The architectural prescription from Vanilla RNNs limitations (additive memory plus a learned forget gate) is built here in full, one piece at a time, in the order in which information flows through the LSTM cell.
- LSTM Layer overview: the two states (, ), the four inner FC layers, and the notation used throughout the subsection.
- Cell state: the carry line as a temporal skip connection, and the canonical definition of coordinate independence that makes its Jacobian diagonal.
- Forget gate: the gating of by , the choice of sigmoid, and the consequential forget-bias initialization.
- Input gate: the candidate update (with tanh) and the input mask (with sigmoid), and why the what and how much of writing are split into two separate networks.
- Output gate: the read-out and the separation between what the cell stores () and what it says ().
- Putting all together: the complete forward pass, the mini-batch vectorization, the master dimensions table, the broadcasting audit, the parameter count, and the fused-weight matrix used by modern frameworks.
The gradient analysis of the assembled cell is treated separately in Gradient in LSTM, one level up.
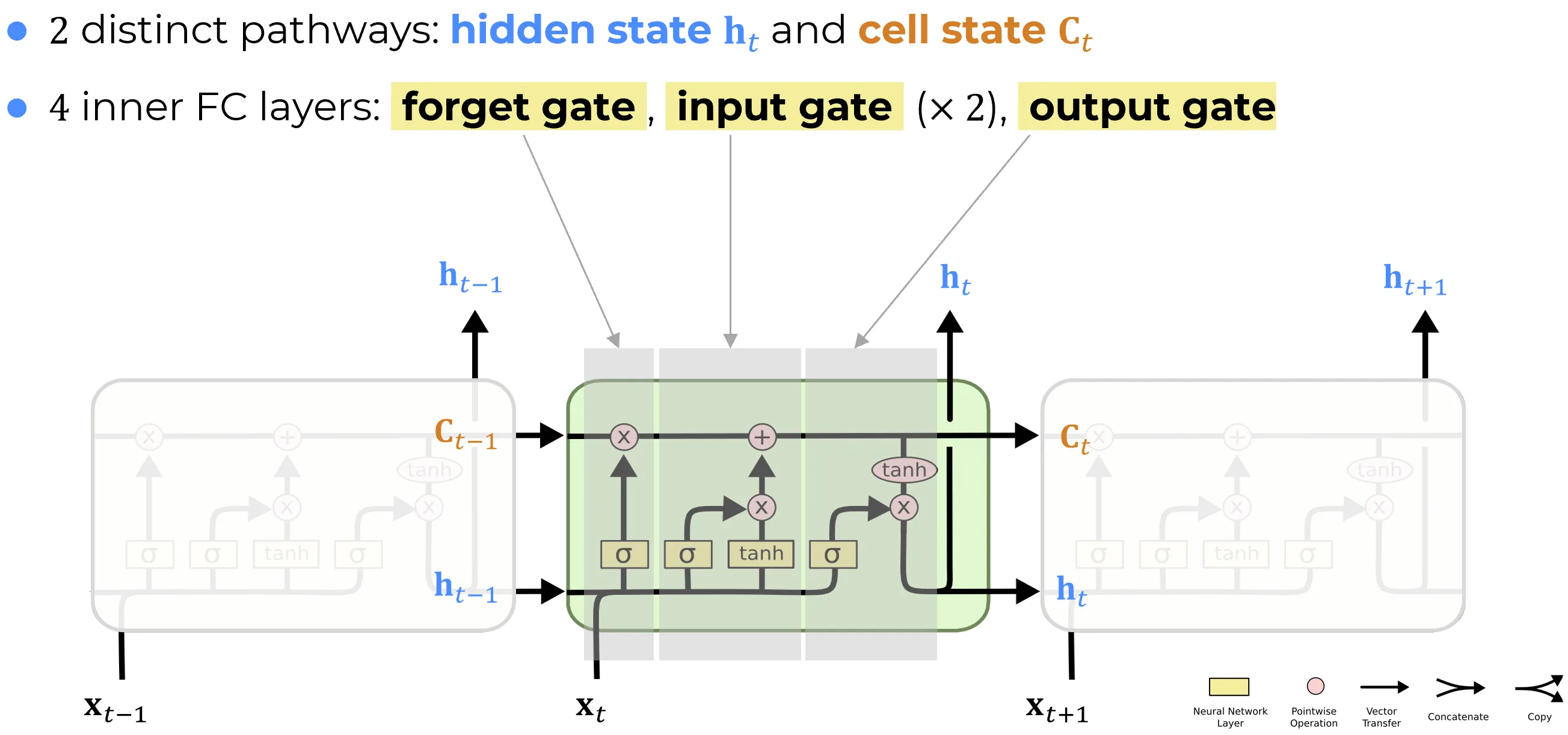
The diagnosis of Vanilla RNNs limitations ends with a single architectural prescription: take the recurrent matrix off the carry path and replace overwriting with additive update through a learned gate. The LSTM cell is what that prescription looks like when written out in full. This note fixes the notation and the high-level reading of the diagram above; the gate-by-gate derivation begins with the cell state.
Notation used in this section
Throughout the LSTM layer notes:
- lowercase bold denotes a vector for a single example ();
- uppercase bold denotes the corresponding mini-batch matrix, with one column per example (), or a learned weight matrix ().
The diagrams in this section label the cell state with an uppercase symbol because they depict a single time step in isolation; the equations always follow the convention above.
The two sizes: and
Two integers fix the shape of everything in this section.
- is the number of features in each input vector : the dimensionality of one element of the sequence, such as the embedding size of a token or the channel count of a frame. It is set by the data.
- is the number of units in one LSTM layer, and it is a design choice. A unit carries one coordinate of the cell state and one coordinate of the hidden state; it is the recurrent analogue of a single neuron in a fully connected layer. There are of them, so every vector the cell computes at a step, , has one entry per unit and therefore lives in , while only the input lives in .
The name is therefore deliberate. The units sit side by side and all read the same input pair ; the original Hochreiter and Schmidhuber paper calls one such unit an LSTM block. To process a sequence the layer is unrolled over the time steps, reusing the same units at each one. In PyTorch this number is the constructor argument
hidden_size.
Two states, two roles
At every step an LSTM cell receives and produces . Unlike a vanilla RNN, which carries a single hidden vector forward, an LSTM carries two:
- the cell state , the orange label, which is the long-term memory of the cell;
- the hidden state , the blue label, which is the cell’s externally visible output.
Both are passed to the next time step; only is exposed to the rest of the network (and to any prediction head built on top of the layer).
Why two states and not one
The two paths are not redundant: they obey different constraints, and the LSTM works because those constraints are incompatible inside a single vector.
- must live in an unconstrained, additive space so that gradient can flow back through it unchanged across long gaps. This is the highway that fixes the vanishing gradient. Its components are not bounded.
- must be bounded and selective: it is fed back into the gate computations at the next step (through sigmoids and a tanh), and it is the signal that downstream layers consume. A bounded, task-focused output is what makes both the gating logic and the prediction head well-behaved.
Squeezing both jobs into a single hidden vector is exactly what a vanilla RNN attempts, and exactly why it cannot preserve information: the same coordinate would have to be at once a long-lived unbounded register and a short-lived bounded summary. Separating the two is the architectural move.
The four inner FC layers
The diagram contains four small fully connected layers, each one a familiar affine map followed by a pointwise nonlinearity. They are not four independent modules: each consumes the same input pair and produces a vector in .
- Forget gate . Decides, component by component, what fraction of to keep. Detailed in Forget gate.
- Input gate . Decides, component by component, how much of the new candidate to write. Detailed in Input gate.
- Candidate update . Proposes a signed content vector to add to memory. Also covered in Input gate.
- Output gate . Decides, component by component, what part of the freshly updated memory to expose as . Detailed in Output gate.
The cell state update, anticipated in the limitations note and derived properly in Cell state, is
and the hidden state is read out from it as
Dimensions used in this note
symbol role shape current input hidden state cell state gates candidate update input-to-hidden weights, hidden-to-hidden weights bias
Three heads on a tape
Read the four maps as the three heads of a learned tape recorder operating on the memory :
- is an erase head, selecting which entries of the tape to clear before writing.
- together act as a write head: is the content to write, is the per-position write mask.
- is a read head, selecting which entries of the tape to expose as .
This is not just a metaphor: it is exactly the decomposition that makes preservation a learned decision rather than a knife-edge of the recurrent spectrum. Erasure, writing, and reading are independent and gated at the per-coordinate level.
Shared input, separate transforms
All four maps share the same input . The diagram makes this explicit: the blue line carrying and the line carrying both fan out into all four FC blocks. Each block, however, owns its own weight matrices and bias:
The shared input is what gives the LSTM its coherence: at every step, all four decisions are conditioned on the same view of the world, namely the current input and the previous hidden summary. The cell does not separately gather “context for forgetting” and “context for writing”; it gathers context once, and routes it through four learned linear readouts.
The 4× parameter cost is not a bug
A vanilla RNN of width has one affine map of size . An LSTM has four. The parameter count is therefore roughly larger at the same width.
This factor of four is the price of preservation. Three of the four maps exist exclusively to make the cell state behave as an unbiased additive register: one to erase, one to gate writes, one to gate reads. Only the candidate plays the role of “what the vanilla RNN was already trying to compute”. Trading parameters for stable long-range gradient flow is the explicit bargain of the architecture, and it is what GRUs later try to renegotiate.
Unrolling and parameter sharing
The figure shows a single time step. As in the vanilla RNN, the cell is unrolled in time into as many copies as the sequence requires, and every copy shares the exact same parameters . The initial states are conventionally fixed:
Training proceeds via Backpropagation Through Time on this unrolled graph, in any of its practical variants. The crucial property that motivated the whole construction, namely that gradient flows back through with Jacobian rather than through a product of recurrent matrices, is analyzed in Gradient in LSTM.
How to read the rest of this section
The remaining notes build the cell one piece at a time, in the order in which information flows through the diagram:
- Cell state: the additive memory line and its interpretation as a temporal skip connection.
- Forget gate: the gating of by .
- Input gate: the candidate and the input mask .
- Output gate: the read-out .
- Putting all together: the complete forward pass and the mini-batch vectorization.