The soft-attention pipeline was introduced as a fix for a specific problem in recurrent sequence modelling: how to summarize a variable-length sequence of hidden states into a fixed-shape vector with content-dependent weights. The mechanism itself, a learned weighted combination of a set of feature vectors, is structurally far more general than the use case that motivated it.
This note surveys four representative applications of the same three-step pipeline (score, normalize, combine) outside of recurrent sequence summarization, then states the unifying abstraction.
The pattern
Whenever a model has to combine a set or sequence of feature vectors into a fixed-shape representation, with mixing weights that should depend on the actual content of those vectors and on the downstream task, soft attention is essentially the only option that is differentiable, parameter-efficient, and architecturally agnostic to the size of the set. The applications below differ in what the set is (channels, spatial locations, graph nodes, image regions) and how the score is computed, but the three-step pipeline is unchanged.
Channel attention in CNNs: Squeeze-and-Excitation
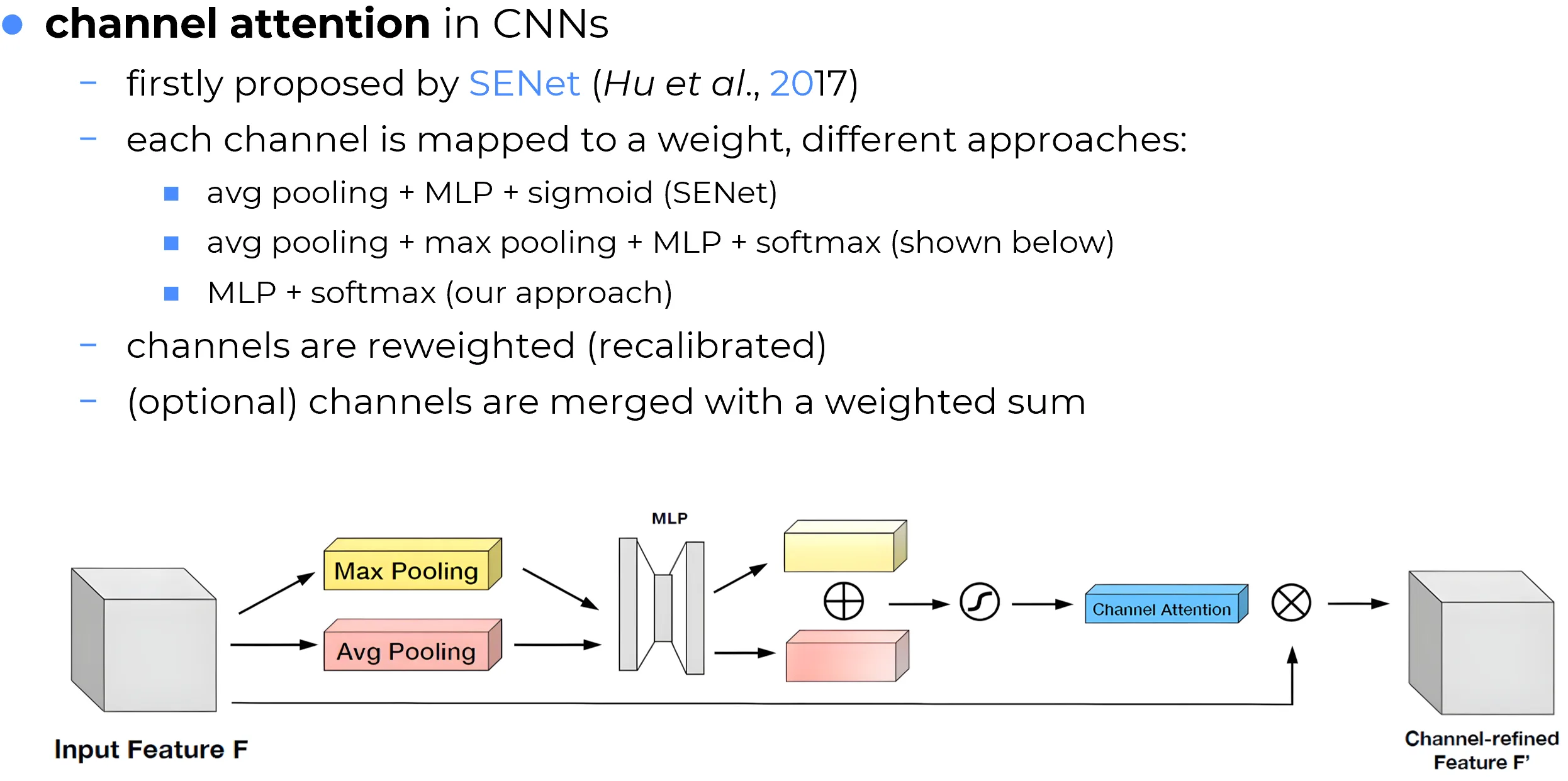
A convolutional feature map has channels, each one a 2-D map of spatial activations. The standard implicit assumption of a convolutional block is that all channels are equally important: the next layer sees the full unchanged. Empirically this is a poor assumption. For any given input, some channels carry information highly relevant to the task while others are nearly silent or actively distracting.
Squeeze-and-Excitation (Hu, Shen and Sun, 2018) is the soft-attention pipeline applied to channels rather than to sequence positions. The “set” being attended over is the set of channels; each channel is summarized into a single scalar by global average pooling, the scalars are passed through a small bottleneck MLP to produce a per-channel weight, and the weights rescale the channels.
The three steps map exactly onto the soft-attention pipeline:
- Score. Each channel is reduced to a scalar by global average pooling over : The resulting vector passes through a small 2-layer MLP with bottleneck width (typical reduction ratio ), producing per-channel scores.
- Normalize. The MLP’s output is squashed by a sigmoid, not softmax, giving independent per-channel weights that do not sum to 1. This is a deliberate departure from the soft-attention default: the channels are not competing for a fixed attention budget, they are independently gated.
- Combine. Each channel of is rescaled by its weight, giving the recalibrated feature map .
Soft attention with sigmoid instead of softmax
The softmax in the canonical soft-attention pipeline enforces , which is appropriate when the model has a fixed budget of attention to spend across positions. Channel attention drops this constraint by replacing softmax with sigmoid: each channel decides independently whether to amplify or attenuate, and the network can in principle enhance many channels at once or suppress them all. The resulting operation is best thought of as a learned per-channel gate, structurally analogous to the gates of an LSTM.
Squeeze-and-Excitation became a standard block in image classification CNNs and was a component of the winning entry in the ILSVRC 2017 competition. The cost is small (an additional MLP per block, with parameter count ); the accuracy gain is consistent across architectures.
Spatial attention in CNNs
A complementary construction attends over spatial locations rather than channels. The set being attended over is the grid of spatial positions; the score is computed per location, often by pooling across channels and passing the result through a small convolution; the resulting 2-D attention map rescales the activations spatially.
The combination of spatial and channel attention into a single sequential block is the Convolutional Block Attention Module (CBAM, Woo et al., 2018), which applies channel attention first and spatial attention second:
where is a channel attention map of shape and is a spatial attention map of shape , both produced by small soft-attention-style sub-networks.
The architectural intent in both cases is the same as in NLP soft attention: the convolutional feature map contains far more information than the downstream task needs, and a small learned gating mechanism can focus the downstream computation on the relevant subset.
Image-captioning attention: “Show, Attend and Tell”
The first major application of soft attention outside of recurrent sequence summarization, and arguably the work that introduced the mechanism to a wide audience, is Show, Attend and Tell (Xu et al., 2015). The task is image captioning: given an image, generate a natural-language description.
The architecture is an encoder-decoder. A CNN encoder extracts a grid of spatial feature vectors from the image (one per spatial location, with ). A recurrent decoder generates the caption one word at a time. At each decoding step , the decoder produces a query (its current hidden state ) and uses soft attention to select which spatial regions of the image to look at when generating the next word:
The context vector is mixed into the decoder’s input for step , and the next word is sampled. The attention distribution over the spatial locations is interpretable as a heatmap on the image: when the decoder produces the word “frisbee”, concentrates on the spatial region containing the frisbee; when it produces “dog”, it shifts to the region containing the dog.
The architectural shape that became Transformers
The construction above is query-conditional soft attention: the score depends on both the query and the key . This is the architectural shape that was eventually generalized into the modern Transformer attention block, with three crucial additions:
- the query, key, and value are produced by separate learned projections of the input;
- the score is computed by scaled dot product rather than by a learned MLP;
- the mechanism is self-attention (the queries come from the same sequence as the keys and values) rather than encoder-decoder cross-attention.
The “Show, Attend and Tell” model is, in retrospect, the immediate ancestor of the cross-attention block in encoder-decoder Transformers, three years before “Attention is all you need”. The soft-attention pipeline introduced in the previous note is the same idea stripped of the query.
Graph attention networks (GAT)
In a graph neural network, each node aggregates information from its neighbors to compute its updated representation. The original Graph Convolutional Network (Kipf and Welling, 2017) uses a uniform average over the neighbors, weighted by the inverse square root of the node degrees. This is the graph analogue of the rejected averaging fix in sentiment analysis: every neighbor contributes equally, regardless of how informative it is for the task.
The Graph Attention Network (Veličković et al., 2018) replaces the uniform average with soft attention over neighbors:
The set being attended over is , the neighborhood of node . The score depends on both the query node and the neighbor ; the softmax normalizes over neighbors; the context is a learned weighted aggregation that downweights uninformative neighbors. GAT consistently outperforms its uniform-averaging counterpart on node classification benchmarks, particularly on graphs where neighborhoods are large and heterogeneous.
The same pattern reappears in many subsequent graph models. As in the image case, the attention map over neighbors is directly interpretable as a “where is this node looking” diagnostic.
A handful of other settings
A few additional applications, mentioned briefly to indicate the breadth of the pattern.
- Pointer Networks (Vinyals, Fortunato and Jaitly, 2015) use attention scores as outputs: the model “points” to a position in the input by emitting its attention distribution, rather than emitting a token from a fixed vocabulary. This is the natural construction for tasks where the output is a permutation or selection over the input (e.g., the travelling-salesman problem, convex-hull computation, extractive summarization).
- Memory Networks (Sukhbaatar, Szlam, Weston and Fergus, 2015) maintain an external memory of fixed slots and use soft attention to read from it: the query is the current state of the controller, the keys are the memory slot identifiers, the values are the contents. This is essentially the construction the modern Transformer’s key-value attention generalizes.
- Neural Turing Machines (Graves, Wayne and Danihelka, 2014) preceded memory networks and used soft attention to both read from and write to a differentiable external memory. The construction is mathematically elaborate but conceptually the same three-step pipeline.
- Multi-instance learning uses attention to aggregate predictions across the instances of a bag in weakly-supervised settings, with the attention weights identifying which instances drove the bag-level prediction (Ilse, Tomczak and Welling, 2018).
The unifying abstraction
The soft-attention building block
Soft attention is the differentiable, learned, content-dependent generalization of “aggregate a set of feature vectors into a single one”. Any time a model faces such an aggregation problem, soft attention is the architectural default, parameterized by:
- the set being aggregated (sequence positions, channels, spatial locations, neighbours, memory slots);
- the score function (linear projection, MLP, dot product, learned similarity, possibly query-conditional);
- the normalization (softmax for competitive allocation, sigmoid for independent gating);
- the combination (weighted sum, weighted concatenation, gated multiplication).
Modern attention-based architectures are, in essence, soft attention applied recursively and at scale: many heads, many layers, query-conditional scoring, learned projections for keys and values. None of these refinements changes the underlying logic introduced in the previous note; they sharpen and parallelize it.
Attention is a learned kernel smoother
Stripped to its arithmetic, the pipeline is a classical object. With scores and weights , the context vector is a kernel-weighted average of the , the softmax acting as a similarity kernel. This is exactly Nadaraya-Watson kernel regression (1964), the textbook non-parametric estimator that predicts a target as a similarity-weighted average of stored outputs. Query-conditional attention, , is Nadaraya-Watson with a learned, query-dependent kernel and learned values. This reading explains why attention generalises so freely across the settings above: kernel smoothing is defined for any set of points carrying a notion of similarity, which is precisely why the same three steps work over tokens, channels, pixels, and graph nodes. The modern contribution is not the averaging, which is sixty years old, but making the kernel and the values learned and differentiable.
What comes next
The soft-attention pipeline has now been seen as both a fix for a specific failure mode of recurrent sequence summarization and as a generic aggregation primitive that recurs across vision, graphs, and external memory. The natural next question is what happens when the architectural reliance on a recurrent encoder is dropped entirely: when the only mechanism the model uses to mix information across positions is attention. The answer is the Transformer, and it is the subject of the next module.