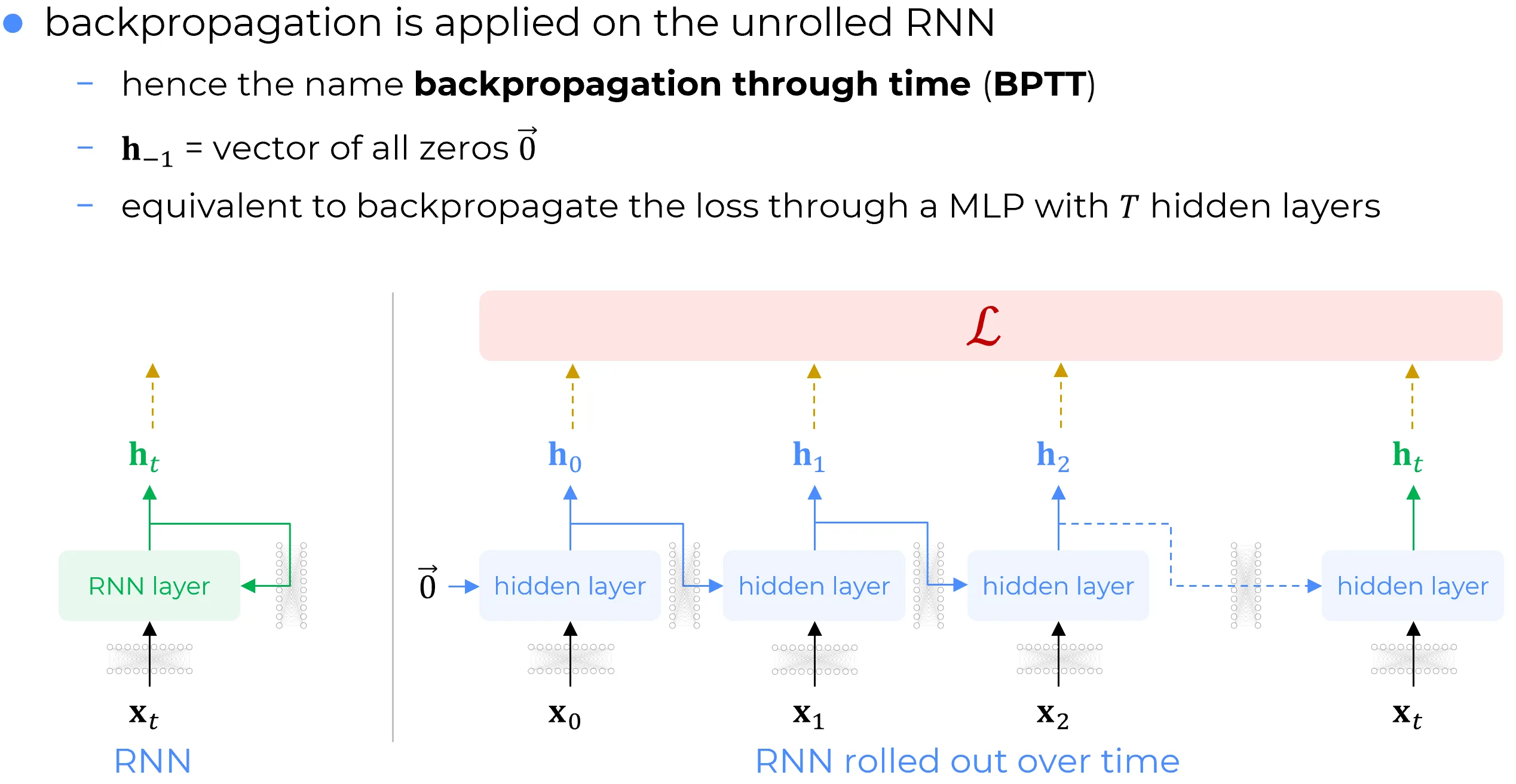
L’algoritmo di retropropagazione, quando applicato alla versione esplicitamente srotolata (unrolled) di una Rete Neurale Ricorrente (RNN) lungo un numero finito di passi temporali, prende il nome di Backpropagation Through Time (BPTT).
Tale procedura consiste, in sostanza, nell’applicazione dell’algoritmo di backpropagation canonico (nella sua declinazione agli MLP) alla versione srotolata dello strato di RNN, estesa per tutta la sequenza temporale desiderata. La lunghezza di tale sequenza costituisce, a tutti gli effetti, un iperparametro del modello.
Question
Come si procede all’inizializzazione del vettore di stato nascosto relativo al passo temporale precedente all’inzio della sequenza (cioè per )?
Note
Si osservi che al primo passo temporale (), non essendo disponibile uno stato precedente, si assume convenzionalmente:
ovvero un vettore nullo. Tale scelta è analoga allo zero-padding utilizzato nelle reti convoluzionali: come in quel contesto si applica uno zero padding ai bordi spaziali, qui mutatis mutandis l’operazione è eseguita al confine temporale della sequenza.
Dunque, la BPTT è concettualmente equivalente alla backpropagation della funzione di loss attraverso un Multi-Layer Perceptron (MLP) molto profondo, che possiede T layer nascosti.
Detailed derivation
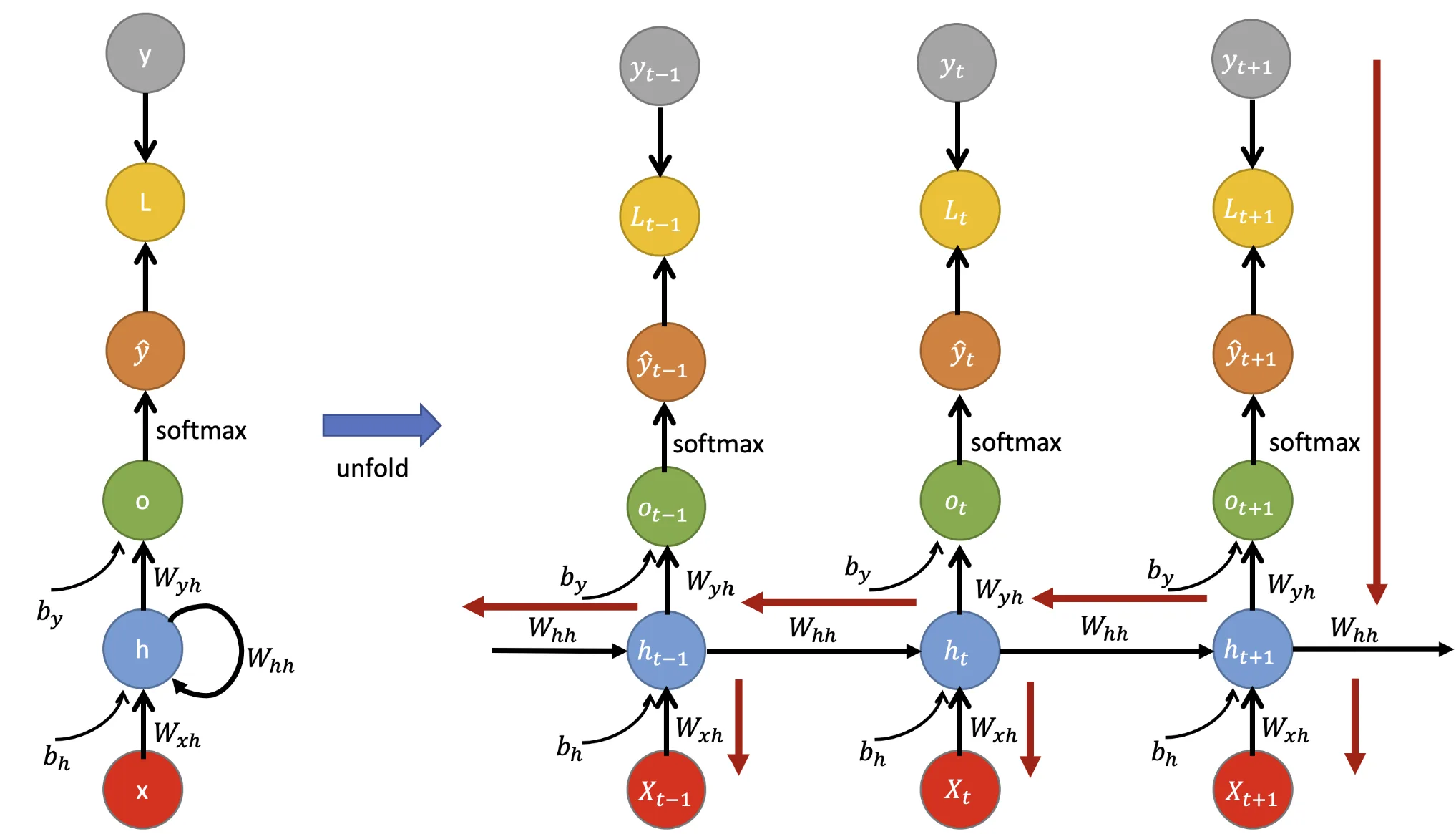
Per una derivazione esplicita dell’algoritmo di Backpropagation Through Time (BPTT), si adotta una rappresentazione del RNN “srotolata” lungo l’asse temporale più esplicita della versione riportata nella figura precedente.
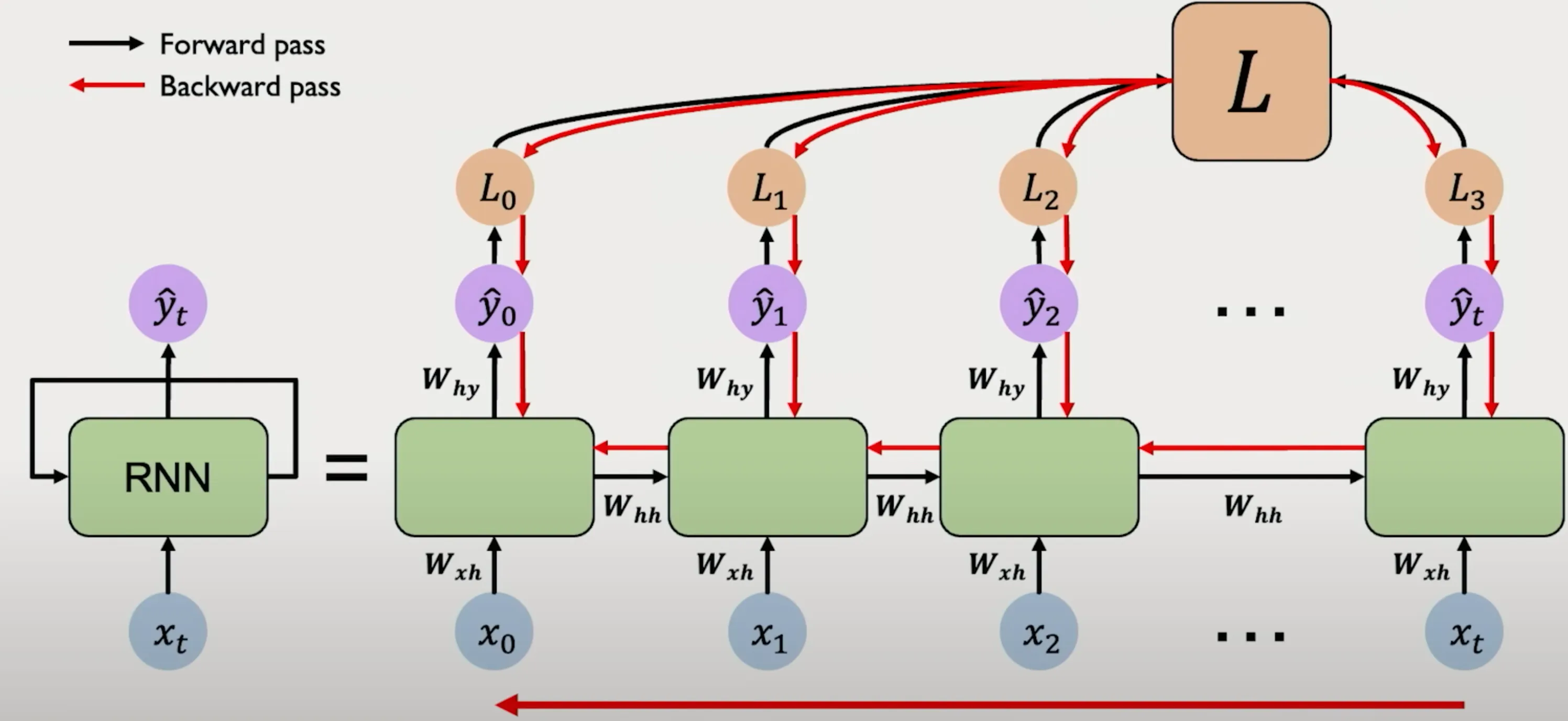
| Componente / Simbolo | Descrizione |
|---|---|
| Numero delle classi del task di classificazione in esame | |
| , , | Le Matrici dei Pesi , nonostante siano rappresentate graficamente per ciascun passo temporale, sono in realtà condivise nel tempo (parameters sharing). Tale condivisione riduce il numero complessivo di parametri e riflette la natura ricorrente del modello. |
| Rappresenta il vettore colonna di dati input al passo , con dimensione . | |
| Rappresenta lo stato nascosto al passo , con dimensione. | |
| Rappresenta l’output grezzo (logit) intermedio, con dimensione. | |
| Rappresenta il vettore delle probabilità predette. Tale output viene ottenuto applicando la funzione softmax all’output grezzo (logit) . Tale funzione è definita, per ogni componente , come: dove è il numero delle classi. Il softmax assicura che sia un vettore di probabilità, rendendolo adatto alla classificazione multiclasse e compatibile con l’impiego della cross-entropy come funzione di costo. | |
| È la funzione di costo (loss function). | |
| Fasi di Propagazione | La propagazione avviene in due fasi distinte: - Forward pass, indicata dalle , in cui l’input e lo stato precedente vengono combinati per generare il nuovo stato nascosto e il successivo output. - Backward pass, indicata dalle , in cui il gradiente della loss totale viene retropropagato attraverso gli step temporali, aggiornando i pesi condivisi. |
RNN come Sistema Dinamico
Formalmente, una Rete Neurale Ricorrente (RNN) convenzionale può essere riguardata come un sistema dinamico caratterizzato da una funzione di transizione, che aggiorna lo stato interno della rete, e una funzione di output, che produce il risultato finale.
Formulazione per singolo dato sequenziale
Nel caso di singola sequenza tale sistema dinamico, descritto in forma esplicita, è definito dalle seguenti equazioni:
Declinando le funzioni di transizione e di output che caratterizzano una Rete Neurale Ricorrente (RNN) convenzionale per una singola istanza (ovvero, un passo temporale ), si ottengono le seguenti equazioni:
dove le funzioni e , rappresentano funzioni non lineari applicate elemento per elemento (element-wise). In particolare:
- è una funzione di attivazione non lineare applicata elemento per elemento (i.e. tanh())
- è una softmax. A rigore la funzione di attivazione per il layer di output, , viene scelta in base al compito task. Nel contesto di problemi di classificazione, essa è generalmente la funzione softmax, poiché il suo output può essere interpretato come una distribuzione di probabilità sulle classi.
| Simbolo | Dimensione | Descrizione |
|---|---|---|
| Vettore di input al tempo . | ||
| , | Stato nascosto precedente / aggiornato al tempo . | |
| Logit (output grezzo) a monte del softmax. | ||
| Vettore di probabilità predette (a valle del softmax). | ||
| Matrice di Pesi input → hidden. | ||
| Matrice di Pesi hidden → hidden (ricorrenza). | ||
| Matrice di Pesi hidden → output. | ||
| Bias del layer nascosto (broadcast sul vettore ). | ||
| Bias dello strato di output (broadcast sul vettore ). | ||
| — | Funzione di attivazione non lineare (). | |
| — | Funzione di output (softmax nei problemi di classificazione). | |
| Loss locale al tempo (scalare). |
Formulazione per un Mini-Batch di dati sequenziali
Important
A fini di efficienza computazionale, in fase di addestramento è prassi comune elaborare più sequenze contemporaneamente tramite la usuale gestione per mini-batch. In questo contesto, l’input vettoriale di un singolo passo temporale viene generalizzato a una matrice di input , dove rappresenta la dimensione del mini-batch.
In modo analogo, lo stato nascosto del passo precedente viene aggregato in una matrice , dove ogni riga contiene lo stato nascosto associato alla rispettiva sequenza del batch.
L’output del layer ricorrente può quindi essere calcolato per l’intero batch come segue:
dove:
-
è la matrice degli input al tempo ,
-
è la matrice degli hidden states al passo ,
-
contiene i nuovi hidden states calcolati al tempo ,
-
sono i logits grezzi per ciascun esempio del batch,
-
rappresenta il vettore delle probabilità predette a valle dell’applicazione del softmax.
Per completezza, si riportano le dimensioni associate ai principali tensori del modello:
| Simbolo | Dimensione | Descrizione |
|---|---|---|
| Input del mini-batch al tempo | ||
| Hidden state del mini-batch al tempo | ||
| Matrice dei pesi input → hidden | ||
| Matrice dei pesi hidden → hidden | ||
| Matrice dei pesi hidden → output | ||
| (broadcast implicito a ) | Bias dello stato nascosto | |
| (broadcast implicito a ) | Bias dello strato di output | |
| Output predetto per il mini-batch al tempo |
Perché compaiono le matrici dei pesi trasposte e ?
L’uso della trasposizione è una convenzione implementativa per conciliare la formulazione matematica teorica con l’elaborazione efficiente dei mini-batch.
- Scenario Teorico (Singola Sequenza): L’input è un vettore colonna . La matrice dei pesi ha dimensione e la moltiplicazione è , dimensionalmente corretta.
- Scenario Pratico (Mini-Batch): L’input è una matrice . Un prodotto diretto sarebbe impossibile per incongruenza dimensionale ❌.
Trasponendo la matrice dei pesi, il calcolo diventa possibile e restituisce la corretta matrice di output ✅.
Questa pratica permette di mantenere una definizione coerente dei pesi e di semplificare il codice. Librerie come PyTorch la adottano come standard di design: un layer
nn.Linearviene definito con pesi di forma[out_features, in_features], ma il suo calcolo interno per gestire i batch esegue l’operazione comeinput @ weight.T. Questo meccanismo efficiente è applicato a tutte le matrici di pesi all’interno dei moduli RNN, coniugando chiarezza teorica e performance pratica.
Notazione compatta per input e stato nascosto
In molte implementazioni ottimizzate, è comune accorpare in un’unica matrice l’input al tempo , ossia la matrice , e lo stato nascosto precedente . In particolare, si costruisce la matrice concatenata orizzontalmente , dove:
- contiene gli input per ciascun elemento del mini‑batch;
- contiene i rispettivi hidden states al tempo precedente.
A questa concatenazione viene associata un’unica matrice dei pesi estesa , ottenuta impilando verticalmente le matrici e :
In questo modo, l’operazione di transizione ricorrente può essere scritta in forma compatta:
Questa notazione semplifica il codice e riduce il numero di operazioni di moltiplicazione, ed è perfettamente compatibile con le librerie tensoriali (e.g. PyTorch, TensorFlow), in cui le operazioni batched sono altamente ottimizzate.
Note
Al primo passo temporale (), non essendo ancora definito uno stato nascosto precedente, è consuetudine inizializzare:
\mathbf{H}_{-1} = \mathbf{0}
dove $\mathbf{0} \in \mathbb{R}^{m \times n_\text{neurons}}$ è una matrice di zeri.
Important
Questa struttura consente, come verrà discusso nelle sezioni successive, una derivazione sistematica e graduale dei gradienti rispetto ai parametri condivisi , , , che costituisce il nucleo del meccanismo BPTT.
Derivazione del gradiente: Backpropagation Through Time
Derivazione della BPTT: ritorno alla singola sequenza
Nella fase di forward è stata illustrata sia la formulazione per singolo campione sia quella per mini‑batch usando, in quest’ultimo scenario, matrici quali e , dove ogni riga rappresenta una diversa sequenza.
Tuttavia, durante la derivazione della Backpropagation Through Time (BPTT), la trattazione si concentra su una singola sequenza: i vettori , e sono intesi come elementi individuali (non matrici), e i gradienti vengono espressi come prodotti tra vettori.
Questo passaggio semplifica la notazione e l’intuizione analitica. La generalizzazione al mini-batch si ottiene infine sommando (o mediando) i gradienti calcolati sulle singole sequenze.
Per poter applicare l’algoritmo di Backpropagation Through Time (BPTT) e addestrare una rete neurale ricorrente (RNN), è necessario innanzitutto definire la funzione di loss complessiva sull’intera sequenza temporale:
dove:
- è il vettore one-hot contenente la classe corretta al tempo
- rappresenta la distribuzione predetta dal modello.
🧮 Cross-Entropy Multiclasse: somma implicita sulle classi
Nella formulazione:
la somma sulle classi è implicita nel prodotto scalare tra:
- : un vettore one-hot che codifica la classe corretta;
- : il vettore dei logaritmi delle probabilità predette dal softmax.
Tale prodotto scalare si espande come:
Ma essendo one-hot, solo una componente è pari a 1, tutte le altre sono nulle.
Di conseguenza:ovvero, si prende solo il logaritmo della probabilità predetta per la classe corretta.
📌 Questa notazione è compatta e molto usata in letteratura e nei framework (e.g.
nn.CrossEntropyLossdi PyTorch).
Calcolo gradiente rispetto a e
Dato che la matrice di pesi è condivisa lungo la sequenza temporale, il gradiente rispetto a tale parametro si ottiene come somma dei contributi per ciascun istante temporale:
dove:
- il simbolo indica il prodotto esterno tra vettori colonna
- per la derivata della funzione di loss rispetto alla funzione softmax si veda la relativa dimostrazione. Inoltre, si ha che , poiché .
Analogamente, il gradiente rispetto al bias del layer di output è:
Questi risultati discendono dalla derivazione nota del gradiente della cross-entropy combinata con la softmax.
Gradiente rispetto a : dipendenza ricorsiva
Si consideri la loss locale associata al passo temporale , indicata con:
dove:
- è il vettore one-hot della classe target
- è la distribuzione predetta dal modello al tempo , calcolata tramite softmax.
Si procede ora con l’analisi dettagliata necessaria per derivare il gradiente della funzione di loss rispetto alla matrice dei pesi ricorrenti , considerando inizialmente il singolo intervallo temporale (slice temporale) che va da a , ovvero il passaggio:
Al passo , il gradiente della loss locale rispetto a si esprime inizialmente come:
Tale espressione considera solo un singolo passo temporale (). Tuttavia, occorre osservare che lo stato nascosto dipende ricorsivamente anche dallo stato , secondo la formulazione ricorrente:
Pertanto, al time-step , si può ulteriormente espandere la derivata parziale di rispetto a come segue:
Si deduce quindi che, al tempo , il gradiente può essere calcolato propagando all’indietro l’informazione attraverso i passi temporali precedenti, ossia da fino a , in modo da ottenere il gradiente complessivo rispetto a , ossia:
Note
Il termine è esso stesso una catena di derivate.
Ad esempio, per e , si ha:
Applicazione della chain rule multivariata
La transizione dalla forma:
alla forma espansa:
è giustificata dall’applicazione della regola della derivata totale (o chain rule multivariata), valida quando una variabile (in questo caso ) influenza la loss attraverso più cammini indiretti.
Ogni termine dell’indice nella sommatoria rappresenta un percorso causale indiretto tra e , tramite uno specifico stato nascosto che ha contribuito a costruire .
In altri termini, anche se la loss è una funzione scalare, la sua dipendenza da avviene tramite funzioni vettoriali intermedie (gli stati ), e per questo si rende necessaria la versione multivariata della chain rule.
Inoltre, poiché si sta derivando una funzione vettoriale rispetto a un vettore, il risultato è una matrice Jacobiana, i cui elementi sono le derivate parziali calcolate punto per punto.
Pertanto l’espressione per il gradiente può essere riscritta come segue:
dove:
Tale termine prodotto rappresenta il gradiente accumulato lungo la sequenza temporale dal passo temporale fino al passo , delle matrici Jacobiane della funzione ricorrente che definisce l’evoluzione dello stato nascosto.
Note
Ciascun termine è una matrice Jacobiana, ottenuta derivando la funzione di attivazione (e.g. tanh) applicata allo stato nascosto. Poiché ha derivate limitate in modulo da , la norma 2 (o spettro-norma) di ciascuna Jacobiana è a sua volta limitata superiormente da 1. Questo fenomeno giustifica l’intuizione per cui i gradienti possono degradarsi nel tempo, causando il cosiddetto problema del gradiente evanescente (vanishing gradient).
Il gradiente complessivo rispetto a , ottenuto aggregando su tutti i passi temporali, è dunque:
Calcolo Gradiente rispetto a
Si procede ora alla derivazione del gradiente rispetto alla matrice dei pesi . In modo analogo al caso precedente, si considera il passo temporale , il quale riceve un contributo diretto unicamente dall’input . Il gradiente della loss al passo rispetto a si esprime quindi come:
Tuttavia, poiché e contribuiscono entrambi alla determinazione di , è necessario propagare il gradiente anche rispetto a .
Considerando tale contributo, il gradiente può essere ulteriormente espanso come segue:
Sommando tutti i contributi a partire dal tempo fino all’inizio della sequenza () tramite backpropagation, si ottiene il gradiente al passo temporale :
Infine, derivando rispetto a lungo l’intera sequenza temporale, si ottiene:
Note
Anche in questo caso, nel termine
\frac{\partial \mathbf{h}_{t+1}}{\partial \mathbf{h}_k}
è insita una catena di derivate, esattamente come nel caso della derivazione rispetto a
Conclusione
Questa formulazione esplicita del gradiente rispetto ai pesi e costituisce il nucleo del meccanismo BPTT e consente la retropropagazione del segnale d’errore nel tempo. Come sarà discusso nelle sezioni seguenti, tale meccanismo può essere affetto da problemi di stabilità numerica, che hanno motivato l’introduzione di varianti strutturali come LSTM e GRU.